 +
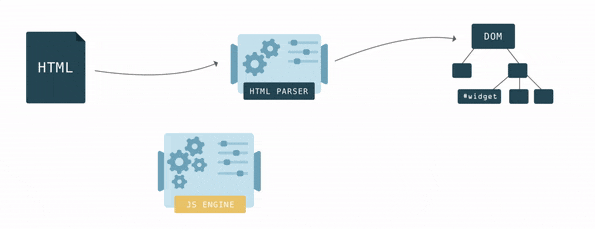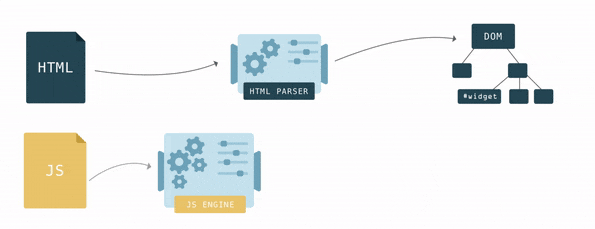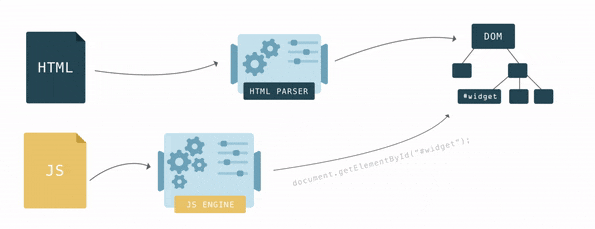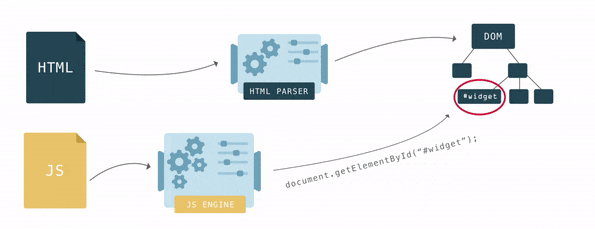
+浏览器一点一点地构建 *DOM*。一旦第一块代码进来,它就会开始解析 *HTML*,将节点添加到树结构中。
+
+
+
+构建出来的 *DOM* 对象,实际上有 *2* 个作用:
+
+- *HTML* 文档的结构以对象的方式体现出来,形成我们常说的 *DOM* 树
+
+- 作为外界的接口供外界使用,例如 *JavaScript*。当我们调用诸如 *document.getElementById* 的方法时,返回的元素是一个 *DOM* 节点。每个 *DOM* 节点都有许多可以用来访问和更改它的函数,用户看到的内容也会相应地发生变化。
+
+
+
+
+
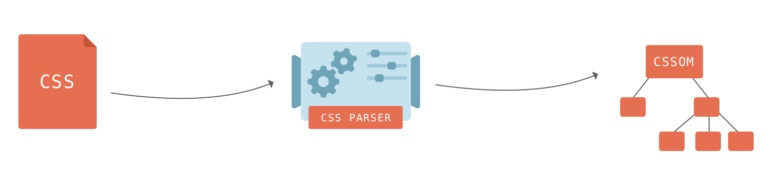
+*CSS* 样式会被映射为 *CSSOM*( *CSS* 对象模型),它和 *DOM* 很相似,但是针对的是 *CSS* 而不是 *HTML*。
+
+在构建 *CSSOM* 的时候,无法进行增量构建(不像构建 *DOM* 一样,解析到一个 *DOM* 节点就扔到 *DOM* 树结构里面),因为 *CSS* 规则是可以相互覆盖的,浏览器引擎需要经过复杂的计算才能弄清楚 *CSS* 代码如何应用于 *DOM*。
+
+
+
+当浏览器正在构建 *DOM* 时,如果它遇到 *HTML* 中的 `` 标记,它必须立即执行它。如果脚本是外部的,则必须先下载脚本。
+
+过去,为了执行脚本,必须暂停解析。解析会在 *JavaScript* 引擎执行完脚本中的代码后再次启动。
+
+
+
+浏览器一点一点地构建 *DOM*。一旦第一块代码进来,它就会开始解析 *HTML*,将节点添加到树结构中。
+
+
+
+构建出来的 *DOM* 对象,实际上有 *2* 个作用:
+
+- *HTML* 文档的结构以对象的方式体现出来,形成我们常说的 *DOM* 树
+
+- 作为外界的接口供外界使用,例如 *JavaScript*。当我们调用诸如 *document.getElementById* 的方法时,返回的元素是一个 *DOM* 节点。每个 *DOM* 节点都有许多可以用来访问和更改它的函数,用户看到的内容也会相应地发生变化。
+
+
+
+
+
+*CSS* 样式会被映射为 *CSSOM*( *CSS* 对象模型),它和 *DOM* 很相似,但是针对的是 *CSS* 而不是 *HTML*。
+
+在构建 *CSSOM* 的时候,无法进行增量构建(不像构建 *DOM* 一样,解析到一个 *DOM* 节点就扔到 *DOM* 树结构里面),因为 *CSS* 规则是可以相互覆盖的,浏览器引擎需要经过复杂的计算才能弄清楚 *CSS* 代码如何应用于 *DOM*。
+
+
+
+当浏览器正在构建 *DOM* 时,如果它遇到 *HTML* 中的 `` 标记,它必须立即执行它。如果脚本是外部的,则必须先下载脚本。
+
+过去,为了执行脚本,必须暂停解析。解析会在 *JavaScript* 引擎执行完脚本中的代码后再次启动。
+
+ +
+
+
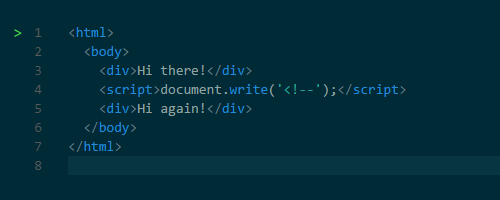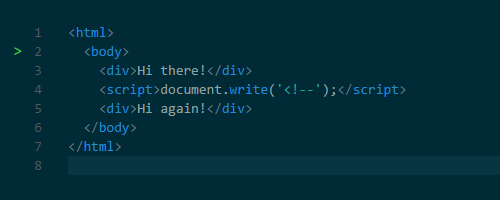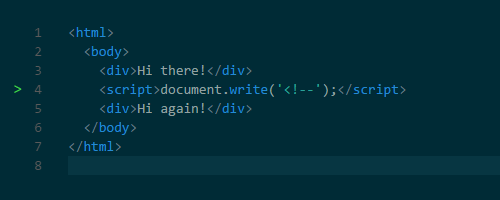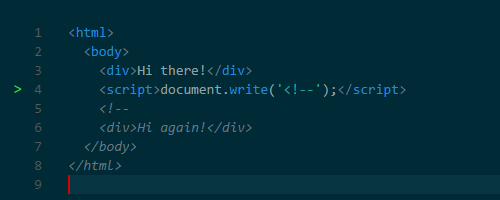
+为什么解析必须停止呢?
+
+原因很简单,这是因为 *Javascript* 脚本可以改变 *HTML* 以及根据 *HTML* 生成的 *DOM* 树结构。例如,脚本可以通过使用 *document.createElement( )* 来添加节点从而更改 *DOM* 结构。
+
+
+
+这也是为什么我们建议将 *script* 标签写在 *body* 元素结束标签前面的原因。
+
+```html
+
+
+
+```
+
+*defer* 表示加载后续文档元素的过程将和 *script.js* 的加载并行进行(异步),但是 *script.js* 的执行要在所有元素解析完成之后,*DOMContentLoaded* 事件触发之前完成。也就是说,下载 *JS* 文件的时候不会阻塞 *DOM* 树的构建,然后等待 *DOM* 树构建完毕后再执行此 *JS* 文件。
+
+```html
+
+```
+
+具体加载瀑布图如下图所示:
+
+
+
+
+
+为什么解析必须停止呢?
+
+原因很简单,这是因为 *Javascript* 脚本可以改变 *HTML* 以及根据 *HTML* 生成的 *DOM* 树结构。例如,脚本可以通过使用 *document.createElement( )* 来添加节点从而更改 *DOM* 结构。
+
+
+
+这也是为什么我们建议将 *script* 标签写在 *body* 元素结束标签前面的原因。
+
+```html
+
+
+
+```
+
+*defer* 表示加载后续文档元素的过程将和 *script.js* 的加载并行进行(异步),但是 *script.js* 的执行要在所有元素解析完成之后,*DOMContentLoaded* 事件触发之前完成。也就是说,下载 *JS* 文件的时候不会阻塞 *DOM* 树的构建,然后等待 *DOM* 树构建完毕后再执行此 *JS* 文件。
+
+```html
+
+```
+
+具体加载瀑布图如下图所示:
+
+ +
+
+
+## *preload*
+
+*preload* 顾名思义就是一种预加载的方式,它通过声明向浏览器声明一个需要提前加载的资源,当资源真正被使用的时候立即执行,就无需等待网络的消耗。
+
+```html
+
+
+
+
+
+```
+
+在上面的代码中,会先加载 *style1.css* 和 *main1.js* 文件(但不会生效),在随后的页面渲染中,一旦需要使用它们,它们就会立即可用。
+
+可以使用 *as* 来指定将要预加载的内容类型。
+
+
+
+
+
+*preload* 指令的一些优点如下:
+
+- 允许浏览器设置资源优先级,从而允许 *Web* 开发人员优化某些资源的交付。
+
+- 使浏览器能够确定资源类型,因此它可以判断将来是否可以重用相同的资源。
+
+- 浏览器可以通过引用 *as* 属性中定义的内容来确定请求是否符合内容安全策略。
+
+- 浏览器可以根据资源类型发送合适的 *Accept* 头(例如:*image/webp* )
+
+
+
+## *prefetch*
+
+*prefetch* 是一种利用浏览器的空闲时间加载页面将来可能用到的资源的一种机制,通常可以用于加载非首页的其他页面所需要的资源,以便加快后续页面的首屏速度。
+
+*prefetch* 加载的资源可以获取非当前页面所需要的资源,并且将其放入缓存至少 *5* 分钟(无论资源是否可以缓存)。并且,当页面跳转时,未完成的 *prefetch* 请求不会被中断;
+
+它的用法跟 *preload* 是一样的:
+
+```html
+
+```
+
+
+
+***DNS prefetching***
+
+*DNS prefetching* 允许浏览器在用户浏览时在后台对页面执行 *DNS* 查找。这最大限度地减少了延迟,因为一旦用户单击链接就已经进行了 *DNS* 查找。
+
+通过将 *rel="dns-prefetch"* 标记添加到链接属性,可以将 *DNS prefetching* 添加到特定 *URL*。建议在诸如 *Web* 字体、*CDN* 之类的东西上使用它。
+
+```html
+
+
+
+
+```
+
+
+
+## *prerender*
+
+*prerender* 与 *prefetch* 非常相似,*prerender* 同样也是会收集用户接下来可能会用到的资源。
+
+不同之处在于 *prerender* 实际上是在后台渲染整个页面。
+
+```html
+
+```
+
+
+
+## *preconnect*
+
+我们要讨论的最后一个资源提示是 *preconnect*。
+
+*preconnect* 指令允许浏览器在 *HTTP* 请求实际发送到服务器之前设置早期连接。
+
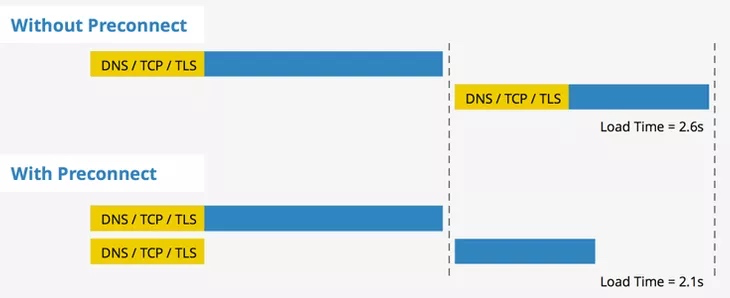
+我们知道,浏览器要建立一个连接,一般需要经过 *DNS* 查找,*TCP* 三次握手和 *TLS* 协商(如果是 *https* 的话),这些过程都是需要相当的耗时的。所以 *preconnet*,就是一项使浏览器能够预先建立一个连接,等真正需要加载资源的时候就能够直接请求了。
+
+
+
+
+
+以下是为 *CDN URL* 启用 *preconnect* 的示例。
+
+```html
+
+```
+
+在上面的代码中,浏览器会进行以下步骤:
+
+- 解释 *href* 的属性值,判断是否是合法的 *URL*。如果是合法的 *URL*,然后继续判断 *URL* 的协议是否是 *http* 或者 *https*,如果不是合法的 *URL*,则结束处理。
+- 如果当前页面 *host* 不同于 *href* 属性中的 *host*,那么将不会带上 *cookie*,如果希望带上 *cookie* 等信息,可以加上 *crossorign* 属性。
+
+
+
+-------
+
+
+
+-*EOF*-
diff --git a/03. 浏览器的组成部分/浏览器的组成部分.md b/03. 浏览器的组成部分/浏览器的组成部分.md
new file mode 100644
index 0000000..1e9003b
--- /dev/null
+++ b/03. 浏览器的组成部分/浏览器的组成部分.md
@@ -0,0 +1,217 @@
+# 浏览器的组成部分
+
+
+
+什么是浏览器?
+
+*Web* 浏览器简称为浏览器,是一种用于访问互联网上信息的应用软件。浏览器的主要功能是从服务器检索 *Web* 资源并将其显示在 *Web* 浏览器窗口中。
+
+*Web* 资源通常是 *HTML* 文档,但也可能是 *PDF*、图像、音频、视频或其他类型的内容。资源的位置是通过使用 *URI*(统一资源标识符)指定的。
+
+浏览器包含结构良好的组件,这些组件执行一系列任务让浏览器窗口能显示 *Web* 资源。
+
+本文我们就来聊一聊关于浏览器的组成部分。
+
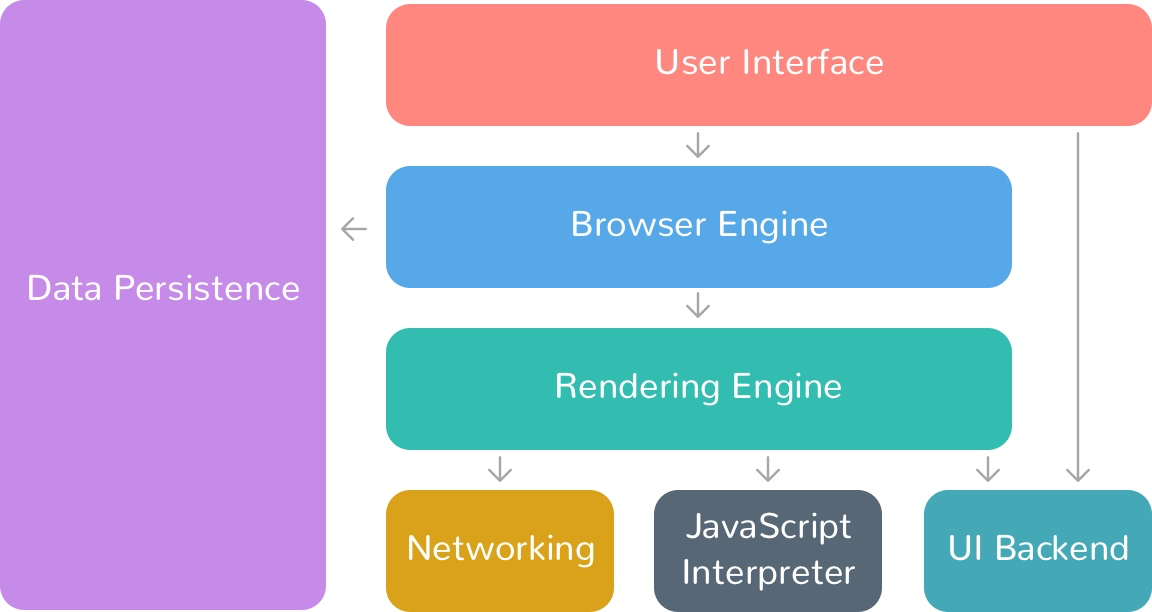
+下图是关于浏览器的架构图:
+
+
+
+
+
+一个 *Web* 浏览器中,主要组件有:
+
+- 用户界面(*user interface*)
+
+- 浏览器引擎(*browser engine*)
+
+- 渲染引擎(*rendering engine*)
+
+- 网络(*networking*)
+
+- *JS* 解释器(*JavaScript interpreter*)
+
+- 用户界面后端(*UI backend*)
+
+- 数据存储(*data storage*)
+
+下面我们来具体看一下每一个部分的作用。
+
+
+
+## 用户界面(*user interface*)
+
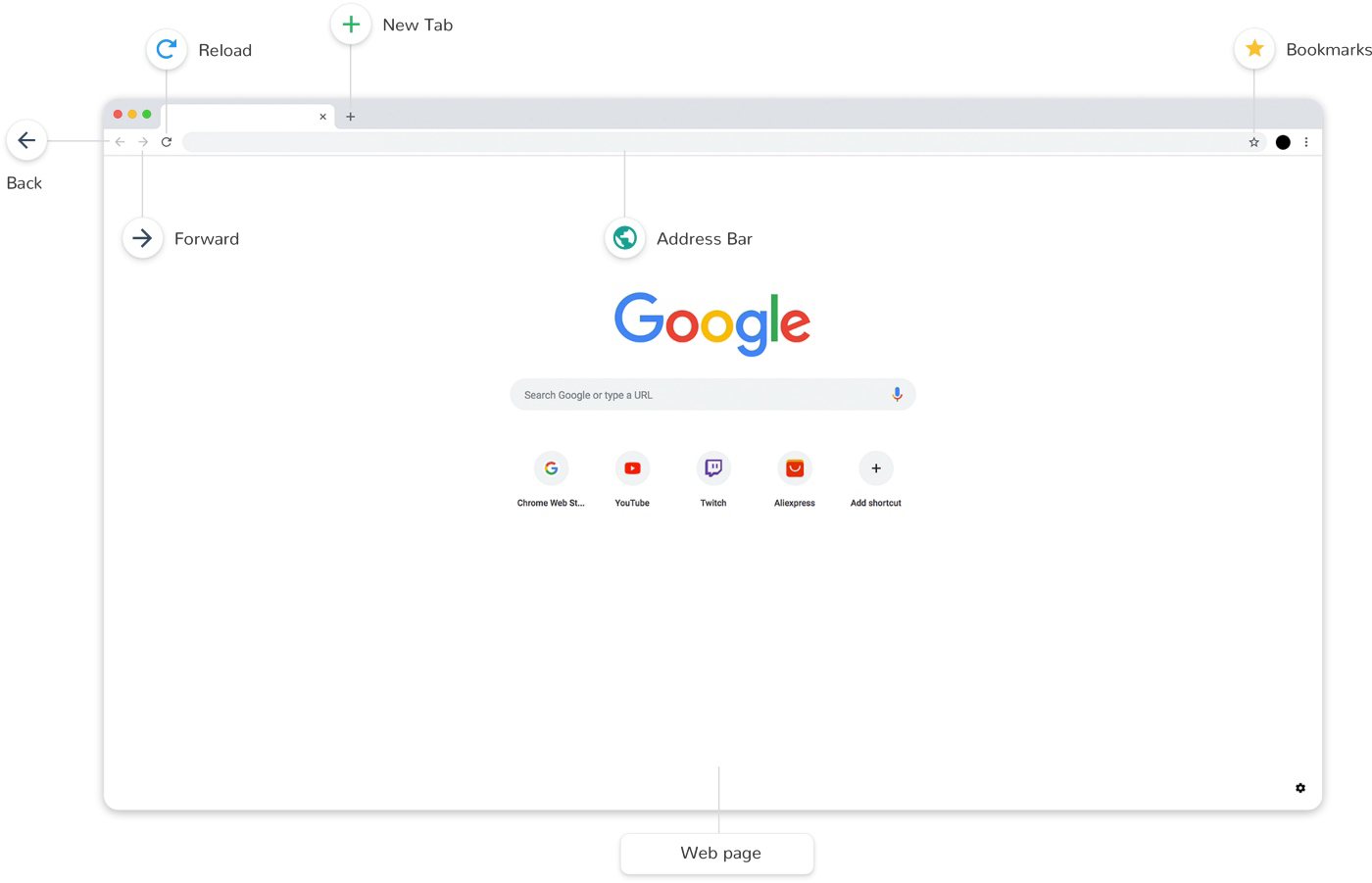
+用户界面用于呈现浏览器窗口部件,比如地址栏、前进后退按钮、书签、顶部菜单等。
+
+如下图所示:
+
+
+
+## 浏览器引擎(*browser engine*)
+
+它是 *UI* 和渲染引擎之间的桥梁。接收来自 *UI* 的输入,然后通过操纵渲染引擎将网页或者其他资源显示在浏览器中。
+
+
+
+## 渲染引擎(*rendering engine*)
+
+负责在浏览器窗口上显示请求的内容。例如,用户请求一个 *HTML* 页面,则它负责解析 *HTML* 文档和 *CSS*,并将解析和格式化的内容显示在屏幕上。我们平时说的浏览器内核就是指这部分。
+
+现代网络浏览器的渲染引擎:
+
+- *Firefox:Gecko Software*
+
+- *Safari:WebKit*
+
+- *Chrome、Opera* (*15* 版本之后):*Blink*
+
+- *Internet Explorer:Trident*
+
+在第一小节我们已经介绍过渲染引擎渲染页面的整体流程了,这里做一个简单的复习。
+
+为了在屏幕上绘制像素(第一次渲染),浏览器在从网络接收数据(*HTML、CSS、JavaScript*)后必须经过一系列称为关键渲染路径的过程/技术。这包括 *DOM*、*CSSOM*、渲染树、布局和绘画。
+
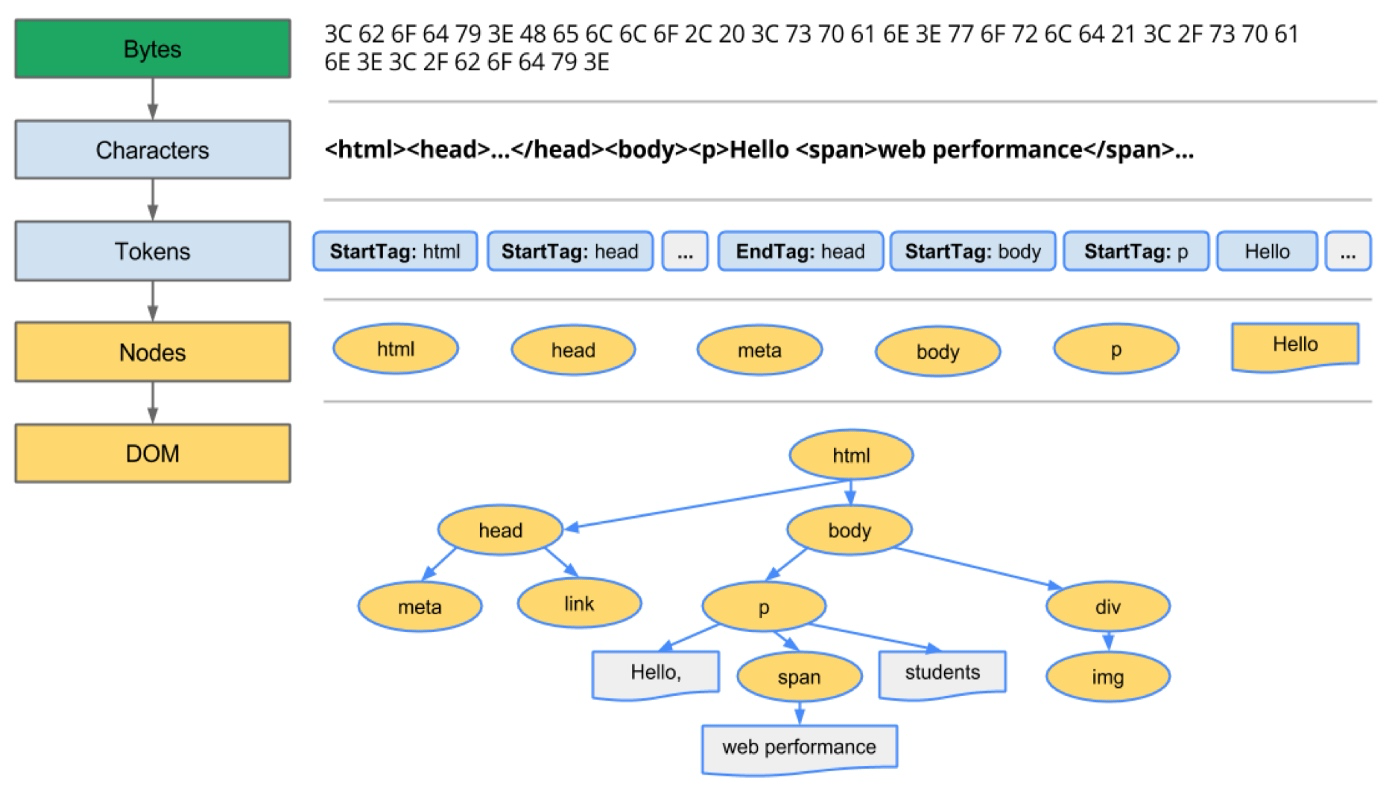
+### 从数据到 *DOM*
+
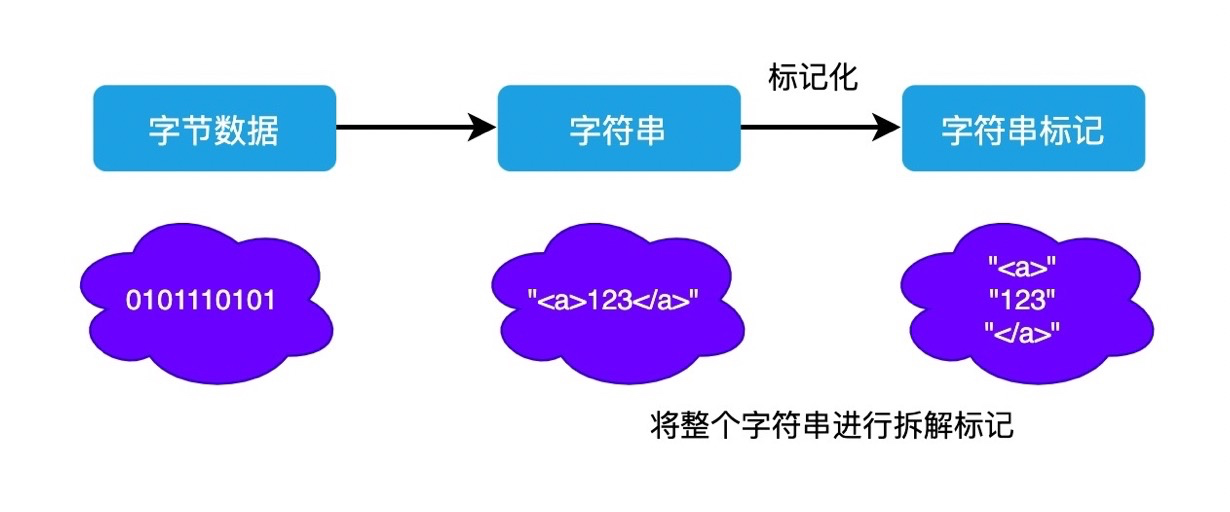
+来自网络层的请求内容以二进制流格式在渲染引擎中接收(通常为 *8kb* 块)。然后将原始字节转换为 *HTML* 文件的字符(基于字符编码)。
+
+然后将字符转换为标记。词法分析器执行词法分析,将输入分解为标记。在标记化期间,文件中的每个开始和结束标记都被考虑在内。它知道如何去除不相关的字符,如空格和换行符。然后解析器进行语法分析,通过分析文档结构,应用语言语法规则来构建解析树。
+
+解析过程是迭代的。它将向词法分析器询问新的标记,如果语言语法规则匹配,则该标记将被添加到解析树中。然后解析器将要求另一个令牌。如果没有规则匹配,解析器将在内部存储令牌并不断询问令牌,直到找到与所有内部存储的令牌匹配的规则。如果未找到规则,则解析器将引发异常。这意味着该文档无效并且包含语法错误。
+
+这些节点在称为 *DOM*(文档对象模型)的树数据结构中链接,该结构建立了父子关系、相邻兄弟关系。
+
+
+
+
+
+
+
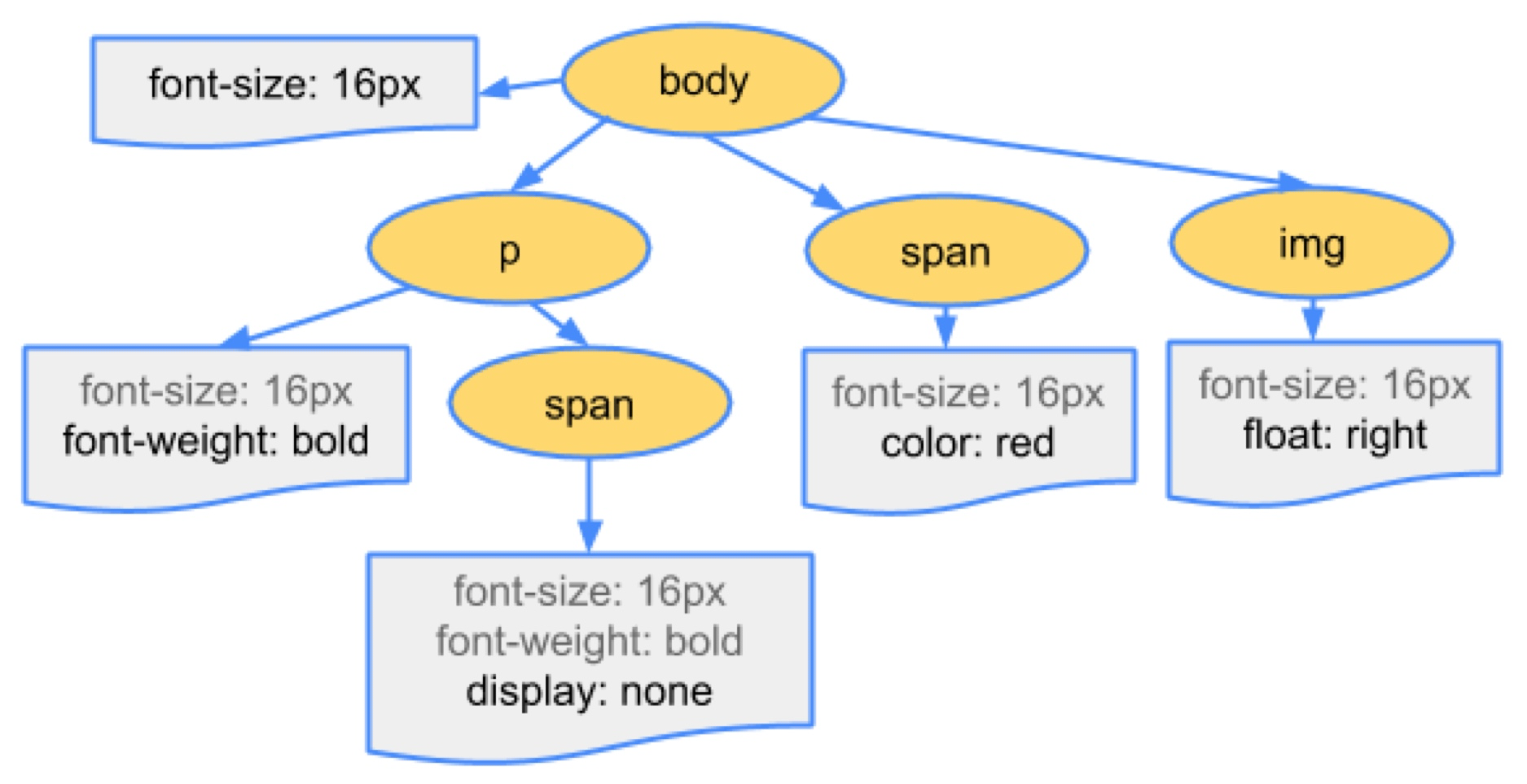
+### *CSS* 数据到 *CSSOM*
+
+*CSS* 数据的原始字节被转换成字符、标记、节点,最后在 *CSSOM*(*CSS* 对象模型)中。 因为 *CSS* 存在层叠机制,该机制决定了将什么样式应用于元素,也就是说,元素的样式数据可以来自父项(通过继承)或设置为元素本身。因此浏览器必须递归遍历 *CSS* 树结构并确定特定元素的样式。
+
+
+
+
+
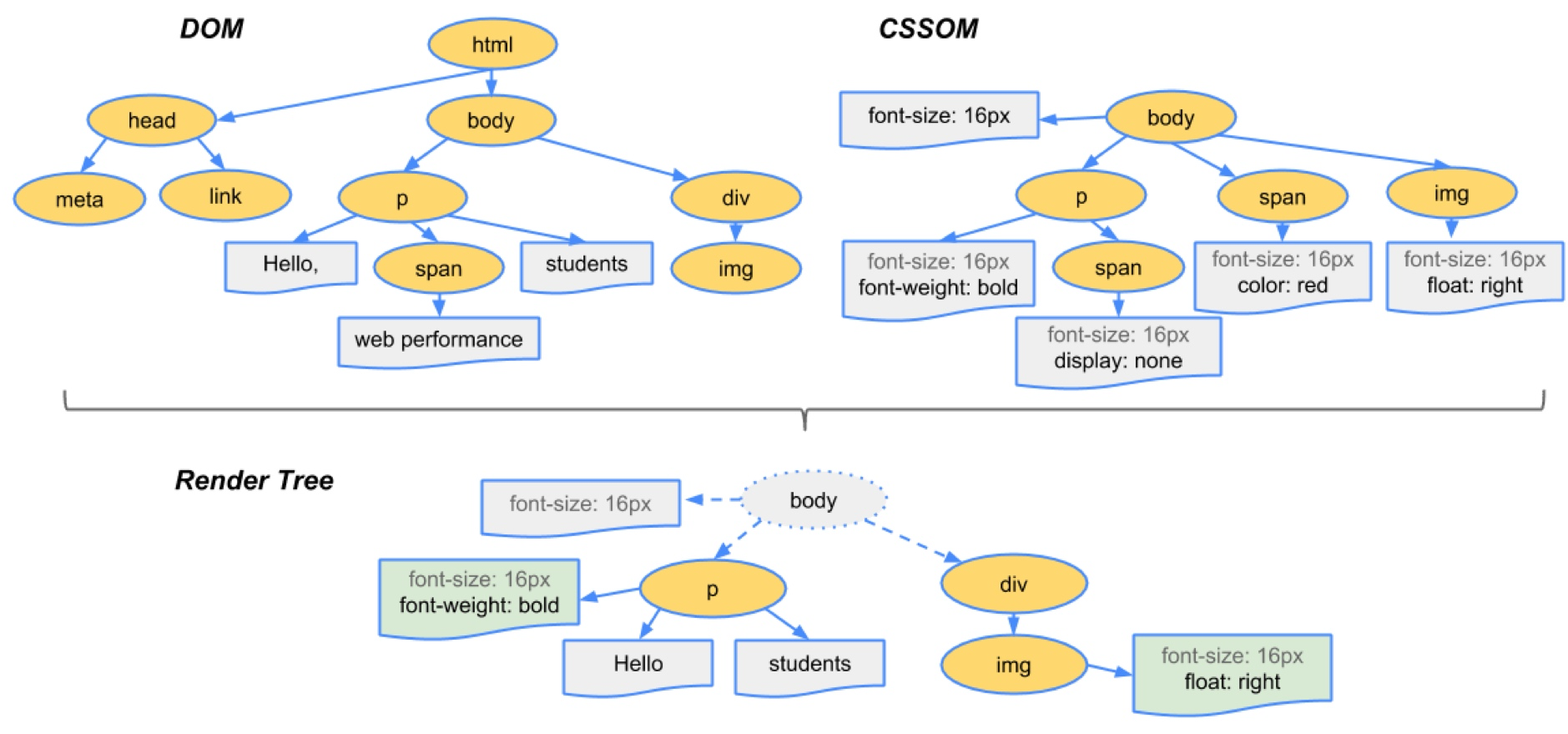
+### *DOM* 和 *CSSOM* 渲染树
+
+*DOM* 树包含有关 *HTML* 元素关系的信息,而 *CSSOM* 树包含有关如何设置这些元素样式的信息。
+
+渲染引擎会将样式信息和 *HTML* 元素关系信息进行汇总,用于创建另一棵树,称为“渲染树”。
+
+渲染树包含具有视觉属性(如颜色和尺寸)的矩形。矩形按正确的顺序显示在屏幕上。
+
+
+
+
+
+
+
+### 布局
+
+在构建渲染树之后,它会经历一个“布局”过程。布局过程的输出是一个“盒子模型”,它精确地捕获视口内每个元素的确切位置和大小:所有相对测量值都转换为屏幕上的绝对像素。
+
+在下面的屏幕截图中,您可以看到为 *body* 元素计算的“框模型”(边距、边框、填充、宽度和高度)信息。
+
+
+
+### 绘制
+
+在这一阶段渲染树会被遍历,并且会只用 *UI* 后端层绘制每个节点。这个过程也被称为“光栅化”。在这个阶段,渲染树中每个节点的计算布局信息被转换为屏幕上的实际像素。
+
+绘画是一个渐进的过程,其中一些部分被解析和渲染,而该过程继续处理来自网络的项目的其余部分。
+
+
+
+
+
+### 整体流程图
+
+渲染整体流程如下图所示:
+
+
+
+
+
+## 网络(*networking*)
+
+该模块处理浏览器内的各种网络通信。它使用一组通信协议,如 *HTTP、HTTPs、FTP*,同时通过 *URL* 获取请求的资源。
+
+
+
+## *JS* 解释器(*JavaScript interpreter*)
+
+*JavaScript* 是一种脚本语言,允许我们动态更新 *Web* 内容、控制由浏览器的 *JS* 引擎执行的多媒体和动画图像。
+
+*DOM* 和 *CSSOM* 为 *JS* 提供了一个接口,可以改变 *DOM* 和 *CSSOM*。由于浏览器不确定特定的 *JS* 会做什么,它会在遇到 *script* 标签后立即暂停 *DOM* 树的构建。
+
+每个脚本都是一个解析拦截器,会让 *DOM* 树的构建停止。
+
+*JS* 引擎在从服务器获取并输入 *JS* 解析器后立即开始解析代码。它将它们转换为机器理解的代表性对象。在抽象句法结构的树表示中存储所有解析器信息的对象称为对象语法树(AST)。这些对象被送入一个解释器,该解释器将这些对象翻译成字节码。
+
+这些是即时 (*JIT*) 编译器,这意味着从服务器下载的 *JavaScript* 文件在客户端的计算机上实时编译。解释器和编译器是结合在一起的。解释器几乎立即执行源代码;编译器生成客户端系统直接执行的机器代码。
+
+不同的浏览器使用不同的 *JS* 引擎:
+
+- *Chrome*: *V8* (*JavaScript* 引擎) (*Node JS* 建立在此之上)
+
+- *Mozilla*: *SpiderMonkey* (旧称“松鼠鱼”)
+
+- *Microsoft Edge*:*Chakra*
+
+- *Safari*:*JavaScriptCore / Nitro WebKit*
+
+
+
+## 用户界面后端(*UI backend*)
+
+用于绘制基本的窗口小部件,比如下拉列表、文本框、按钮等,向上提供公开的接口,向下调用操作系统的用户界面。
+
+
+
+## 数据存储(*data storage*)
+
+这是一个持久层。浏览器可能需要在本地保存各种数据,例如 *cookie*。浏览器还支持 *localStorage、IndexedDB、WebSQL* 和 *FileSystem* 等存储机制。
+
+我们将在下一篇文章讨论浏览器的离线存储。
+
+
+
+## 总结
+
+最后,我们对浏览器的组成部分进行一个总结。
+
+浏览器由以下几个部分组成:
+
+1. 用户界面(*user interface*)
+
+ 用于呈现浏览器窗口部件,比如地址栏、前进后退按钮、书签、顶部菜单等
+
+2. 浏览器引擎(*browser engine*)
+
+ 用户在用户界面和渲染引擎中传递指令
+
+3. 渲染引擎(*rendering engine*)
+
+ 负责解析 *HTML*、*CSS*,并将解析的内容显示到屏幕上。我们平时说的浏览器内核就是指这部分。
+
+4. 网络(*networking*)
+
+ 用户网络调用,比如发送 *http* 请求
+
+5. 用户界面后端(*UI backend*)
+
+ 用于绘制基本的窗口小部件,比如下拉列表、文本框、按钮等,向上提供公开的接口,向下调用操作系统的用户界面。
+
+6. *JS* 解释器(*JavaScript interpreter*)
+
+ 解释执行 *JS* 代码。我们平时说的 *JS* 引擎就是指这部分。
+
+7. 数据存储(*data storage*)
+
+ 用户保存数据到磁盘中。比如 *cookie、localstorage* 等都是使用的这部分功能。
+
+------
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/File API.md b/04. 浏览器的离线存储/File API.md
new file mode 100644
index 0000000..a0162a2
--- /dev/null
+++ b/04. 浏览器的离线存储/File API.md
@@ -0,0 +1,399 @@
+# *File API*
+
+
+
+本文主要包含以下内容:
+
+- *File API* 介绍
+- *File* 对象
+ - 构造函数
+ - 实例属性和实例方法
+- *FileList* 对象
+- *FileReader* 对象
+- 综合实例
+
+
+
+## *File API* 介绍
+
+我们知道,*HTML* 的 *input* 表单控件,其 *type* 属性可以设置为 *file*,表示这是一个上传控件。
+
+```html
+
+```
+
+选择文件前:
+
+
+
+
+
+## *preload*
+
+*preload* 顾名思义就是一种预加载的方式,它通过声明向浏览器声明一个需要提前加载的资源,当资源真正被使用的时候立即执行,就无需等待网络的消耗。
+
+```html
+
+
+
+
+
+```
+
+在上面的代码中,会先加载 *style1.css* 和 *main1.js* 文件(但不会生效),在随后的页面渲染中,一旦需要使用它们,它们就会立即可用。
+
+可以使用 *as* 来指定将要预加载的内容类型。
+
+
+
+
+
+*preload* 指令的一些优点如下:
+
+- 允许浏览器设置资源优先级,从而允许 *Web* 开发人员优化某些资源的交付。
+
+- 使浏览器能够确定资源类型,因此它可以判断将来是否可以重用相同的资源。
+
+- 浏览器可以通过引用 *as* 属性中定义的内容来确定请求是否符合内容安全策略。
+
+- 浏览器可以根据资源类型发送合适的 *Accept* 头(例如:*image/webp* )
+
+
+
+## *prefetch*
+
+*prefetch* 是一种利用浏览器的空闲时间加载页面将来可能用到的资源的一种机制,通常可以用于加载非首页的其他页面所需要的资源,以便加快后续页面的首屏速度。
+
+*prefetch* 加载的资源可以获取非当前页面所需要的资源,并且将其放入缓存至少 *5* 分钟(无论资源是否可以缓存)。并且,当页面跳转时,未完成的 *prefetch* 请求不会被中断;
+
+它的用法跟 *preload* 是一样的:
+
+```html
+
+```
+
+
+
+***DNS prefetching***
+
+*DNS prefetching* 允许浏览器在用户浏览时在后台对页面执行 *DNS* 查找。这最大限度地减少了延迟,因为一旦用户单击链接就已经进行了 *DNS* 查找。
+
+通过将 *rel="dns-prefetch"* 标记添加到链接属性,可以将 *DNS prefetching* 添加到特定 *URL*。建议在诸如 *Web* 字体、*CDN* 之类的东西上使用它。
+
+```html
+
+
+
+
+```
+
+
+
+## *prerender*
+
+*prerender* 与 *prefetch* 非常相似,*prerender* 同样也是会收集用户接下来可能会用到的资源。
+
+不同之处在于 *prerender* 实际上是在后台渲染整个页面。
+
+```html
+
+```
+
+
+
+## *preconnect*
+
+我们要讨论的最后一个资源提示是 *preconnect*。
+
+*preconnect* 指令允许浏览器在 *HTTP* 请求实际发送到服务器之前设置早期连接。
+
+我们知道,浏览器要建立一个连接,一般需要经过 *DNS* 查找,*TCP* 三次握手和 *TLS* 协商(如果是 *https* 的话),这些过程都是需要相当的耗时的。所以 *preconnet*,就是一项使浏览器能够预先建立一个连接,等真正需要加载资源的时候就能够直接请求了。
+
+
+
+
+
+以下是为 *CDN URL* 启用 *preconnect* 的示例。
+
+```html
+
+```
+
+在上面的代码中,浏览器会进行以下步骤:
+
+- 解释 *href* 的属性值,判断是否是合法的 *URL*。如果是合法的 *URL*,然后继续判断 *URL* 的协议是否是 *http* 或者 *https*,如果不是合法的 *URL*,则结束处理。
+- 如果当前页面 *host* 不同于 *href* 属性中的 *host*,那么将不会带上 *cookie*,如果希望带上 *cookie* 等信息,可以加上 *crossorign* 属性。
+
+
+
+-------
+
+
+
+-*EOF*-
diff --git a/03. 浏览器的组成部分/浏览器的组成部分.md b/03. 浏览器的组成部分/浏览器的组成部分.md
new file mode 100644
index 0000000..1e9003b
--- /dev/null
+++ b/03. 浏览器的组成部分/浏览器的组成部分.md
@@ -0,0 +1,217 @@
+# 浏览器的组成部分
+
+
+
+什么是浏览器?
+
+*Web* 浏览器简称为浏览器,是一种用于访问互联网上信息的应用软件。浏览器的主要功能是从服务器检索 *Web* 资源并将其显示在 *Web* 浏览器窗口中。
+
+*Web* 资源通常是 *HTML* 文档,但也可能是 *PDF*、图像、音频、视频或其他类型的内容。资源的位置是通过使用 *URI*(统一资源标识符)指定的。
+
+浏览器包含结构良好的组件,这些组件执行一系列任务让浏览器窗口能显示 *Web* 资源。
+
+本文我们就来聊一聊关于浏览器的组成部分。
+
+下图是关于浏览器的架构图:
+
+
+
+
+
+一个 *Web* 浏览器中,主要组件有:
+
+- 用户界面(*user interface*)
+
+- 浏览器引擎(*browser engine*)
+
+- 渲染引擎(*rendering engine*)
+
+- 网络(*networking*)
+
+- *JS* 解释器(*JavaScript interpreter*)
+
+- 用户界面后端(*UI backend*)
+
+- 数据存储(*data storage*)
+
+下面我们来具体看一下每一个部分的作用。
+
+
+
+## 用户界面(*user interface*)
+
+用户界面用于呈现浏览器窗口部件,比如地址栏、前进后退按钮、书签、顶部菜单等。
+
+如下图所示:
+
+
+
+## 浏览器引擎(*browser engine*)
+
+它是 *UI* 和渲染引擎之间的桥梁。接收来自 *UI* 的输入,然后通过操纵渲染引擎将网页或者其他资源显示在浏览器中。
+
+
+
+## 渲染引擎(*rendering engine*)
+
+负责在浏览器窗口上显示请求的内容。例如,用户请求一个 *HTML* 页面,则它负责解析 *HTML* 文档和 *CSS*,并将解析和格式化的内容显示在屏幕上。我们平时说的浏览器内核就是指这部分。
+
+现代网络浏览器的渲染引擎:
+
+- *Firefox:Gecko Software*
+
+- *Safari:WebKit*
+
+- *Chrome、Opera* (*15* 版本之后):*Blink*
+
+- *Internet Explorer:Trident*
+
+在第一小节我们已经介绍过渲染引擎渲染页面的整体流程了,这里做一个简单的复习。
+
+为了在屏幕上绘制像素(第一次渲染),浏览器在从网络接收数据(*HTML、CSS、JavaScript*)后必须经过一系列称为关键渲染路径的过程/技术。这包括 *DOM*、*CSSOM*、渲染树、布局和绘画。
+
+### 从数据到 *DOM*
+
+来自网络层的请求内容以二进制流格式在渲染引擎中接收(通常为 *8kb* 块)。然后将原始字节转换为 *HTML* 文件的字符(基于字符编码)。
+
+然后将字符转换为标记。词法分析器执行词法分析,将输入分解为标记。在标记化期间,文件中的每个开始和结束标记都被考虑在内。它知道如何去除不相关的字符,如空格和换行符。然后解析器进行语法分析,通过分析文档结构,应用语言语法规则来构建解析树。
+
+解析过程是迭代的。它将向词法分析器询问新的标记,如果语言语法规则匹配,则该标记将被添加到解析树中。然后解析器将要求另一个令牌。如果没有规则匹配,解析器将在内部存储令牌并不断询问令牌,直到找到与所有内部存储的令牌匹配的规则。如果未找到规则,则解析器将引发异常。这意味着该文档无效并且包含语法错误。
+
+这些节点在称为 *DOM*(文档对象模型)的树数据结构中链接,该结构建立了父子关系、相邻兄弟关系。
+
+
+
+
+
+
+
+### *CSS* 数据到 *CSSOM*
+
+*CSS* 数据的原始字节被转换成字符、标记、节点,最后在 *CSSOM*(*CSS* 对象模型)中。 因为 *CSS* 存在层叠机制,该机制决定了将什么样式应用于元素,也就是说,元素的样式数据可以来自父项(通过继承)或设置为元素本身。因此浏览器必须递归遍历 *CSS* 树结构并确定特定元素的样式。
+
+
+
+
+
+### *DOM* 和 *CSSOM* 渲染树
+
+*DOM* 树包含有关 *HTML* 元素关系的信息,而 *CSSOM* 树包含有关如何设置这些元素样式的信息。
+
+渲染引擎会将样式信息和 *HTML* 元素关系信息进行汇总,用于创建另一棵树,称为“渲染树”。
+
+渲染树包含具有视觉属性(如颜色和尺寸)的矩形。矩形按正确的顺序显示在屏幕上。
+
+
+
+
+
+
+
+### 布局
+
+在构建渲染树之后,它会经历一个“布局”过程。布局过程的输出是一个“盒子模型”,它精确地捕获视口内每个元素的确切位置和大小:所有相对测量值都转换为屏幕上的绝对像素。
+
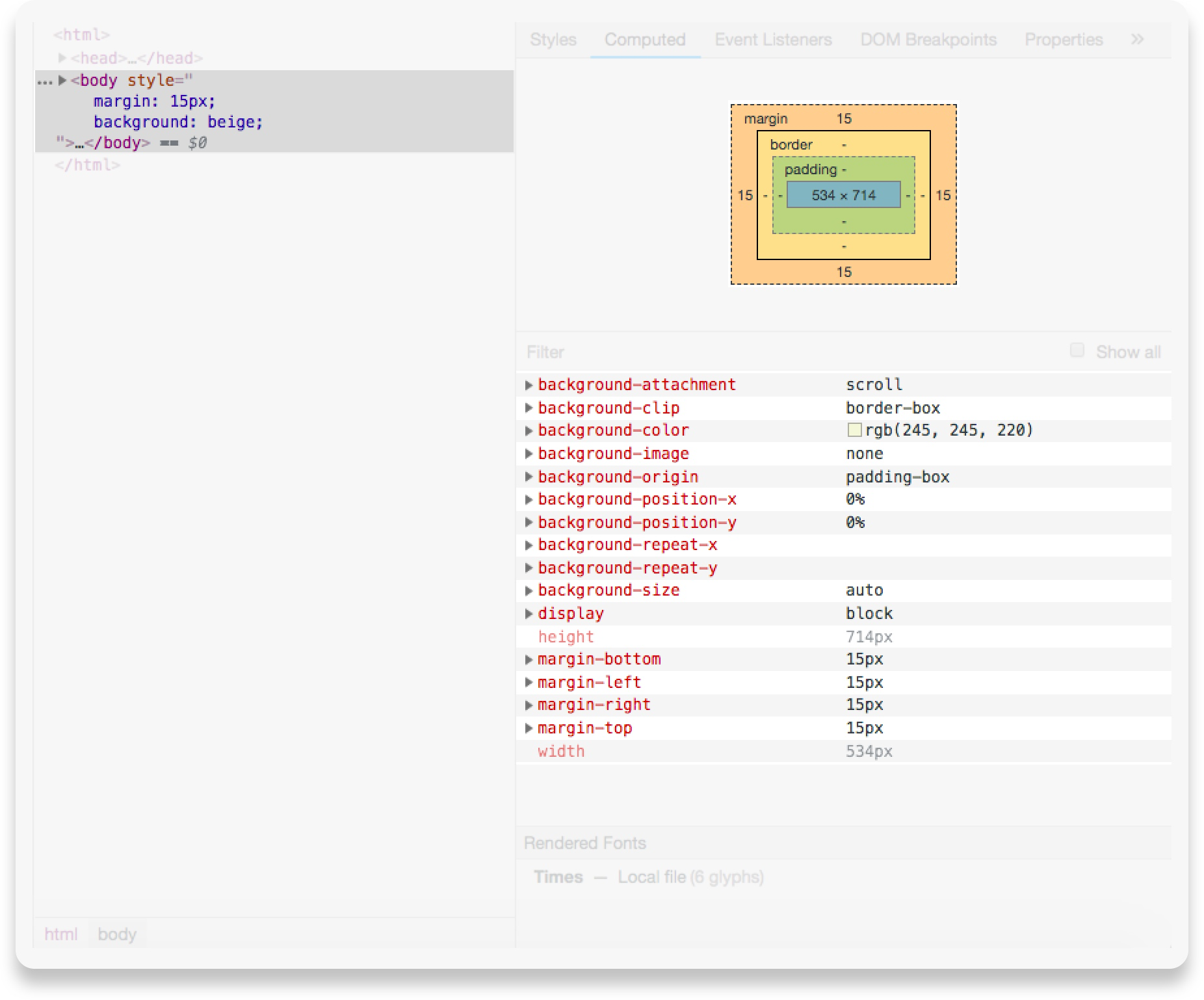
+在下面的屏幕截图中,您可以看到为 *body* 元素计算的“框模型”(边距、边框、填充、宽度和高度)信息。
+
+
+
+### 绘制
+
+在这一阶段渲染树会被遍历,并且会只用 *UI* 后端层绘制每个节点。这个过程也被称为“光栅化”。在这个阶段,渲染树中每个节点的计算布局信息被转换为屏幕上的实际像素。
+
+绘画是一个渐进的过程,其中一些部分被解析和渲染,而该过程继续处理来自网络的项目的其余部分。
+
+
+
+
+
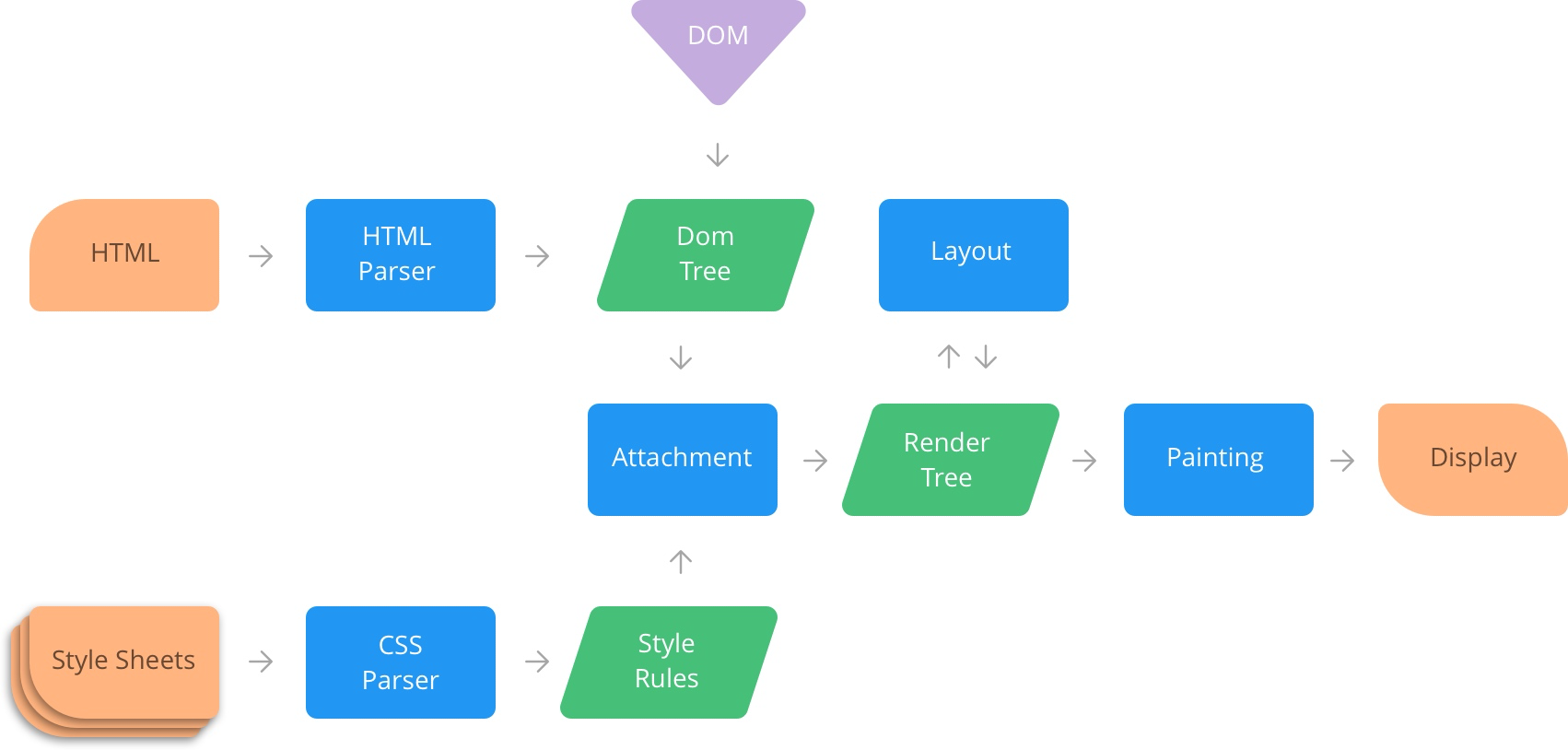
+### 整体流程图
+
+渲染整体流程如下图所示:
+
+
+
+
+
+## 网络(*networking*)
+
+该模块处理浏览器内的各种网络通信。它使用一组通信协议,如 *HTTP、HTTPs、FTP*,同时通过 *URL* 获取请求的资源。
+
+
+
+## *JS* 解释器(*JavaScript interpreter*)
+
+*JavaScript* 是一种脚本语言,允许我们动态更新 *Web* 内容、控制由浏览器的 *JS* 引擎执行的多媒体和动画图像。
+
+*DOM* 和 *CSSOM* 为 *JS* 提供了一个接口,可以改变 *DOM* 和 *CSSOM*。由于浏览器不确定特定的 *JS* 会做什么,它会在遇到 *script* 标签后立即暂停 *DOM* 树的构建。
+
+每个脚本都是一个解析拦截器,会让 *DOM* 树的构建停止。
+
+*JS* 引擎在从服务器获取并输入 *JS* 解析器后立即开始解析代码。它将它们转换为机器理解的代表性对象。在抽象句法结构的树表示中存储所有解析器信息的对象称为对象语法树(AST)。这些对象被送入一个解释器,该解释器将这些对象翻译成字节码。
+
+这些是即时 (*JIT*) 编译器,这意味着从服务器下载的 *JavaScript* 文件在客户端的计算机上实时编译。解释器和编译器是结合在一起的。解释器几乎立即执行源代码;编译器生成客户端系统直接执行的机器代码。
+
+不同的浏览器使用不同的 *JS* 引擎:
+
+- *Chrome*: *V8* (*JavaScript* 引擎) (*Node JS* 建立在此之上)
+
+- *Mozilla*: *SpiderMonkey* (旧称“松鼠鱼”)
+
+- *Microsoft Edge*:*Chakra*
+
+- *Safari*:*JavaScriptCore / Nitro WebKit*
+
+
+
+## 用户界面后端(*UI backend*)
+
+用于绘制基本的窗口小部件,比如下拉列表、文本框、按钮等,向上提供公开的接口,向下调用操作系统的用户界面。
+
+
+
+## 数据存储(*data storage*)
+
+这是一个持久层。浏览器可能需要在本地保存各种数据,例如 *cookie*。浏览器还支持 *localStorage、IndexedDB、WebSQL* 和 *FileSystem* 等存储机制。
+
+我们将在下一篇文章讨论浏览器的离线存储。
+
+
+
+## 总结
+
+最后,我们对浏览器的组成部分进行一个总结。
+
+浏览器由以下几个部分组成:
+
+1. 用户界面(*user interface*)
+
+ 用于呈现浏览器窗口部件,比如地址栏、前进后退按钮、书签、顶部菜单等
+
+2. 浏览器引擎(*browser engine*)
+
+ 用户在用户界面和渲染引擎中传递指令
+
+3. 渲染引擎(*rendering engine*)
+
+ 负责解析 *HTML*、*CSS*,并将解析的内容显示到屏幕上。我们平时说的浏览器内核就是指这部分。
+
+4. 网络(*networking*)
+
+ 用户网络调用,比如发送 *http* 请求
+
+5. 用户界面后端(*UI backend*)
+
+ 用于绘制基本的窗口小部件,比如下拉列表、文本框、按钮等,向上提供公开的接口,向下调用操作系统的用户界面。
+
+6. *JS* 解释器(*JavaScript interpreter*)
+
+ 解释执行 *JS* 代码。我们平时说的 *JS* 引擎就是指这部分。
+
+7. 数据存储(*data storage*)
+
+ 用户保存数据到磁盘中。比如 *cookie、localstorage* 等都是使用的这部分功能。
+
+------
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/File API.md b/04. 浏览器的离线存储/File API.md
new file mode 100644
index 0000000..a0162a2
--- /dev/null
+++ b/04. 浏览器的离线存储/File API.md
@@ -0,0 +1,399 @@
+# *File API*
+
+
+
+本文主要包含以下内容:
+
+- *File API* 介绍
+- *File* 对象
+ - 构造函数
+ - 实例属性和实例方法
+- *FileList* 对象
+- *FileReader* 对象
+- 综合实例
+
+
+
+## *File API* 介绍
+
+我们知道,*HTML* 的 *input* 表单控件,其 *type* 属性可以设置为 *file*,表示这是一个上传控件。
+
+```html
+
+```
+
+选择文件前:
+
+ +
+选择文件后:
+
+
+
+选择文件后:
+
+ +
+这种做法用户体验非常的差,我们无法**在客户端**对用户选取的文件进行 *validate*,无法读取文件大小,无法判断文件类型,无法预览。
+
+如果是多文件上传,*JavaScript* 更是回天乏力。
+
+```html
+
+```
+
+
+
+
+
+这种做法用户体验非常的差,我们无法**在客户端**对用户选取的文件进行 *validate*,无法读取文件大小,无法判断文件类型,无法预览。
+
+如果是多文件上传,*JavaScript* 更是回天乏力。
+
+```html
+
+```
+
+
+
+ +
+但现在有了 *HTML5* 提供的 *File API*,一切都不同了。该接口允许 *JavaScript* 读取本地文件,但并不能直接访问本地文件,而是要依赖于用户行为,比如用户在 *type='file'* 控件上选择了某个文件或者用户将文件拖拽到浏览器上。
+
+*File Api* 提供了以下几个接口来访问本地文件系统:
+
+- *File*:单个文件,提供了诸如 *name、file size、mimetype* 等只读文件属性
+
+- *FileList*:一个类数组 *File* 对象集合
+
+- *FileReader*:异步读取文件的接口
+
+- *Blob*:文件对象的二进制原始数据
+
+
+
+## *File* 对象
+
+*File* 对象代表一个文件,用来读写文件信息。它继承了 *Blob* 对象,或者说是一种特殊的 *Blob* 对象,所有可以使用 *Blob* 对象的场合都可以使用它。
+
+最常见的使用场合是表单的文件上传控件(\<*input type="file"*>),用户选中文件以后,浏览器就会生成一个数组,里面是每一个用户选中的文件,它们都是 *File* 实例对象。
+
+```html
+
+```
+
+```js
+// 获取 DOM 元素
+var file = document.getElementById('file');
+file.onchange = function(event){
+ var files = event.target.files;
+ console.log(files);
+ console.log(files[0] instanceof File);
+}
+```
+
+上面代码中,*files[0]* 是用户选中的第一个文件,它是 *File* 的实例。
+
+
+
+但现在有了 *HTML5* 提供的 *File API*,一切都不同了。该接口允许 *JavaScript* 读取本地文件,但并不能直接访问本地文件,而是要依赖于用户行为,比如用户在 *type='file'* 控件上选择了某个文件或者用户将文件拖拽到浏览器上。
+
+*File Api* 提供了以下几个接口来访问本地文件系统:
+
+- *File*:单个文件,提供了诸如 *name、file size、mimetype* 等只读文件属性
+
+- *FileList*:一个类数组 *File* 对象集合
+
+- *FileReader*:异步读取文件的接口
+
+- *Blob*:文件对象的二进制原始数据
+
+
+
+## *File* 对象
+
+*File* 对象代表一个文件,用来读写文件信息。它继承了 *Blob* 对象,或者说是一种特殊的 *Blob* 对象,所有可以使用 *Blob* 对象的场合都可以使用它。
+
+最常见的使用场合是表单的文件上传控件(\<*input type="file"*>),用户选中文件以后,浏览器就会生成一个数组,里面是每一个用户选中的文件,它们都是 *File* 实例对象。
+
+```html
+
+```
+
+```js
+// 获取 DOM 元素
+var file = document.getElementById('file');
+file.onchange = function(event){
+ var files = event.target.files;
+ console.log(files);
+ console.log(files[0] instanceof File);
+}
+```
+
+上面代码中,*files[0]* 是用户选中的第一个文件,它是 *File* 的实例。
+
+ +
+
+
+### 构造函数
+
+浏览器原生提供一个 *File( )* 构造函数,用来生成 *File* 实例对象。
+
+```js
+new File(array, name [, options])
+```
+
+*File( )* 构造函数接受三个参数。
+
+- *array*:一个数组,成员可以是二进制对象或字符串,表示文件的内容。
+
+- *name*:字符串,表示文件名或文件路径。
+
+- *options*:配置对象,设置实例的属性。该参数可选。
+
+第三个参数配置对象,可以设置两个属性。
+
+- *type*:字符串,表示实例对象的 *MIME* 类型,默认值为空字符串。
+
+- *lastModified*:时间戳,表示上次修改的时间,默认为 *Date.now( )*。
+
+下面是一个例子。
+
+```js
+var file = new File(
+ ['foo'],
+ 'foo.txt',
+ {
+ type: 'text/plain',
+ }
+);
+```
+
+### 实例属性和实例方法
+
+*File* 对象有以下实例属性。
+
+- *File.lastModified*:最后修改时间
+
+- *File.name*:文件名或文件路径
+
+- *File.size*:文件大小(单位字节)
+
+- *File.type*:文件的 *MIME* 类型
+
+```js
+var file = new File(
+ ['foo'],
+ 'foo.txt',
+ {
+ type: 'text/plain',
+ }
+);
+console.log(file.lastModified); // 1638340865992
+console.log(file.name); // foo.txt
+console.log(file.size); // 3
+console.log(file.type); // text/plain
+```
+
+在上面的代码中,我们创建了一个 *File* 文件对象实例,并打印出了该文件对象的诸如 *lastModified、name、size、type* 等属性信息。
+
+*File* 对象没有自己的实例方法,由于继承了 *Blob* 对象,因此可以使用 *Blob* 的实例方法 *slice( )*。
+
+
+
+## *FileList* 对象
+
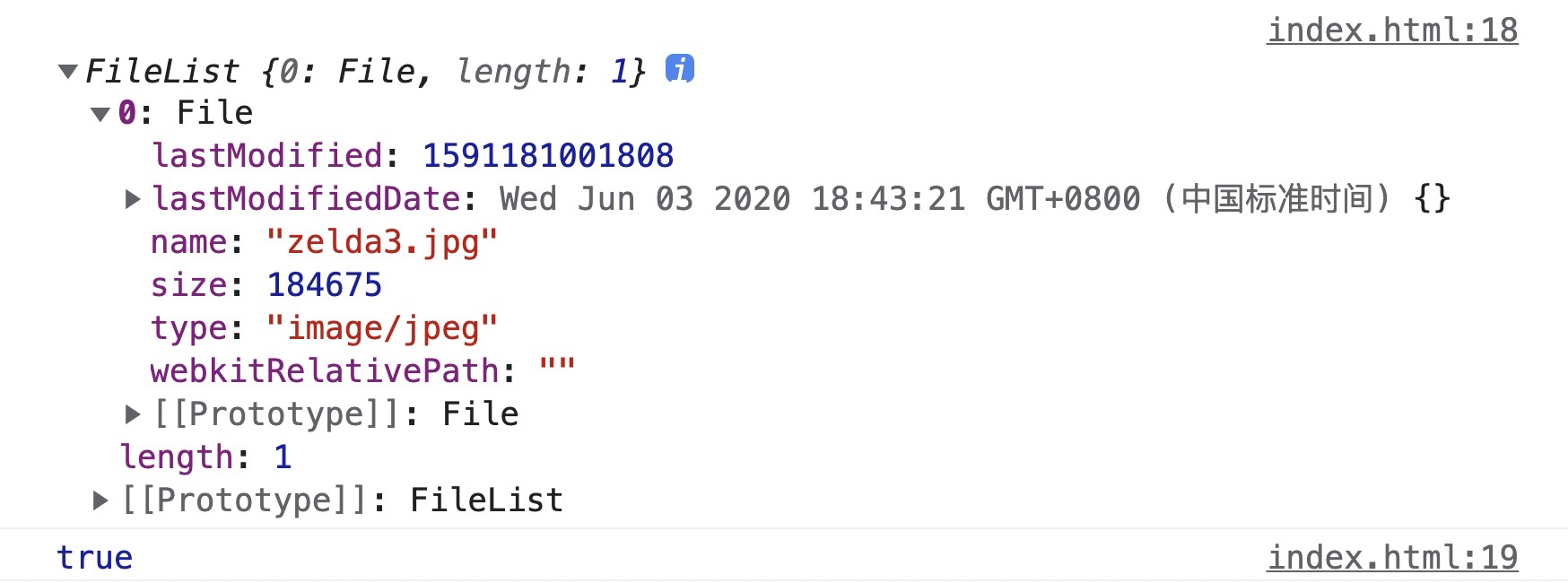
+*FileList* 对象是一个类似数组的对象,代表一组选中的文件,每个成员都是一个 *File* 实例。
+
+在最上面的那个示例中,我们就可以看到触发 *change* 事件后,*event.target.files* 拿到的就是一个 *FileList* 实例对象。
+
+它主要出现在两个场合。
+
+- 文件控件节点(\<*input type="file"*>)的 *files* 属性,返回一个 *FileList* 实例。
+
+- 拖拉一组文件时,目标区的 *DataTransfer.files* 属性,返回一个 *FileList* 实例。
+
+```html
+
+
+
+
+```
+
+上面代码中,文件控件的 *files* 属性是一个 *FileList* 实例。
+
+*FileList* 的实例属性主要是 *length*,表示包含多少个文件。
+
+*FileList* 的实例方法主要是 *item( )*,用来返回指定位置的实例。它接受一个整数作为参数,表示位置的序号(从零开始)。
+
+但是,由于 *FileList* 的实例是一个类似数组的对象,可以直接用方括号运算符,即 *myFileList[0]* 等同于 *myFileList.item(0)*,所以一般用不到 *item( )* 方法。
+
+
+
+## *FileReader* 对象
+
+*FileReader* 对象用于读取 *File* 对象或 *Blob* 对象所包含的文件内容。
+
+浏览器原生提供一个 *FileReader* 构造函数,用来生成 *FileReader* 实例。
+
+```js
+var reader = new FileReader();
+```
+
+*FileReader* 有以下的实例属性。
+
+- *FileReader.error*:读取文件时产生的错误对象
+
+- *FileReader.readyState*:整数,表示读取文件时的当前状态。一共有三种可能的状态,*0* 表示尚未加载任何数据,*1* 表示数据正在加载,*2* 表示加载完成。
+
+- *FileReader.result*:读取完成后的文件内容,有可能是字符串,也可能是一个 *ArrayBuffer* 实例。
+
+- *FileReader.onabort*:*abort* 事件(用户终止读取操作)的监听函数。
+
+- *FileReader.onerror*:*error* 事件(读取错误)的监听函数。
+
+- *FileReader.onload*:*load* 事件(读取操作完成)的监听函数,通常在这个函数里面使用 *result* 属性,拿到文件内容。
+
+- *FileReader.onloadstart*:*loadstart* 事件(读取操作开始)的监听函数。
+
+- *FileReader.onloadend*:*loadend* 事件(读取操作结束)的监听函数。
+
+- *FileReader.onprogress*:*progress* 事件(读取操作进行中)的监听函数。
+
+下面是监听 *load* 事件的一个例子。
+
+```html
+
+
+
+
+```
+
+上面代码中,每当文件控件发生变化,就尝试读取第一个文件。如果读取成功( *load* 事件发生),就打印出文件内容。
+
+*FileReader* 有以下实例方法。
+
+- *FileReader.abort( )*:终止读取操作,*readyState* 属性将变成 *2*。
+
+- *FileReader.readAsArrayBuffer( )*:以 *ArrayBuffer* 的格式读取文件,读取完成后 *result* 属性将返回一个 *ArrayBuffer* 实例。
+
+- *FileReader.readAsBinaryString( )*:读取完成后,*result* 属性将返回原始的二进制字符串。
+
+- *FileReader.readAsDataURL( )*:读取完成后,*result* 属性将返回一个 *Data URL* 格式( *Base64* 编码)的字符串,代表文件内容。对于图片文件,这个字符串可以用于 \<*img*> 元素的 *src* 属性。注意,这个字符串不能直接进行 *Base64* 解码,必须把前缀 `data:*/*;base64,` 从字符串里删除以后,再进行解码。
+
+- *FileReader.readAsText( )*:读取完成后,*result* 属性将返回文件内容的文本字符串。该方法的第一个参数是代表文件的 *Blob* 实例,第二个参数是可选的,表示文本编码,默认为 *UTF-8*。
+
+下面是一个读取图片文件的例子。
+
+```html
+
+
+
+
+
+### 构造函数
+
+浏览器原生提供一个 *File( )* 构造函数,用来生成 *File* 实例对象。
+
+```js
+new File(array, name [, options])
+```
+
+*File( )* 构造函数接受三个参数。
+
+- *array*:一个数组,成员可以是二进制对象或字符串,表示文件的内容。
+
+- *name*:字符串,表示文件名或文件路径。
+
+- *options*:配置对象,设置实例的属性。该参数可选。
+
+第三个参数配置对象,可以设置两个属性。
+
+- *type*:字符串,表示实例对象的 *MIME* 类型,默认值为空字符串。
+
+- *lastModified*:时间戳,表示上次修改的时间,默认为 *Date.now( )*。
+
+下面是一个例子。
+
+```js
+var file = new File(
+ ['foo'],
+ 'foo.txt',
+ {
+ type: 'text/plain',
+ }
+);
+```
+
+### 实例属性和实例方法
+
+*File* 对象有以下实例属性。
+
+- *File.lastModified*:最后修改时间
+
+- *File.name*:文件名或文件路径
+
+- *File.size*:文件大小(单位字节)
+
+- *File.type*:文件的 *MIME* 类型
+
+```js
+var file = new File(
+ ['foo'],
+ 'foo.txt',
+ {
+ type: 'text/plain',
+ }
+);
+console.log(file.lastModified); // 1638340865992
+console.log(file.name); // foo.txt
+console.log(file.size); // 3
+console.log(file.type); // text/plain
+```
+
+在上面的代码中,我们创建了一个 *File* 文件对象实例,并打印出了该文件对象的诸如 *lastModified、name、size、type* 等属性信息。
+
+*File* 对象没有自己的实例方法,由于继承了 *Blob* 对象,因此可以使用 *Blob* 的实例方法 *slice( )*。
+
+
+
+## *FileList* 对象
+
+*FileList* 对象是一个类似数组的对象,代表一组选中的文件,每个成员都是一个 *File* 实例。
+
+在最上面的那个示例中,我们就可以看到触发 *change* 事件后,*event.target.files* 拿到的就是一个 *FileList* 实例对象。
+
+它主要出现在两个场合。
+
+- 文件控件节点(\<*input type="file"*>)的 *files* 属性,返回一个 *FileList* 实例。
+
+- 拖拉一组文件时,目标区的 *DataTransfer.files* 属性,返回一个 *FileList* 实例。
+
+```html
+
+
+
+
+```
+
+上面代码中,文件控件的 *files* 属性是一个 *FileList* 实例。
+
+*FileList* 的实例属性主要是 *length*,表示包含多少个文件。
+
+*FileList* 的实例方法主要是 *item( )*,用来返回指定位置的实例。它接受一个整数作为参数,表示位置的序号(从零开始)。
+
+但是,由于 *FileList* 的实例是一个类似数组的对象,可以直接用方括号运算符,即 *myFileList[0]* 等同于 *myFileList.item(0)*,所以一般用不到 *item( )* 方法。
+
+
+
+## *FileReader* 对象
+
+*FileReader* 对象用于读取 *File* 对象或 *Blob* 对象所包含的文件内容。
+
+浏览器原生提供一个 *FileReader* 构造函数,用来生成 *FileReader* 实例。
+
+```js
+var reader = new FileReader();
+```
+
+*FileReader* 有以下的实例属性。
+
+- *FileReader.error*:读取文件时产生的错误对象
+
+- *FileReader.readyState*:整数,表示读取文件时的当前状态。一共有三种可能的状态,*0* 表示尚未加载任何数据,*1* 表示数据正在加载,*2* 表示加载完成。
+
+- *FileReader.result*:读取完成后的文件内容,有可能是字符串,也可能是一个 *ArrayBuffer* 实例。
+
+- *FileReader.onabort*:*abort* 事件(用户终止读取操作)的监听函数。
+
+- *FileReader.onerror*:*error* 事件(读取错误)的监听函数。
+
+- *FileReader.onload*:*load* 事件(读取操作完成)的监听函数,通常在这个函数里面使用 *result* 属性,拿到文件内容。
+
+- *FileReader.onloadstart*:*loadstart* 事件(读取操作开始)的监听函数。
+
+- *FileReader.onloadend*:*loadend* 事件(读取操作结束)的监听函数。
+
+- *FileReader.onprogress*:*progress* 事件(读取操作进行中)的监听函数。
+
+下面是监听 *load* 事件的一个例子。
+
+```html
+
+
+
+
+```
+
+上面代码中,每当文件控件发生变化,就尝试读取第一个文件。如果读取成功( *load* 事件发生),就打印出文件内容。
+
+*FileReader* 有以下实例方法。
+
+- *FileReader.abort( )*:终止读取操作,*readyState* 属性将变成 *2*。
+
+- *FileReader.readAsArrayBuffer( )*:以 *ArrayBuffer* 的格式读取文件,读取完成后 *result* 属性将返回一个 *ArrayBuffer* 实例。
+
+- *FileReader.readAsBinaryString( )*:读取完成后,*result* 属性将返回原始的二进制字符串。
+
+- *FileReader.readAsDataURL( )*:读取完成后,*result* 属性将返回一个 *Data URL* 格式( *Base64* 编码)的字符串,代表文件内容。对于图片文件,这个字符串可以用于 \<*img*> 元素的 *src* 属性。注意,这个字符串不能直接进行 *Base64* 解码,必须把前缀 `data:*/*;base64,` 从字符串里删除以后,再进行解码。
+
+- *FileReader.readAsText( )*:读取完成后,*result* 属性将返回文件内容的文本字符串。该方法的第一个参数是代表文件的 *Blob* 实例,第二个参数是可选的,表示文本编码,默认为 *UTF-8*。
+
+下面是一个读取图片文件的例子。
+
+```html
+
+ +
+(图为该 *API* 目前在各大浏览器的支持情况,可以看到全线飙红)
+
+目前针对该 *API* 的相关资料,无论是中文还是英文都比较少,如果对该 API 感兴趣的同学,下面给出两个扩展阅读资料(英文)
+
+- *MDN*:*https://developer.mozilla.org/en-US/docs/Web/API/File_System_Access_API*
+
+- *web.dev*:*https://web.dev/file-system-access/*
+
+-------
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/File API课堂代码/.vscode/settings.json b/04. 浏览器的离线存储/File API课堂代码/.vscode/settings.json
new file mode 100644
index 0000000..5165b7c
--- /dev/null
+++ b/04. 浏览器的离线存储/File API课堂代码/.vscode/settings.json
@@ -0,0 +1,3 @@
+{
+ "eggHelper.serverPort": 35684
+}
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/File API课堂代码/index.html b/04. 浏览器的离线存储/File API课堂代码/index.html
new file mode 100644
index 0000000..049dfc9
--- /dev/null
+++ b/04. 浏览器的离线存储/File API课堂代码/index.html
@@ -0,0 +1,72 @@
+
+
+
+
+
+
+
+
+
+(图为该 *API* 目前在各大浏览器的支持情况,可以看到全线飙红)
+
+目前针对该 *API* 的相关资料,无论是中文还是英文都比较少,如果对该 API 感兴趣的同学,下面给出两个扩展阅读资料(英文)
+
+- *MDN*:*https://developer.mozilla.org/en-US/docs/Web/API/File_System_Access_API*
+
+- *web.dev*:*https://web.dev/file-system-access/*
+
+-------
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/File API课堂代码/.vscode/settings.json b/04. 浏览器的离线存储/File API课堂代码/.vscode/settings.json
new file mode 100644
index 0000000..5165b7c
--- /dev/null
+++ b/04. 浏览器的离线存储/File API课堂代码/.vscode/settings.json
@@ -0,0 +1,3 @@
+{
+ "eggHelper.serverPort": 35684
+}
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/File API课堂代码/index.html b/04. 浏览器的离线存储/File API课堂代码/index.html
new file mode 100644
index 0000000..049dfc9
--- /dev/null
+++ b/04. 浏览器的离线存储/File API课堂代码/index.html
@@ -0,0 +1,72 @@
+
+
+
+
+
+
+
+  +
+
+
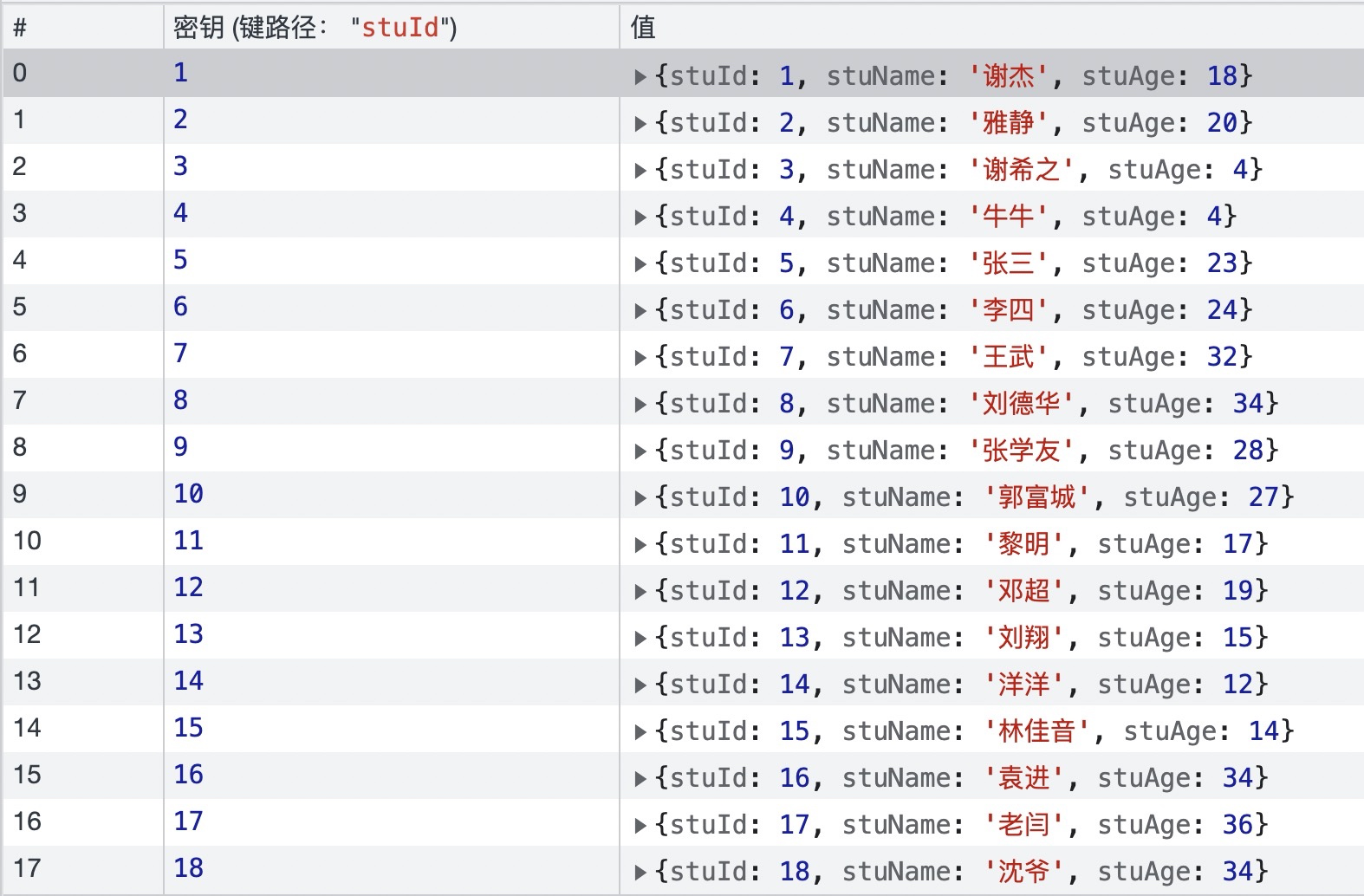
+*MDN* 官网是这样解释 *IndexedDB* 的:
+>*IndexedDB* 是一种底层 *API*,用于在客户端存储大量的结构化数据(也包括文件/二进制大型对象(*blobs*))。该 *API* 使用索引实现对数据的高性能搜索。虽然 *Web Storage* 在存储较少量的数据很有用,但对于存储更大量的结构化数据来说力不从心。而 *IndexedDB* 提供了这种场景的解决方案。
+
+
+
+通俗地说,*IndexedDB* 就是浏览器提供的本地数据库,它可以被网页脚本创建和操作。*IndexedDB* 允许储存大量数据,提供查找接口,还能建立索引。这些都是 *LocalStorage* 所不具备的。就数据库类型而言,*IndexedDB* 不属于关系型数据库(不支持 *SQL* 查询语句),更接近 *NoSQL* 数据库。
+
+下表罗列出了几种常见的客户端存储方式的对比:
+
+| | 会话期 Cookie | 持久性 Cookie | sessionStorage | localStorage | IndexedDB | WebSQL |
+| -------- | ------------------ | ------------------------ | ---------------- | ------------------------ | -------------- | ------ |
+| 存储大小 | 4kb | 4kb | 2.5~10MB | 2.5~10MB | >250MB | 已废弃 |
+| 失效时间 | 浏览器关闭自动清除 | 设置过期时间,到期后清除 | 浏览器关闭后清除 | 永久保存(除非手动清除) | 手动更新或删除 | 已废弃 |
+
+
+
+*IndexedDB* 具有以下特点。
+
+- 键值对储存:*IndexedDB* 内部采用对象仓库( *object store* )存放数据。所有类型的数据都可以直接存入,包括 *JavaScript* 对象。对象仓库中,数据以“键值对”的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
+
+- 异步:*IndexedDB* 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 *LocalStorage* 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
+
+- 支持事务:*IndexedDB* 支持事务( *transaction* ),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。这和 *MySQL* 等数据库的事务类似。
+
+- 同源限制:*IndexedDB* 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
+
+- 储存空间大:这是 *IndexedDB* 最显著的特点之一。*IndexedDB* 的储存空间比 *LocalStorage* 大得多,一般来说不少于 *250MB*,甚至没有上限。
+
+- 支持二进制储存:*IndexedDB* 不仅可以储存字符串,还可以储存二进制数据(*ArrayBuffer* 对象和 *Blob* 对象)。
+
+*IndexedDB* 主要使用在于客户端需要存储大量的数据的场景下:
+
+- 数据可视化等界面,大量数据,每次请求会消耗很大性能。
+
+- 即时聊天工具,大量消息需要存在本地。
+
+- 其它存储方式容量不满足时,不得已使用 *IndexedDB*
+
+
+
+## *IndexedDB* 重要概念
+
+在正式开始之前,我们先来介绍一下 *IndexedDB* 里面一些重要的概念。
+
+*IndexedDB* 是一个比较复杂的 *API*,涉及不少概念。它把不同的实体,抽象成一个个对象接口。学习这个 *API*,就是学习它的各种对象接口。
+
+- 数据库:*IDBDatabase* 对象
+
+- 对象仓库:*IDBObjectStore* 对象
+
+- 索引:*IDBIndex* 对象
+
+- 事务:*IDBTransaction* 对象
+
+- 操作请求:*IDBRequest* 对象
+
+- 指针:*IDBCursor* 对象
+
+- 主键集合:*IDBKeyRange* 对象
+
+下面是一些主要的概念。
+
+(1)数据库
+
+数据库是一系列相关数据的容器。每个域名(严格的说,是协议 + 域名 + 端口)都可以新建任意多个数据库。
+
+*IndexedDB* 数据库有版本的概念。同一个时刻,只能有一个版本的数据库存在。如果要修改数据库结构(新增或删除表、索引或者主键),只能通过升级数据库版本完成。
+
+(2)对象仓库
+
+每个数据库包含若干个对象仓库( *object store* )。它类似于关系型数据库的表格。
+
+(3)数据记录
+
+对象仓库保存的是数据记录。每条记录类似于关系型数据库的行,但是只有主键和数据体两部分。主键用来建立默认的索引,必须是不同的,否则会报错。主键可以是数据记录里面的一个属性,也可以指定为一个递增的整数编号。
+
+```js
+{ id: 1, text: 'foo' }
+```
+
+上面的对象中,*id* 属性可以当作主键。
+
+数据体可以是任意数据类型,不限于对象。
+
+(4)索引
+
+为了加速数据的检索,可以在对象仓库里面,为不同的属性建立索引。
+
+在关系型数据库当中也有索引的概念,我们可以给对应的表字段添加索引,以便加快查找速率。在 *IndexedDB* 中同样有索引,我们可以在创建 *store* 的时候同时创建索引,在后续对 *store* 进行查询的时候即可通过索引来筛选,给某个字段添加索引后,在后续插入数据的过成功,索引字段便不能为空。
+
+(5)事务
+
+数据记录的读写和删改,都要通过事务完成。事务对象提供 *error、abort* 和 *complete* 三个事件,用来监听操作结果。
+
+(6)指针(游标)
+游标是 *IndexedDB* 数据库新的概念,大家可以把游标想象为一个指针,比如我们要查询满足某一条件的所有数据时,就需要用到游标,我们让游标一行一行的往下走,游标走到的地方便会返回这一行数据,此时我们便可对此行数据进行判断,是否满足条件。
+
+## *IndexedDB* 实操
+
+*IndexedDB* 所有针对仓库的操作都是基于事务的。
+
+在正式开始之前,我们先创建如下的项目结构:
+
+
+
+
+
+*MDN* 官网是这样解释 *IndexedDB* 的:
+>*IndexedDB* 是一种底层 *API*,用于在客户端存储大量的结构化数据(也包括文件/二进制大型对象(*blobs*))。该 *API* 使用索引实现对数据的高性能搜索。虽然 *Web Storage* 在存储较少量的数据很有用,但对于存储更大量的结构化数据来说力不从心。而 *IndexedDB* 提供了这种场景的解决方案。
+
+
+
+通俗地说,*IndexedDB* 就是浏览器提供的本地数据库,它可以被网页脚本创建和操作。*IndexedDB* 允许储存大量数据,提供查找接口,还能建立索引。这些都是 *LocalStorage* 所不具备的。就数据库类型而言,*IndexedDB* 不属于关系型数据库(不支持 *SQL* 查询语句),更接近 *NoSQL* 数据库。
+
+下表罗列出了几种常见的客户端存储方式的对比:
+
+| | 会话期 Cookie | 持久性 Cookie | sessionStorage | localStorage | IndexedDB | WebSQL |
+| -------- | ------------------ | ------------------------ | ---------------- | ------------------------ | -------------- | ------ |
+| 存储大小 | 4kb | 4kb | 2.5~10MB | 2.5~10MB | >250MB | 已废弃 |
+| 失效时间 | 浏览器关闭自动清除 | 设置过期时间,到期后清除 | 浏览器关闭后清除 | 永久保存(除非手动清除) | 手动更新或删除 | 已废弃 |
+
+
+
+*IndexedDB* 具有以下特点。
+
+- 键值对储存:*IndexedDB* 内部采用对象仓库( *object store* )存放数据。所有类型的数据都可以直接存入,包括 *JavaScript* 对象。对象仓库中,数据以“键值对”的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
+
+- 异步:*IndexedDB* 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 *LocalStorage* 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
+
+- 支持事务:*IndexedDB* 支持事务( *transaction* ),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。这和 *MySQL* 等数据库的事务类似。
+
+- 同源限制:*IndexedDB* 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
+
+- 储存空间大:这是 *IndexedDB* 最显著的特点之一。*IndexedDB* 的储存空间比 *LocalStorage* 大得多,一般来说不少于 *250MB*,甚至没有上限。
+
+- 支持二进制储存:*IndexedDB* 不仅可以储存字符串,还可以储存二进制数据(*ArrayBuffer* 对象和 *Blob* 对象)。
+
+*IndexedDB* 主要使用在于客户端需要存储大量的数据的场景下:
+
+- 数据可视化等界面,大量数据,每次请求会消耗很大性能。
+
+- 即时聊天工具,大量消息需要存在本地。
+
+- 其它存储方式容量不满足时,不得已使用 *IndexedDB*
+
+
+
+## *IndexedDB* 重要概念
+
+在正式开始之前,我们先来介绍一下 *IndexedDB* 里面一些重要的概念。
+
+*IndexedDB* 是一个比较复杂的 *API*,涉及不少概念。它把不同的实体,抽象成一个个对象接口。学习这个 *API*,就是学习它的各种对象接口。
+
+- 数据库:*IDBDatabase* 对象
+
+- 对象仓库:*IDBObjectStore* 对象
+
+- 索引:*IDBIndex* 对象
+
+- 事务:*IDBTransaction* 对象
+
+- 操作请求:*IDBRequest* 对象
+
+- 指针:*IDBCursor* 对象
+
+- 主键集合:*IDBKeyRange* 对象
+
+下面是一些主要的概念。
+
+(1)数据库
+
+数据库是一系列相关数据的容器。每个域名(严格的说,是协议 + 域名 + 端口)都可以新建任意多个数据库。
+
+*IndexedDB* 数据库有版本的概念。同一个时刻,只能有一个版本的数据库存在。如果要修改数据库结构(新增或删除表、索引或者主键),只能通过升级数据库版本完成。
+
+(2)对象仓库
+
+每个数据库包含若干个对象仓库( *object store* )。它类似于关系型数据库的表格。
+
+(3)数据记录
+
+对象仓库保存的是数据记录。每条记录类似于关系型数据库的行,但是只有主键和数据体两部分。主键用来建立默认的索引,必须是不同的,否则会报错。主键可以是数据记录里面的一个属性,也可以指定为一个递增的整数编号。
+
+```js
+{ id: 1, text: 'foo' }
+```
+
+上面的对象中,*id* 属性可以当作主键。
+
+数据体可以是任意数据类型,不限于对象。
+
+(4)索引
+
+为了加速数据的检索,可以在对象仓库里面,为不同的属性建立索引。
+
+在关系型数据库当中也有索引的概念,我们可以给对应的表字段添加索引,以便加快查找速率。在 *IndexedDB* 中同样有索引,我们可以在创建 *store* 的时候同时创建索引,在后续对 *store* 进行查询的时候即可通过索引来筛选,给某个字段添加索引后,在后续插入数据的过成功,索引字段便不能为空。
+
+(5)事务
+
+数据记录的读写和删改,都要通过事务完成。事务对象提供 *error、abort* 和 *complete* 三个事件,用来监听操作结果。
+
+(6)指针(游标)
+游标是 *IndexedDB* 数据库新的概念,大家可以把游标想象为一个指针,比如我们要查询满足某一条件的所有数据时,就需要用到游标,我们让游标一行一行的往下走,游标走到的地方便会返回这一行数据,此时我们便可对此行数据进行判断,是否满足条件。
+
+## *IndexedDB* 实操
+
+*IndexedDB* 所有针对仓库的操作都是基于事务的。
+
+在正式开始之前,我们先创建如下的项目结构:
+
+ +
+
+
+该项目目录下存在 *2* 个文件,其中 *db.js* 是用来封装各种数据库操作的。
+
+### 操作数据库
+
+首先第一步是创建以及连接数据库。
+
+*db.js*
+
+```js
+/**
+ * 打开数据库
+ * @param {object} dbName 数据库的名字
+ * @param {string} storeName 仓库名称
+ * @param {string} version 数据库的版本
+ * @return {object} 该函数会返回一个数据库实例
+ */
+function openDB(dbName, version = 1) {
+ return new Promise((resolve, reject) => {
+ var db; // 存储创建的数据库
+ // 打开数据库,若没有则会创建
+ const request = indexedDB.open(dbName, version);
+
+ // 数据库打开成功回调
+ request.onsuccess = function (event) {
+ db = event.target.result; // 存储数据库对象
+ console.log("数据库打开成功");
+ resolve(db);
+ };
+
+ // 数据库打开失败的回调
+ request.onerror = function (event) {
+ console.log("数据库打开报错");
+ };
+
+ // 数据库有更新时候的回调
+ request.onupgradeneeded = function (event) {
+ // 数据库创建或升级的时候会触发
+ console.log("onupgradeneeded");
+ db = event.target.result; // 存储数据库对象
+ var objectStore;
+ // 创建存储库
+ objectStore = db.createObjectStore("stu", {
+ keyPath: "stuId", // 这是主键
+ autoIncrement: true // 实现自增
+ });
+ // 创建索引,在后面查询数据的时候可以根据索引查
+ objectStore.createIndex("stuId", "stuId", { unique: true });
+ objectStore.createIndex("stuName", "stuName", { unique: false });
+ objectStore.createIndex("stuAge", "stuAge", { unique: false });
+ };
+ });
+}
+```
+
+在上面的代码中,我们封装了一个 *openDB* 的函数,该函数调用 *indexedDB.open* 方法来尝试打开一个数据库,如果该数据库不存在,就会创建。
+
+*indexedDB.open* 方法返回一个对象,我们在这个对象上面分别监听了成功、错误以及更新这三个事件。
+
+这里尤其要说一下 *upgradeneeded* 更新事件。该事件会在数据库发生更新时触发,什么叫做数据库有更新时呢?就是添加或删除表,以及数据库版本号更新的时候。
+
+因为一开始创建数据库时,版本是从无到有,所以也会触发这个事件。
+
+*index.html*
+
+```html
+
+
+
+
+```
+
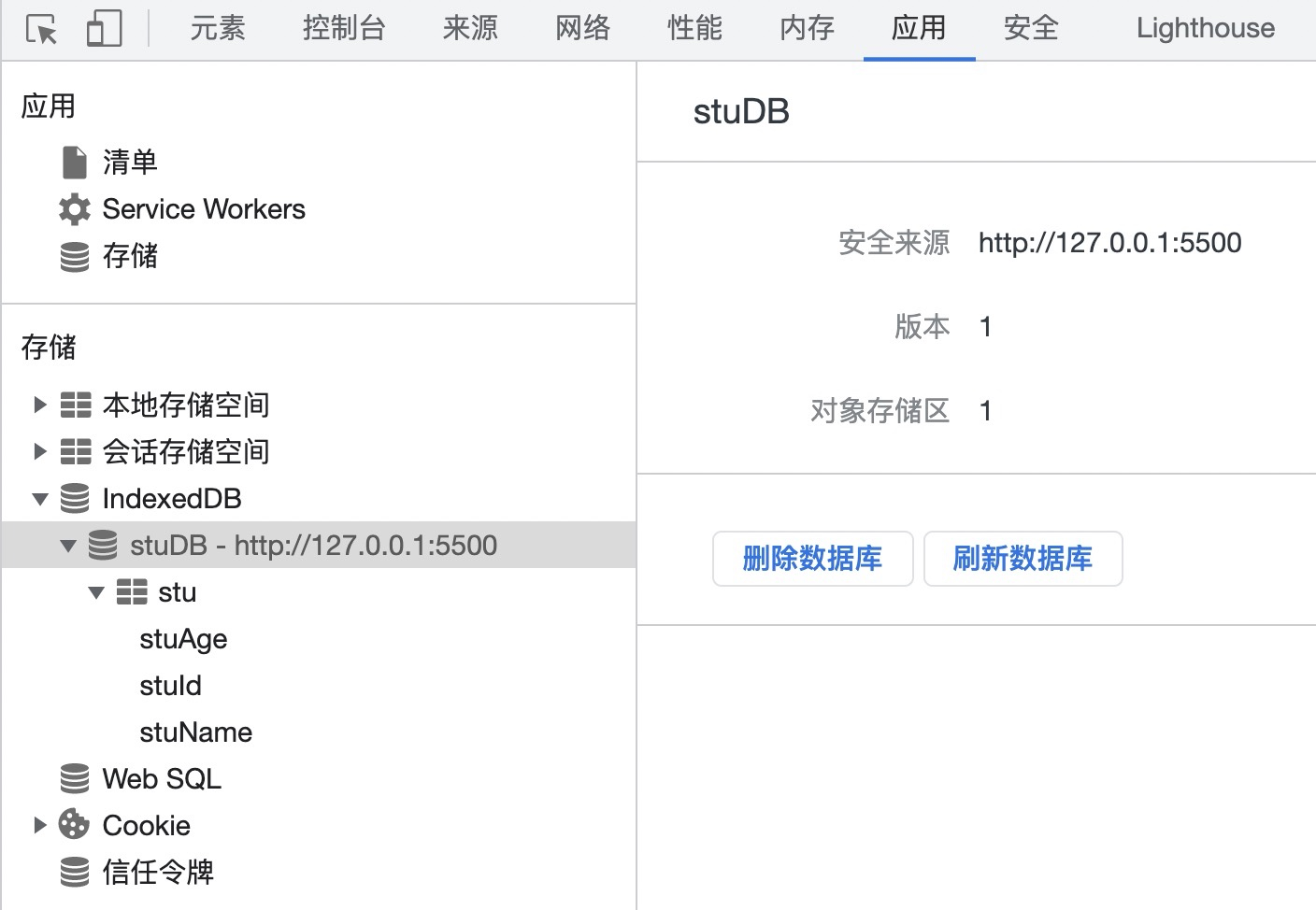
+在 *index.html* 文件中,我们引入了 *db.js*,然后调用了 *openDB* 方法,效果如下图所示。
+
+
+
+
+
+使用完数据库后,建议关闭数据库,以节约资源。
+
+```js
+/**
+ * 关闭数据库
+ * @param {object} db 数据库实例
+ */
+function closeDB(db) {
+ db.close();
+ console.log("数据库已关闭");
+}
+```
+
+如果要删除数据库,可以使用 *indexDB* 的 *deleteDatabase* 方法即可。
+
+```js
+/**
+ * 删除数据库
+ * @param {object} dbName 数据库名称
+ */
+function deleteDBAll(dbName) {
+ console.log(dbName);
+ let deleteRequest = window.indexedDB.deleteDatabase(dbName);
+ deleteRequest.onerror = function (event) {
+ console.log("删除失败");
+ };
+ deleteRequest.onsuccess = function (event) {
+ console.log("删除成功");
+ };
+}
+```
+
+### 插入数据
+
+接下来是插入数据,我们仍然封装一个 *addData* 方法,代码如下:
+
+```js
+/**
+ * 新增数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} data 数据
+ */
+function addData(db, storeName, data) {
+ var request = db
+ .transaction([storeName], "readwrite") // 事务对象 指定表格名称和操作模式("只读"或"读写")
+ .objectStore(storeName) // 仓库对象
+ .add(data);
+
+ request.onsuccess = function (event) {
+ console.log("数据写入成功");
+ };
+
+ request.onerror = function (event) {
+ console.log("数据写入失败");
+ };
+}
+```
+
+*IndexedDB* 插入数据需要通过事务来进行操作,插入的方法也很简单,利用 *IndexedDB* 提供的 *add* 方法即可,这里我们同样将插入数据的操作封装成了一个函数,接收三个参数,分别如下:
+
+- *db*:在创建或连接数据库时,返回的 *db* 实例,需要那个时候保存下来。
+- *storeName*:仓库名称(或者表名),在创建或连接数据库时我们就已经创建好了仓库。
+- *data*:需要插入的数据,通常是一个对象。
+
+接下来我们在 *index.html* 中来测试。
+
+```html
+
+
+
+
+```
+
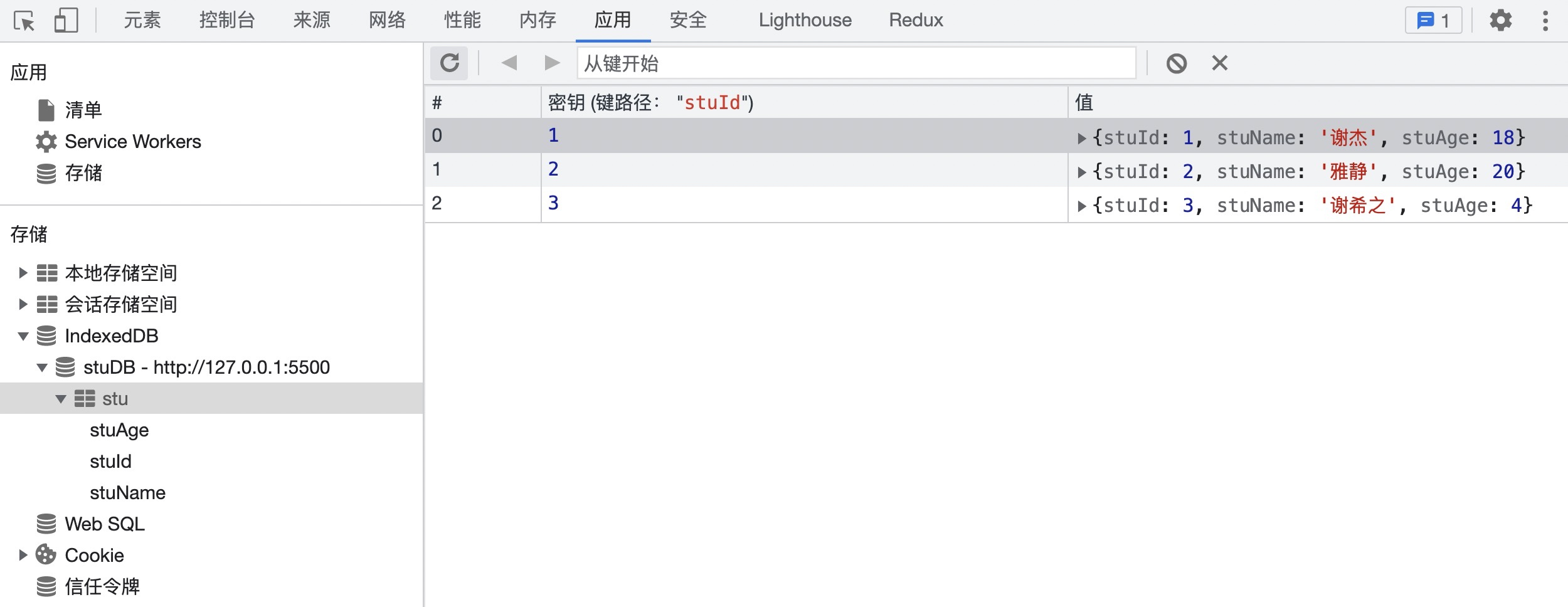
+效果如下:
+
+
+
+
+
+
+
+>注意:插入的数据是一个对象,而且必须包含我们声明的索引键值对。
+
+### 读取数据
+
+读取数据根据需求的不同有不同的读取方式。
+
+### 通过主键读取数据
+
+```js
+/**
+ * 通过主键读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} key 主键值
+ */
+function getDataByKey(db, storeName, key) {
+ return new Promise((resolve, reject) => {
+ var transaction = db.transaction([storeName]); // 事务
+ var objectStore = transaction.objectStore(storeName); // 仓库对象
+ var request = objectStore.get(key); // 通过主键获取数据
+
+ request.onerror = function (event) {
+ console.log("事务失败");
+ };
+
+ request.onsuccess = function (event) {
+ console.log("主键查询结果: ", request.result);
+ resolve(request.result);
+ };
+ });
+}
+```
+
+在我在仓库对象上面调用 *get* 方法从而通过主键获取数据。
+
+*index.html*
+
+```html
+
+
+
+
+```
+
+在 *index.html* 中进行测试,调用上面封装的 *getDataByKey* 方法,可以看到返回了主键 *stuId* 为 *2* 的学生数据。
+
+仓库对象也提供了 *getAll* 方法, 能够查询整张表的数据内容。
+
+*db.js*
+
+```js
+/**
+ * 通过主键读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} key 主键值
+ */
+function getDataByKey(db, storeName, key) {
+ return new Promise((resolve, reject) => {
+ ...
+ var request = objectStore.getAll(); // 通过主键获取数据
+ ...
+ });
+}
+```
+
+在 *index.html* 中调用方法时就需要再传递第三个参数作为 *key* 了。
+
+```js
+openDB('stuDB', 1)
+.then((db) => {
+ addData(db, "stu", { "stuId": 1, "stuName": "谢杰", "stuAge": 18 });
+ addData(db, "stu", { "stuId": 2, "stuName": "雅静", "stuAge": 20 });
+ addData(db, "stu", { "stuId": 3, "stuName": "谢希之", "stuAge": 4 });
+ return getDataByKey(db, "stu");
+}).then((stuInfo)=>{
+ console.log(stuInfo); // 会查询到该表的所有数据
+})
+```
+
+还可以通过指针来进行查询,例如:
+
+```js
+/**
+ * 通过游标读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ */
+function cursorGetData(db, storeName) {
+ return new Promise((resolve, reject) => {
+ let list = [];
+ var store = db
+ .transaction(storeName, "readwrite") // 事务
+ .objectStore(storeName); // 仓库对象
+ var request = store.openCursor(); // 指针对象
+ // 游标开启成功,逐行读数据
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ if (cursor) {
+ // 必须要检查
+ list.push(cursor.value);
+ cursor.continue(); // 遍历了存储对象中的所有内容
+ } else {
+ resolve(list)
+ }
+ };
+ })
+}
+```
+
+在上面的代码中,我们通过仓库对象的 *openCursor* 方法开启了一个指针,这个指针会指向数据表的第一条数据,之后指针逐项进行偏移从而遍历整个数据表。
+
+所以每次偏移拿到数据后,我们 *push* 到 *list* 数组里面,如果某一次没有拿到数据,说明已经读取完了所有的数据,那么我们就返回 *list* 数组。
+
+*indx.html*
+
+```js
+openDB('stuDB', 1)
+.then((db) => {
+ addData(db, "stu", { "stuId": 1, "stuName": "谢杰", "stuAge": 18 });
+ addData(db, "stu", { "stuId": 2, "stuName": "雅静", "stuAge": 20 });
+ addData(db, "stu", { "stuId": 3, "stuName": "谢希之", "stuAge": 4 });
+ return cursorGetData(db, "stu");
+}).then((stuInfo)=>{
+ console.log(stuInfo);
+})
+```
+
+目前为止,我们的精准查询只能通过主键来进行查询。但是更多的场景是我们压根儿就不知道某一条数据的主键。例如我们要查询学生姓名为“张三”的学生数据,对于我们来讲,我们知道的信息只有学生姓名“张三”。
+
+此时我们就可以通过索引来查询数据。
+
+*db.js*
+
+```js
+/**
+ * 通过索引读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ */
+function getDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName);
+ var request = store.index(indexName).get(indexValue);
+ request.onerror = function () {
+ console.log("事务失败");
+ };
+ request.onsuccess = function (e) {
+ var result = e.target.result;
+ resolve(result);
+ };
+ })
+}
+```
+
+在上面的方法中,我们通过仓库对象的 *index* 方法传入了索引名称,然后链式调用 *get* 方法传入索引的值来得到最终的查询结果。
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+.then((db) => {
+ addData(db, "stu", { "stuId": 4, "stuName": "牛牛", "stuAge": 4 });
+ return getDataByIndex(db, "stu", "stuAge", 4);
+}).then((stuInfo) => {
+ console.log(stuInfo); // {stuId: 3, stuName: '谢希之', stuAge: 4}
+})
+```
+
+在 *index.html* 中我们新增了一条数据,年龄也为 *4*,当前的数据库表信息如下:
+
+
+
+
+
+但是很奇怪的是我们查询出来的数据却只有第一条符合要求的。
+
+如果我们想要查询出索引中满足某些条件的所有数据,可以将索引和游标结合起来。
+
+*db.js*
+
+```js
+/**
+ * 通过索引和游标查询记录
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ */
+function cursorGetDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ let list = [];
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName); // 仓库对象
+ var request = store
+ .index(indexName) // 索引对象
+ .openCursor(IDBKeyRange.only(indexValue)); // 指针对象
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ if (cursor) {
+ // 必须要检查
+ list.push(cursor.value);
+ cursor.continue(); // 遍历了存储对象中的所有内容
+ } else {
+ resolve(list)
+ }
+ };
+ request.onerror = function (e) { };
+ })
+}
+```
+
+在上面的方法中,我们仍然是使用仓库对象的 *index* 方法进行索引查询,但是之后链式调用的时候不再是使用 *get* 方法传入索引值,而是调用了 *openCursor* 来打开一个指针,并且让指针指向满足索引值的数据,之后和前面一样,符合要求的数据推入到 *list* 数组,最后返回 *list* 数组。
+
+当然,你可能很好奇 *IDBKeyRange* 的 *only* 方法是什么意思,除了 *only* 方法还有其他方法么?
+
+*IDBKeyRange* 对象代表数据仓库(*object store*)里面的一组主键。根据这组主键,可以获取数据仓库或索引里面的一组记录。
+
+*IDBKeyRange* 可以只包含一个值,也可以指定上限和下限。它有四个静态方法,用来指定主键的范围。
+
+- *IDBKeyRange.lowerBound( )*:指定下限。
+
+- *IDBKeyRange.upperBound( )*:指定上限。
+
+- *IDBKeyRange.bound( )*:同时指定上下限。
+
+- *IDBKeyRange.only( )*:指定只包含一个值。
+
+下面是一些代码实例。
+
+```js
+// All keys ≤ x
+var r1 = IDBKeyRange.upperBound(x);
+
+// All keys < x
+var r2 = IDBKeyRange.upperBound(x, true);
+
+// All keys ≥ y
+var r3 = IDBKeyRange.lowerBound(y);
+
+// All keys > y
+var r4 = IDBKeyRange.lowerBound(y, true);
+
+// All keys ≥ x && ≤ y
+var r5 = IDBKeyRange.bound(x, y);
+
+// All keys > x &&< y
+var r6 = IDBKeyRange.bound(x, y, true, true);
+
+// All keys > x && ≤ y
+var r7 = IDBKeyRange.bound(x, y, true, false);
+
+// All keys ≥ x &&< y
+var r8 = IDBKeyRange.bound(x, y, false, true);
+
+// The key = z
+var r9 = IDBKeyRange.only(z);
+```
+
+例如我们来查询年龄大于 *4* 岁的学生,其代码片段如下:
+
+```js
+function cursorGetDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ ...
+ var request = store
+ .index(indexName) // 索引对象
+ .openCursor(IDBKeyRange.lowerBound(indexValue, true)); // 指针对象
+ ...
+ })
+
+}
+```
+
+利用索引和游标结合查询,我们可以查询出索引值满足我们传入函数值的所有数据对象,而不是只查询出一条数据或者所有数据。
+
+*IndexedDB* 分页查询不像 *MySQL* 分页查询那么简单,没有提供现成的 *API*,如 *limit* 等,所以需要我们自己实现分页。
+
+```js
+/**
+ * 通过索引和游标分页查询记录
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ * @param {number} page 页码
+ * @param {number} pageSize 查询条数
+ */
+function cursorGetDataByIndexAndPage(
+ db,
+ storeName,
+ indexName,
+ indexValue,
+ page,
+ pageSize
+) {
+ return new Promise((resolve, reject) => {
+ var list = [];
+ var counter = 0; // 计数器
+ var advanced = true; // 是否跳过多少条查询
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName); // 仓库对象
+ var request = store
+ // .index(indexName) // 索引对象
+ // .openCursor(IDBKeyRange.only(indexValue)); // 按照指定值分页查询(配合索引)
+ .openCursor(); // 指针对象
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ if (page > 1 && advanced) {
+ advanced = false;
+ cursor.advance((page - 1) * pageSize); // 跳过多少条
+ return;
+ }
+ if (cursor) {
+ // 必须要检查
+ list.push(cursor.value);
+ counter++;
+ if (counter < pageSize) {
+ cursor.continue(); // 遍历了存储对象中的所有内容
+ } else {
+ cursor = null;
+ resolve(list);
+ }
+ } else {
+ resolve(list);
+ }
+ };
+ request.onerror = function (e) { };
+ })
+}
+```
+
+这里用到了 *IndexedDB* 的一个 *API*:*advance*。
+
+该函数可以让我们的游标跳过多少条开始查询。假如我们的额分页是每页 *5* 条数据,现在需要查询第 *2* 页,那么我们就需要跳过前面 *5* 条数据,从第 *6* 条数据开始查询,直到计数器等于 *5*,那么我们就关闭游标,结束查询。
+
+下面在 *index.html* 中进行测试如下:
+
+```html
+
+
+
+
+```
+
+在上面的代码中,我们为了实现分页效果,添加了一些数据。然后查询第 *3* 页的内容。
+
+
+
+查询结果如下:
+
+
+
+
+
+该项目目录下存在 *2* 个文件,其中 *db.js* 是用来封装各种数据库操作的。
+
+### 操作数据库
+
+首先第一步是创建以及连接数据库。
+
+*db.js*
+
+```js
+/**
+ * 打开数据库
+ * @param {object} dbName 数据库的名字
+ * @param {string} storeName 仓库名称
+ * @param {string} version 数据库的版本
+ * @return {object} 该函数会返回一个数据库实例
+ */
+function openDB(dbName, version = 1) {
+ return new Promise((resolve, reject) => {
+ var db; // 存储创建的数据库
+ // 打开数据库,若没有则会创建
+ const request = indexedDB.open(dbName, version);
+
+ // 数据库打开成功回调
+ request.onsuccess = function (event) {
+ db = event.target.result; // 存储数据库对象
+ console.log("数据库打开成功");
+ resolve(db);
+ };
+
+ // 数据库打开失败的回调
+ request.onerror = function (event) {
+ console.log("数据库打开报错");
+ };
+
+ // 数据库有更新时候的回调
+ request.onupgradeneeded = function (event) {
+ // 数据库创建或升级的时候会触发
+ console.log("onupgradeneeded");
+ db = event.target.result; // 存储数据库对象
+ var objectStore;
+ // 创建存储库
+ objectStore = db.createObjectStore("stu", {
+ keyPath: "stuId", // 这是主键
+ autoIncrement: true // 实现自增
+ });
+ // 创建索引,在后面查询数据的时候可以根据索引查
+ objectStore.createIndex("stuId", "stuId", { unique: true });
+ objectStore.createIndex("stuName", "stuName", { unique: false });
+ objectStore.createIndex("stuAge", "stuAge", { unique: false });
+ };
+ });
+}
+```
+
+在上面的代码中,我们封装了一个 *openDB* 的函数,该函数调用 *indexedDB.open* 方法来尝试打开一个数据库,如果该数据库不存在,就会创建。
+
+*indexedDB.open* 方法返回一个对象,我们在这个对象上面分别监听了成功、错误以及更新这三个事件。
+
+这里尤其要说一下 *upgradeneeded* 更新事件。该事件会在数据库发生更新时触发,什么叫做数据库有更新时呢?就是添加或删除表,以及数据库版本号更新的时候。
+
+因为一开始创建数据库时,版本是从无到有,所以也会触发这个事件。
+
+*index.html*
+
+```html
+
+
+
+
+```
+
+在 *index.html* 文件中,我们引入了 *db.js*,然后调用了 *openDB* 方法,效果如下图所示。
+
+
+
+
+
+使用完数据库后,建议关闭数据库,以节约资源。
+
+```js
+/**
+ * 关闭数据库
+ * @param {object} db 数据库实例
+ */
+function closeDB(db) {
+ db.close();
+ console.log("数据库已关闭");
+}
+```
+
+如果要删除数据库,可以使用 *indexDB* 的 *deleteDatabase* 方法即可。
+
+```js
+/**
+ * 删除数据库
+ * @param {object} dbName 数据库名称
+ */
+function deleteDBAll(dbName) {
+ console.log(dbName);
+ let deleteRequest = window.indexedDB.deleteDatabase(dbName);
+ deleteRequest.onerror = function (event) {
+ console.log("删除失败");
+ };
+ deleteRequest.onsuccess = function (event) {
+ console.log("删除成功");
+ };
+}
+```
+
+### 插入数据
+
+接下来是插入数据,我们仍然封装一个 *addData* 方法,代码如下:
+
+```js
+/**
+ * 新增数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} data 数据
+ */
+function addData(db, storeName, data) {
+ var request = db
+ .transaction([storeName], "readwrite") // 事务对象 指定表格名称和操作模式("只读"或"读写")
+ .objectStore(storeName) // 仓库对象
+ .add(data);
+
+ request.onsuccess = function (event) {
+ console.log("数据写入成功");
+ };
+
+ request.onerror = function (event) {
+ console.log("数据写入失败");
+ };
+}
+```
+
+*IndexedDB* 插入数据需要通过事务来进行操作,插入的方法也很简单,利用 *IndexedDB* 提供的 *add* 方法即可,这里我们同样将插入数据的操作封装成了一个函数,接收三个参数,分别如下:
+
+- *db*:在创建或连接数据库时,返回的 *db* 实例,需要那个时候保存下来。
+- *storeName*:仓库名称(或者表名),在创建或连接数据库时我们就已经创建好了仓库。
+- *data*:需要插入的数据,通常是一个对象。
+
+接下来我们在 *index.html* 中来测试。
+
+```html
+
+
+
+
+```
+
+效果如下:
+
+
+
+
+
+
+
+>注意:插入的数据是一个对象,而且必须包含我们声明的索引键值对。
+
+### 读取数据
+
+读取数据根据需求的不同有不同的读取方式。
+
+### 通过主键读取数据
+
+```js
+/**
+ * 通过主键读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} key 主键值
+ */
+function getDataByKey(db, storeName, key) {
+ return new Promise((resolve, reject) => {
+ var transaction = db.transaction([storeName]); // 事务
+ var objectStore = transaction.objectStore(storeName); // 仓库对象
+ var request = objectStore.get(key); // 通过主键获取数据
+
+ request.onerror = function (event) {
+ console.log("事务失败");
+ };
+
+ request.onsuccess = function (event) {
+ console.log("主键查询结果: ", request.result);
+ resolve(request.result);
+ };
+ });
+}
+```
+
+在我在仓库对象上面调用 *get* 方法从而通过主键获取数据。
+
+*index.html*
+
+```html
+
+
+
+
+```
+
+在 *index.html* 中进行测试,调用上面封装的 *getDataByKey* 方法,可以看到返回了主键 *stuId* 为 *2* 的学生数据。
+
+仓库对象也提供了 *getAll* 方法, 能够查询整张表的数据内容。
+
+*db.js*
+
+```js
+/**
+ * 通过主键读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} key 主键值
+ */
+function getDataByKey(db, storeName, key) {
+ return new Promise((resolve, reject) => {
+ ...
+ var request = objectStore.getAll(); // 通过主键获取数据
+ ...
+ });
+}
+```
+
+在 *index.html* 中调用方法时就需要再传递第三个参数作为 *key* 了。
+
+```js
+openDB('stuDB', 1)
+.then((db) => {
+ addData(db, "stu", { "stuId": 1, "stuName": "谢杰", "stuAge": 18 });
+ addData(db, "stu", { "stuId": 2, "stuName": "雅静", "stuAge": 20 });
+ addData(db, "stu", { "stuId": 3, "stuName": "谢希之", "stuAge": 4 });
+ return getDataByKey(db, "stu");
+}).then((stuInfo)=>{
+ console.log(stuInfo); // 会查询到该表的所有数据
+})
+```
+
+还可以通过指针来进行查询,例如:
+
+```js
+/**
+ * 通过游标读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ */
+function cursorGetData(db, storeName) {
+ return new Promise((resolve, reject) => {
+ let list = [];
+ var store = db
+ .transaction(storeName, "readwrite") // 事务
+ .objectStore(storeName); // 仓库对象
+ var request = store.openCursor(); // 指针对象
+ // 游标开启成功,逐行读数据
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ if (cursor) {
+ // 必须要检查
+ list.push(cursor.value);
+ cursor.continue(); // 遍历了存储对象中的所有内容
+ } else {
+ resolve(list)
+ }
+ };
+ })
+}
+```
+
+在上面的代码中,我们通过仓库对象的 *openCursor* 方法开启了一个指针,这个指针会指向数据表的第一条数据,之后指针逐项进行偏移从而遍历整个数据表。
+
+所以每次偏移拿到数据后,我们 *push* 到 *list* 数组里面,如果某一次没有拿到数据,说明已经读取完了所有的数据,那么我们就返回 *list* 数组。
+
+*indx.html*
+
+```js
+openDB('stuDB', 1)
+.then((db) => {
+ addData(db, "stu", { "stuId": 1, "stuName": "谢杰", "stuAge": 18 });
+ addData(db, "stu", { "stuId": 2, "stuName": "雅静", "stuAge": 20 });
+ addData(db, "stu", { "stuId": 3, "stuName": "谢希之", "stuAge": 4 });
+ return cursorGetData(db, "stu");
+}).then((stuInfo)=>{
+ console.log(stuInfo);
+})
+```
+
+目前为止,我们的精准查询只能通过主键来进行查询。但是更多的场景是我们压根儿就不知道某一条数据的主键。例如我们要查询学生姓名为“张三”的学生数据,对于我们来讲,我们知道的信息只有学生姓名“张三”。
+
+此时我们就可以通过索引来查询数据。
+
+*db.js*
+
+```js
+/**
+ * 通过索引读取数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ */
+function getDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName);
+ var request = store.index(indexName).get(indexValue);
+ request.onerror = function () {
+ console.log("事务失败");
+ };
+ request.onsuccess = function (e) {
+ var result = e.target.result;
+ resolve(result);
+ };
+ })
+}
+```
+
+在上面的方法中,我们通过仓库对象的 *index* 方法传入了索引名称,然后链式调用 *get* 方法传入索引的值来得到最终的查询结果。
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+.then((db) => {
+ addData(db, "stu", { "stuId": 4, "stuName": "牛牛", "stuAge": 4 });
+ return getDataByIndex(db, "stu", "stuAge", 4);
+}).then((stuInfo) => {
+ console.log(stuInfo); // {stuId: 3, stuName: '谢希之', stuAge: 4}
+})
+```
+
+在 *index.html* 中我们新增了一条数据,年龄也为 *4*,当前的数据库表信息如下:
+
+
+
+
+
+但是很奇怪的是我们查询出来的数据却只有第一条符合要求的。
+
+如果我们想要查询出索引中满足某些条件的所有数据,可以将索引和游标结合起来。
+
+*db.js*
+
+```js
+/**
+ * 通过索引和游标查询记录
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ */
+function cursorGetDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ let list = [];
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName); // 仓库对象
+ var request = store
+ .index(indexName) // 索引对象
+ .openCursor(IDBKeyRange.only(indexValue)); // 指针对象
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ if (cursor) {
+ // 必须要检查
+ list.push(cursor.value);
+ cursor.continue(); // 遍历了存储对象中的所有内容
+ } else {
+ resolve(list)
+ }
+ };
+ request.onerror = function (e) { };
+ })
+}
+```
+
+在上面的方法中,我们仍然是使用仓库对象的 *index* 方法进行索引查询,但是之后链式调用的时候不再是使用 *get* 方法传入索引值,而是调用了 *openCursor* 来打开一个指针,并且让指针指向满足索引值的数据,之后和前面一样,符合要求的数据推入到 *list* 数组,最后返回 *list* 数组。
+
+当然,你可能很好奇 *IDBKeyRange* 的 *only* 方法是什么意思,除了 *only* 方法还有其他方法么?
+
+*IDBKeyRange* 对象代表数据仓库(*object store*)里面的一组主键。根据这组主键,可以获取数据仓库或索引里面的一组记录。
+
+*IDBKeyRange* 可以只包含一个值,也可以指定上限和下限。它有四个静态方法,用来指定主键的范围。
+
+- *IDBKeyRange.lowerBound( )*:指定下限。
+
+- *IDBKeyRange.upperBound( )*:指定上限。
+
+- *IDBKeyRange.bound( )*:同时指定上下限。
+
+- *IDBKeyRange.only( )*:指定只包含一个值。
+
+下面是一些代码实例。
+
+```js
+// All keys ≤ x
+var r1 = IDBKeyRange.upperBound(x);
+
+// All keys < x
+var r2 = IDBKeyRange.upperBound(x, true);
+
+// All keys ≥ y
+var r3 = IDBKeyRange.lowerBound(y);
+
+// All keys > y
+var r4 = IDBKeyRange.lowerBound(y, true);
+
+// All keys ≥ x && ≤ y
+var r5 = IDBKeyRange.bound(x, y);
+
+// All keys > x &&< y
+var r6 = IDBKeyRange.bound(x, y, true, true);
+
+// All keys > x && ≤ y
+var r7 = IDBKeyRange.bound(x, y, true, false);
+
+// All keys ≥ x &&< y
+var r8 = IDBKeyRange.bound(x, y, false, true);
+
+// The key = z
+var r9 = IDBKeyRange.only(z);
+```
+
+例如我们来查询年龄大于 *4* 岁的学生,其代码片段如下:
+
+```js
+function cursorGetDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ ...
+ var request = store
+ .index(indexName) // 索引对象
+ .openCursor(IDBKeyRange.lowerBound(indexValue, true)); // 指针对象
+ ...
+ })
+
+}
+```
+
+利用索引和游标结合查询,我们可以查询出索引值满足我们传入函数值的所有数据对象,而不是只查询出一条数据或者所有数据。
+
+*IndexedDB* 分页查询不像 *MySQL* 分页查询那么简单,没有提供现成的 *API*,如 *limit* 等,所以需要我们自己实现分页。
+
+```js
+/**
+ * 通过索引和游标分页查询记录
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ * @param {number} page 页码
+ * @param {number} pageSize 查询条数
+ */
+function cursorGetDataByIndexAndPage(
+ db,
+ storeName,
+ indexName,
+ indexValue,
+ page,
+ pageSize
+) {
+ return new Promise((resolve, reject) => {
+ var list = [];
+ var counter = 0; // 计数器
+ var advanced = true; // 是否跳过多少条查询
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName); // 仓库对象
+ var request = store
+ // .index(indexName) // 索引对象
+ // .openCursor(IDBKeyRange.only(indexValue)); // 按照指定值分页查询(配合索引)
+ .openCursor(); // 指针对象
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ if (page > 1 && advanced) {
+ advanced = false;
+ cursor.advance((page - 1) * pageSize); // 跳过多少条
+ return;
+ }
+ if (cursor) {
+ // 必须要检查
+ list.push(cursor.value);
+ counter++;
+ if (counter < pageSize) {
+ cursor.continue(); // 遍历了存储对象中的所有内容
+ } else {
+ cursor = null;
+ resolve(list);
+ }
+ } else {
+ resolve(list);
+ }
+ };
+ request.onerror = function (e) { };
+ })
+}
+```
+
+这里用到了 *IndexedDB* 的一个 *API*:*advance*。
+
+该函数可以让我们的游标跳过多少条开始查询。假如我们的额分页是每页 *5* 条数据,现在需要查询第 *2* 页,那么我们就需要跳过前面 *5* 条数据,从第 *6* 条数据开始查询,直到计数器等于 *5*,那么我们就关闭游标,结束查询。
+
+下面在 *index.html* 中进行测试如下:
+
+```html
+
+
+
+
+```
+
+在上面的代码中,我们为了实现分页效果,添加了一些数据。然后查询第 *3* 页的内容。
+
+
+
+查询结果如下:
+
+ +
+### 更新数据
+
+*IndexedDB* 更新数据较为简单,直接使用 *put* 方法,值得注意的是如果数据库中没有该条数据,则会默认增加该条数据,否则更新。
+
+有些小伙伴喜欢更新和新增都是用 *put* 方法,这也是可行的。
+
+*db.js*
+
+```js
+/**
+ * 更新数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {object} data 数据
+ */
+function updateDB(db, storeName, data) {
+ return new Promise((resolve, reject) => {
+ var request = db
+ .transaction([storeName], "readwrite") // 事务对象
+ .objectStore(storeName) // 仓库对象
+ .put(data);
+
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "更新数据成功"
+ })
+ };
+
+ request.onerror = function () {
+ reject({
+ status: false,
+ message: "更新数据失败"
+ })
+ };
+ })
+}
+```
+
+在上面的方法中,我们使用仓库对象的 *put* 方法来修改数据,所以在调用该方法时,需要传入整条数据对象,特别是主键。因为是通过主键来查询到要修改的数据。
+
+如果传入的数据没有主键,则是一个新增数据的效果。
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+ .then((db) => {
+ return updateDB(db, "stu", {stuId: 1, stuName: '谢杰2', stuAge: 19});
+ }).then(({message}) => {
+ console.log(message);
+ })
+```
+
+效果如下:
+
+
+
+
+
+### 删除数据
+
+删除数据这里记录 *2* 种方式,一个是通过主键来进行删除。
+
+*db.js*
+
+```js
+/**
+ * 通过主键删除数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {object} id 主键值
+ */
+function deleteDB(db, storeName, id) {
+ return new Promise((resolve, reject) => {
+ var request = db
+ .transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .delete(id);
+
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "删除数据成功"
+ })
+ };
+
+ request.onerror = function () {
+ reject({
+ status: true,
+ message: "删除数据失败"
+ })
+ };
+ })
+}
+```
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+ .then((db) => {
+ return deleteDB(db, "stu", 1)
+ }).then(({message}) => {
+ console.log(message);
+ })
+```
+
+执行上面的代码后 *stuId* 为 *1* 的学生被删除掉。
+
+有时候我们拿不到主键值,只能只能通过索引值来删除。通过这种方式,我们可以删除一条数据(索引值唯一)或者所有满足条件的数据(索引值不唯一)。
+
+*db.js*
+
+```js
+/**
+ * 通过索引和游标删除指定的数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名
+ * @param {object} indexValue 索引值
+ */
+function cursorDelete(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName);
+ var request = store
+ .index(indexName) // 索引对象
+ .openCursor(IDBKeyRange.only(indexValue)); // 指针对象
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ var deleteRequest;
+ if (cursor) {
+ deleteRequest = cursor.delete(); // 请求删除当前项
+ deleteRequest.onsuccess = function () {
+ console.log("游标删除该记录成功");
+ resolve({
+ status: true,
+ message: "游标删除该记录成功"
+ })
+ };
+ deleteRequest.onerror = function () {
+ reject({
+ status: false,
+ message: "游标删除该记录失败"
+ })
+ };
+ cursor.continue();
+ }
+ };
+ request.onerror = function (e) { };
+ })
+}
+```
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+ .then((db) => {
+ return cursorDelete(db, "stu", "stuName", "雅静")
+ }).then(({ message }) => {
+ console.log(message);
+ })
+```
+
+在上面的示例中,我们就删除了所有 *stuName* 值为 “雅静” 的同学。
+
+
+-------
+
+以上,就是关于 *IndexedDB* 的基本操作。
+
+可以看到,在了解了它的几个基本概念后,上手还是比较容易的。
+
+另外由于 *IndexedDB* 所提供的原生 *API* 比较复杂,所以现在也出现了基于 *IndexedDB* 封装的库。例如 *Dexie.js*。
+
+
+
+(图为 *Dexie.js* 官网部分截图)
+
+
+
+*Dexie.js* 官网:*https://dexie.org/*
+
+
+
+该库和 *IndexedDB* 之间的关系,就类似于 *jQuery* 和 *JavaScript* 之间的关系。有兴趣的同学可以自行进行研究,这里就不再做过多的赘述。
+
+
+
+如果想了解 *IndexedDB* 相关的更多 *API*,可以扩展阅读:*https://www.wangdoc.com/javascript/bom/indexeddb.html*
+
+
+-------
+
+
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/IndexedDB课堂代码/.vscode/settings.json b/04. 浏览器的离线存储/IndexedDB课堂代码/.vscode/settings.json
new file mode 100644
index 0000000..5165b7c
--- /dev/null
+++ b/04. 浏览器的离线存储/IndexedDB课堂代码/.vscode/settings.json
@@ -0,0 +1,3 @@
+{
+ "eggHelper.serverPort": 35684
+}
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/IndexedDB课堂代码/db.js b/04. 浏览器的离线存储/IndexedDB课堂代码/db.js
new file mode 100644
index 0000000..aaafcdf
--- /dev/null
+++ b/04. 浏览器的离线存储/IndexedDB课堂代码/db.js
@@ -0,0 +1,330 @@
+
+/**
+ *
+ * @param {*} dbName 数据库名称
+ * @param {*} version 数据库的版本
+ */
+function openDB(dbName, version = 1) {
+ return new Promise((resolve, reject) => {
+ var db; // 存储数据库对象
+ // 打开数据库,如果没有就是创建操作
+ var request = indexedDB.open(dbName, version);
+
+ // 数据库打开或者创建成功的时候
+ request.onsuccess = function (event) {
+ db = event.target.result;
+ console.log("数据库打开成功");
+ resolve(db);
+ }
+
+ // 打开失败
+ request.onerror = function () {
+ console.log("数据库打开失败");
+ }
+
+ // 数据库发生更新的时候
+ // 1. 版本号更新 2. 添加或者删除了表(对象仓库)的时候
+ // 当我们第一次调用 open 方法时,会触发这个事件
+ // 我们在这里来初始化我们的表
+ request.onupgradeneeded = function (event) {
+ console.log("数据库版本更新");
+ db = event.target.result;
+ // 创建数据仓库(表)
+ var objectStore = db.createObjectStore("stu", {
+ keyPath: "stuId", // 这是主键
+ autoIncrement: true // 实现自增
+ });
+ // 创建索引,有了索引之后,查询速度大大增快(类比新华字典)
+ objectStore.createIndex("stuId", "stuId", { unique: true });
+ objectStore.createIndex("stuName", "stuName", { unique: false });
+ objectStore.createIndex("stuAge", "stuAge", { unique: false });
+ }
+ })
+}
+
+/**
+ * 关闭数据库
+ * @param {object} db 数据库实例
+ */
+function closeDB(db) {
+ db.close();
+ console.log("数据库已关闭");
+}
+
+/**
+* 删除数据库
+* @param {object} dbName 数据库名称
+*/
+function deleteDBAll(dbName) {
+ console.log(dbName);
+ let deleteRequest = window.indexedDB.deleteDatabase(dbName);
+ deleteRequest.onerror = function (event) {
+ console.log("删除失败");
+ };
+ deleteRequest.onsuccess = function (event) {
+ console.log("删除成功");
+ };
+}
+
+
+/**
+ *
+ * @param {*} db 数据库实例
+ * @param {*} storeName 数据仓库实例(表)
+ * @param {*} data 要添加的数据
+ */
+function addData(db, storeName, data) {
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .add(data);
+
+ request.onsuccess = function () {
+ console.log("数据写入成功");
+ }
+
+ request.onerror = function () {
+ console.log("数据写入失败")
+ }
+}
+
+/**
+ * 通过主键来读取数据
+ * @param {*} db 数据库实例对象
+ * @param {*} storeName 数据仓库(表)实例对象
+ * @param {*} key 主键
+ */
+function getDataByKey(db, storeName, key) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName])
+ .objectStore(storeName)
+ .get(key);
+
+ request.onsuccess = function () {
+ resolve(request.result)
+ }
+
+ request.onerror = function () {
+ console.log("数据查询失败");
+ }
+ })
+}
+
+/**
+ * 通过主键来读取数据
+ * @param {*} db 数据库实例对象
+ * @param {*} storeName 数据仓库(表)实例对象
+ */
+function getAllData(db, storeName) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName])
+ .objectStore(storeName)
+ .getAll();
+
+ request.onsuccess = function () {
+ resolve(request.result)
+ }
+
+ request.onerror = function () {
+ console.log("数据查询失败");
+ }
+ })
+}
+
+/**
+ * 通过游标(指针)来查询所有的数据
+ * @param {*} db
+ * @param {*} storeName
+ */
+function cursorGetData(db, storeName) {
+ return new Promise((resolve, reject) => {
+ var list = []; // 用于存放所有的数据
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .openCursor(); // 创建一个指针(游标)
+
+ request.onsuccess = function (event) {
+ var cursor = event.target.result;
+ // 查看游标(指针)有没有返回一条数据
+ if (cursor) {
+ list.push(cursor.value);
+ cursor.continue(); // 移动到下一条数据
+ } else {
+ resolve(list)
+ }
+ }
+ })
+}
+
+/**
+ * 根据索引来查询数据(只会返回一条)
+ * @param {*} db
+ * @param {*} storeName
+ * @param {*} indexName 索引名称
+ * @param {*} indexValue 索引值
+ */
+function getDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .index(indexName)
+ .get(indexValue);
+
+ request.onsuccess = function (event) {
+ resolve(event.target.result);
+ }
+ })
+}
+
+/**
+ * 根据索引和游标来查询数据
+ * @param {*} db
+ * @param {*} storeName
+ * @param {*} indexName 索引名称
+ * @param {*} indexValue 索引值
+ */
+function getDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var list = []; // 存储所有满足条件的数据
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .index(indexName)
+ .openCursor(IDBKeyRange.lowerBound(indexValue));
+
+ request.onsuccess = function (event) {
+ var cursor = event.target.result;
+ if (cursor) {
+ list.push(cursor.value);
+ cursor.continue();
+ } else {
+ resolve(list);
+ }
+ }
+ })
+}
+
+/**
+ * 通过索引和游标分页查询记录
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ * @param {number} page 页码
+ * @param {number} pageSize 查询条数
+ */
+function cursorGetDataByIndexAndPage(
+ db,
+ storeName,
+ indexName,
+ indexValue,
+ page,
+ pageSize
+) {
+ return new Promise((resolve, reject) => {
+ var list = []; // 用于存储当前页的分页数据
+ var counter = 0; // 创建一个计数器
+ var isPass = true; // 是否要跳过数据
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .openCursor(); // 创建一个指针(游标)对象(目前是指向第一条数据)
+ request.onsuccess = function (event) {
+ var cursor = event.target.result;
+ // 接下来有一个很重要的判断,判断是否要跳过一些数据
+ if (page > 1 && isPass) {
+ isPass = false;
+ cursor.advance((page - 1) * pageSize); // 跳过数据
+ return;
+ }
+ if (cursor) {
+ list.push(cursor.value);
+ counter++;
+ if (counter < pageSize) {
+ cursor.continue();
+ } else {
+ cursor = null;
+ resolve(list);
+ }
+ } else {
+ resolve(list)
+ }
+ }
+ })
+}
+
+/**
+ * 更新数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {object} data 数据
+ */
+function updateDB(db, storeName, data) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .put(data);
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "更新数据成功"
+ })
+ }
+ })
+}
+
+/**
+* 通过主键删除数据
+* @param {object} db 数据库实例
+* @param {string} storeName 仓库名称
+* @param {object} id 主键值
+*/
+function deleteDB(db, storeName, id) {
+ return new Promise((resolve, reject) => {
+ var request = db
+ .transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .delete(id);
+
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "删除数据成功"
+ })
+ };
+
+ request.onerror = function () {
+ reject({
+ status: true,
+ message: "删除数据失败"
+ })
+ };
+ })
+}
+
+
+/**
+ * 通过索引和游标删除指定的数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名
+ * @param {object} indexValue 索引值
+ */
+ function cursorDelete(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject)=>{
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .index(indexName)
+ .openCursor(IDBKeyRange.only(indexValue));
+ request.onsuccess = function(event){
+ var cursor = event.target.result;
+ if(cursor){
+ var deleteRequest = cursor.delete();
+ deleteRequest.onsuccess = function(){
+ resolve({
+ status: true,
+ message: "删除数据成功"
+ })
+ }
+ cursor.continue();
+ }
+ }
+ })
+ }
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/IndexedDB课堂代码/index.html b/04. 浏览器的离线存储/IndexedDB课堂代码/index.html
new file mode 100644
index 0000000..b0a6e39
--- /dev/null
+++ b/04. 浏览器的离线存储/IndexedDB课堂代码/index.html
@@ -0,0 +1,63 @@
+
+
+
+
+
+
+
+
+
+### 更新数据
+
+*IndexedDB* 更新数据较为简单,直接使用 *put* 方法,值得注意的是如果数据库中没有该条数据,则会默认增加该条数据,否则更新。
+
+有些小伙伴喜欢更新和新增都是用 *put* 方法,这也是可行的。
+
+*db.js*
+
+```js
+/**
+ * 更新数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {object} data 数据
+ */
+function updateDB(db, storeName, data) {
+ return new Promise((resolve, reject) => {
+ var request = db
+ .transaction([storeName], "readwrite") // 事务对象
+ .objectStore(storeName) // 仓库对象
+ .put(data);
+
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "更新数据成功"
+ })
+ };
+
+ request.onerror = function () {
+ reject({
+ status: false,
+ message: "更新数据失败"
+ })
+ };
+ })
+}
+```
+
+在上面的方法中,我们使用仓库对象的 *put* 方法来修改数据,所以在调用该方法时,需要传入整条数据对象,特别是主键。因为是通过主键来查询到要修改的数据。
+
+如果传入的数据没有主键,则是一个新增数据的效果。
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+ .then((db) => {
+ return updateDB(db, "stu", {stuId: 1, stuName: '谢杰2', stuAge: 19});
+ }).then(({message}) => {
+ console.log(message);
+ })
+```
+
+效果如下:
+
+
+
+
+
+### 删除数据
+
+删除数据这里记录 *2* 种方式,一个是通过主键来进行删除。
+
+*db.js*
+
+```js
+/**
+ * 通过主键删除数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {object} id 主键值
+ */
+function deleteDB(db, storeName, id) {
+ return new Promise((resolve, reject) => {
+ var request = db
+ .transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .delete(id);
+
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "删除数据成功"
+ })
+ };
+
+ request.onerror = function () {
+ reject({
+ status: true,
+ message: "删除数据失败"
+ })
+ };
+ })
+}
+```
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+ .then((db) => {
+ return deleteDB(db, "stu", 1)
+ }).then(({message}) => {
+ console.log(message);
+ })
+```
+
+执行上面的代码后 *stuId* 为 *1* 的学生被删除掉。
+
+有时候我们拿不到主键值,只能只能通过索引值来删除。通过这种方式,我们可以删除一条数据(索引值唯一)或者所有满足条件的数据(索引值不唯一)。
+
+*db.js*
+
+```js
+/**
+ * 通过索引和游标删除指定的数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名
+ * @param {object} indexValue 索引值
+ */
+function cursorDelete(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var store = db.transaction(storeName, "readwrite").objectStore(storeName);
+ var request = store
+ .index(indexName) // 索引对象
+ .openCursor(IDBKeyRange.only(indexValue)); // 指针对象
+ request.onsuccess = function (e) {
+ var cursor = e.target.result;
+ var deleteRequest;
+ if (cursor) {
+ deleteRequest = cursor.delete(); // 请求删除当前项
+ deleteRequest.onsuccess = function () {
+ console.log("游标删除该记录成功");
+ resolve({
+ status: true,
+ message: "游标删除该记录成功"
+ })
+ };
+ deleteRequest.onerror = function () {
+ reject({
+ status: false,
+ message: "游标删除该记录失败"
+ })
+ };
+ cursor.continue();
+ }
+ };
+ request.onerror = function (e) { };
+ })
+}
+```
+
+*index.html*
+
+```js
+openDB('stuDB', 1)
+ .then((db) => {
+ return cursorDelete(db, "stu", "stuName", "雅静")
+ }).then(({ message }) => {
+ console.log(message);
+ })
+```
+
+在上面的示例中,我们就删除了所有 *stuName* 值为 “雅静” 的同学。
+
+
+-------
+
+以上,就是关于 *IndexedDB* 的基本操作。
+
+可以看到,在了解了它的几个基本概念后,上手还是比较容易的。
+
+另外由于 *IndexedDB* 所提供的原生 *API* 比较复杂,所以现在也出现了基于 *IndexedDB* 封装的库。例如 *Dexie.js*。
+
+
+
+(图为 *Dexie.js* 官网部分截图)
+
+
+
+*Dexie.js* 官网:*https://dexie.org/*
+
+
+
+该库和 *IndexedDB* 之间的关系,就类似于 *jQuery* 和 *JavaScript* 之间的关系。有兴趣的同学可以自行进行研究,这里就不再做过多的赘述。
+
+
+
+如果想了解 *IndexedDB* 相关的更多 *API*,可以扩展阅读:*https://www.wangdoc.com/javascript/bom/indexeddb.html*
+
+
+-------
+
+
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/IndexedDB课堂代码/.vscode/settings.json b/04. 浏览器的离线存储/IndexedDB课堂代码/.vscode/settings.json
new file mode 100644
index 0000000..5165b7c
--- /dev/null
+++ b/04. 浏览器的离线存储/IndexedDB课堂代码/.vscode/settings.json
@@ -0,0 +1,3 @@
+{
+ "eggHelper.serverPort": 35684
+}
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/IndexedDB课堂代码/db.js b/04. 浏览器的离线存储/IndexedDB课堂代码/db.js
new file mode 100644
index 0000000..aaafcdf
--- /dev/null
+++ b/04. 浏览器的离线存储/IndexedDB课堂代码/db.js
@@ -0,0 +1,330 @@
+
+/**
+ *
+ * @param {*} dbName 数据库名称
+ * @param {*} version 数据库的版本
+ */
+function openDB(dbName, version = 1) {
+ return new Promise((resolve, reject) => {
+ var db; // 存储数据库对象
+ // 打开数据库,如果没有就是创建操作
+ var request = indexedDB.open(dbName, version);
+
+ // 数据库打开或者创建成功的时候
+ request.onsuccess = function (event) {
+ db = event.target.result;
+ console.log("数据库打开成功");
+ resolve(db);
+ }
+
+ // 打开失败
+ request.onerror = function () {
+ console.log("数据库打开失败");
+ }
+
+ // 数据库发生更新的时候
+ // 1. 版本号更新 2. 添加或者删除了表(对象仓库)的时候
+ // 当我们第一次调用 open 方法时,会触发这个事件
+ // 我们在这里来初始化我们的表
+ request.onupgradeneeded = function (event) {
+ console.log("数据库版本更新");
+ db = event.target.result;
+ // 创建数据仓库(表)
+ var objectStore = db.createObjectStore("stu", {
+ keyPath: "stuId", // 这是主键
+ autoIncrement: true // 实现自增
+ });
+ // 创建索引,有了索引之后,查询速度大大增快(类比新华字典)
+ objectStore.createIndex("stuId", "stuId", { unique: true });
+ objectStore.createIndex("stuName", "stuName", { unique: false });
+ objectStore.createIndex("stuAge", "stuAge", { unique: false });
+ }
+ })
+}
+
+/**
+ * 关闭数据库
+ * @param {object} db 数据库实例
+ */
+function closeDB(db) {
+ db.close();
+ console.log("数据库已关闭");
+}
+
+/**
+* 删除数据库
+* @param {object} dbName 数据库名称
+*/
+function deleteDBAll(dbName) {
+ console.log(dbName);
+ let deleteRequest = window.indexedDB.deleteDatabase(dbName);
+ deleteRequest.onerror = function (event) {
+ console.log("删除失败");
+ };
+ deleteRequest.onsuccess = function (event) {
+ console.log("删除成功");
+ };
+}
+
+
+/**
+ *
+ * @param {*} db 数据库实例
+ * @param {*} storeName 数据仓库实例(表)
+ * @param {*} data 要添加的数据
+ */
+function addData(db, storeName, data) {
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .add(data);
+
+ request.onsuccess = function () {
+ console.log("数据写入成功");
+ }
+
+ request.onerror = function () {
+ console.log("数据写入失败")
+ }
+}
+
+/**
+ * 通过主键来读取数据
+ * @param {*} db 数据库实例对象
+ * @param {*} storeName 数据仓库(表)实例对象
+ * @param {*} key 主键
+ */
+function getDataByKey(db, storeName, key) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName])
+ .objectStore(storeName)
+ .get(key);
+
+ request.onsuccess = function () {
+ resolve(request.result)
+ }
+
+ request.onerror = function () {
+ console.log("数据查询失败");
+ }
+ })
+}
+
+/**
+ * 通过主键来读取数据
+ * @param {*} db 数据库实例对象
+ * @param {*} storeName 数据仓库(表)实例对象
+ */
+function getAllData(db, storeName) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName])
+ .objectStore(storeName)
+ .getAll();
+
+ request.onsuccess = function () {
+ resolve(request.result)
+ }
+
+ request.onerror = function () {
+ console.log("数据查询失败");
+ }
+ })
+}
+
+/**
+ * 通过游标(指针)来查询所有的数据
+ * @param {*} db
+ * @param {*} storeName
+ */
+function cursorGetData(db, storeName) {
+ return new Promise((resolve, reject) => {
+ var list = []; // 用于存放所有的数据
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .openCursor(); // 创建一个指针(游标)
+
+ request.onsuccess = function (event) {
+ var cursor = event.target.result;
+ // 查看游标(指针)有没有返回一条数据
+ if (cursor) {
+ list.push(cursor.value);
+ cursor.continue(); // 移动到下一条数据
+ } else {
+ resolve(list)
+ }
+ }
+ })
+}
+
+/**
+ * 根据索引来查询数据(只会返回一条)
+ * @param {*} db
+ * @param {*} storeName
+ * @param {*} indexName 索引名称
+ * @param {*} indexValue 索引值
+ */
+function getDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .index(indexName)
+ .get(indexValue);
+
+ request.onsuccess = function (event) {
+ resolve(event.target.result);
+ }
+ })
+}
+
+/**
+ * 根据索引和游标来查询数据
+ * @param {*} db
+ * @param {*} storeName
+ * @param {*} indexName 索引名称
+ * @param {*} indexValue 索引值
+ */
+function getDataByIndex(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject) => {
+ var list = []; // 存储所有满足条件的数据
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .index(indexName)
+ .openCursor(IDBKeyRange.lowerBound(indexValue));
+
+ request.onsuccess = function (event) {
+ var cursor = event.target.result;
+ if (cursor) {
+ list.push(cursor.value);
+ cursor.continue();
+ } else {
+ resolve(list);
+ }
+ }
+ })
+}
+
+/**
+ * 通过索引和游标分页查询记录
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名称
+ * @param {string} indexValue 索引值
+ * @param {number} page 页码
+ * @param {number} pageSize 查询条数
+ */
+function cursorGetDataByIndexAndPage(
+ db,
+ storeName,
+ indexName,
+ indexValue,
+ page,
+ pageSize
+) {
+ return new Promise((resolve, reject) => {
+ var list = []; // 用于存储当前页的分页数据
+ var counter = 0; // 创建一个计数器
+ var isPass = true; // 是否要跳过数据
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .openCursor(); // 创建一个指针(游标)对象(目前是指向第一条数据)
+ request.onsuccess = function (event) {
+ var cursor = event.target.result;
+ // 接下来有一个很重要的判断,判断是否要跳过一些数据
+ if (page > 1 && isPass) {
+ isPass = false;
+ cursor.advance((page - 1) * pageSize); // 跳过数据
+ return;
+ }
+ if (cursor) {
+ list.push(cursor.value);
+ counter++;
+ if (counter < pageSize) {
+ cursor.continue();
+ } else {
+ cursor = null;
+ resolve(list);
+ }
+ } else {
+ resolve(list)
+ }
+ }
+ })
+}
+
+/**
+ * 更新数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {object} data 数据
+ */
+function updateDB(db, storeName, data) {
+ return new Promise((resolve, reject) => {
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .put(data);
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "更新数据成功"
+ })
+ }
+ })
+}
+
+/**
+* 通过主键删除数据
+* @param {object} db 数据库实例
+* @param {string} storeName 仓库名称
+* @param {object} id 主键值
+*/
+function deleteDB(db, storeName, id) {
+ return new Promise((resolve, reject) => {
+ var request = db
+ .transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .delete(id);
+
+ request.onsuccess = function () {
+ resolve({
+ status: true,
+ message: "删除数据成功"
+ })
+ };
+
+ request.onerror = function () {
+ reject({
+ status: true,
+ message: "删除数据失败"
+ })
+ };
+ })
+}
+
+
+/**
+ * 通过索引和游标删除指定的数据
+ * @param {object} db 数据库实例
+ * @param {string} storeName 仓库名称
+ * @param {string} indexName 索引名
+ * @param {object} indexValue 索引值
+ */
+ function cursorDelete(db, storeName, indexName, indexValue) {
+ return new Promise((resolve, reject)=>{
+ var request = db.transaction([storeName], "readwrite")
+ .objectStore(storeName)
+ .index(indexName)
+ .openCursor(IDBKeyRange.only(indexValue));
+ request.onsuccess = function(event){
+ var cursor = event.target.result;
+ if(cursor){
+ var deleteRequest = cursor.delete();
+ deleteRequest.onsuccess = function(){
+ resolve({
+ status: true,
+ message: "删除数据成功"
+ })
+ }
+ cursor.continue();
+ }
+ }
+ })
+ }
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/IndexedDB课堂代码/index.html b/04. 浏览器的离线存储/IndexedDB课堂代码/index.html
new file mode 100644
index 0000000..b0a6e39
--- /dev/null
+++ b/04. 浏览器的离线存储/IndexedDB课堂代码/index.html
@@ -0,0 +1,63 @@
+
+
+
+
+
+
+
+  +
+
+
+在 *WebSQL* 中,有 *3* 个核心方法:
+
+- *openDatabase*:这个方法使用现有的数据库或者新建的数据库创建一个数据库对象。
+
+- *transaction*:这个方法让我们能够控制一个事务,以及基于这种情况执行提交或者回滚。
+
+- *executeSql*:这个方法用于执行实际的 *SQL* 查询。
+
+
+
+## 打开数据库
+
+我们可以使用 *openDatabase( )* 方法来打开已存在的数据库,如果数据库不存在,则会创建一个新的数据库,使用代码如下:
+
+```js
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+```
+
+在上面的代码中,我们尝试打开一个名为 *mydb* 的数据库,因为第一次不存在此数据库,所以会创建该数据库,版本号为 *1.0*,大小为 *2M*。
+
+
+
+
+
+
+
+在 *WebSQL* 中,有 *3* 个核心方法:
+
+- *openDatabase*:这个方法使用现有的数据库或者新建的数据库创建一个数据库对象。
+
+- *transaction*:这个方法让我们能够控制一个事务,以及基于这种情况执行提交或者回滚。
+
+- *executeSql*:这个方法用于执行实际的 *SQL* 查询。
+
+
+
+## 打开数据库
+
+我们可以使用 *openDatabase( )* 方法来打开已存在的数据库,如果数据库不存在,则会创建一个新的数据库,使用代码如下:
+
+```js
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+```
+
+在上面的代码中,我们尝试打开一个名为 *mydb* 的数据库,因为第一次不存在此数据库,所以会创建该数据库,版本号为 *1.0*,大小为 *2M*。
+
+
+
+ +
+*openDatabase( )* 方法对应的 *5* 个参数:
+
+- 数据库名称
+
+- 版本号
+
+- 描述文本
+
+- 数据库大小
+
+- 创建回调
+
+第 *5* 个参数,创建回调会在创建数据库后被调用。
+
+
+
+## 执行操作
+
+执行操作使用 *database.transaction( )* 函数:
+
+```js
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS LOGS (id unique, log)');
+});
+```
+
+上面的语句执行后会在 '*mydb*' 数据库中创建一个名为 *LOGS* 的表。
+
+该表存在 *2* 个字段 *id* 和 *log*,其中 *id* 是唯一的。
+
+
+
+*openDatabase( )* 方法对应的 *5* 个参数:
+
+- 数据库名称
+
+- 版本号
+
+- 描述文本
+
+- 数据库大小
+
+- 创建回调
+
+第 *5* 个参数,创建回调会在创建数据库后被调用。
+
+
+
+## 执行操作
+
+执行操作使用 *database.transaction( )* 函数:
+
+```js
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS LOGS (id unique, log)');
+});
+```
+
+上面的语句执行后会在 '*mydb*' 数据库中创建一个名为 *LOGS* 的表。
+
+该表存在 *2* 个字段 *id* 和 *log*,其中 *id* 是唯一的。
+
+ +
+
+
+## 插入数据
+
+在执行上面的创建表语句后,我们可以插入一些数据:
+
+```js
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS STU (id unique, name, age)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (1, "张三", 18)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (2, "李四", 20)');
+});
+```
+
+在上面的代码中,我们创建了一张名为 *STU* 的表,该表存在 *3* 个字段 *id,name* 和 *age*。
+
+之后我们往这张表中插入了 *2* 条数据。
+
+
+
+
+
+## 插入数据
+
+在执行上面的创建表语句后,我们可以插入一些数据:
+
+```js
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS STU (id unique, name, age)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (1, "张三", 18)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (2, "李四", 20)');
+});
+```
+
+在上面的代码中,我们创建了一张名为 *STU* 的表,该表存在 *3* 个字段 *id,name* 和 *age*。
+
+之后我们往这张表中插入了 *2* 条数据。
+
+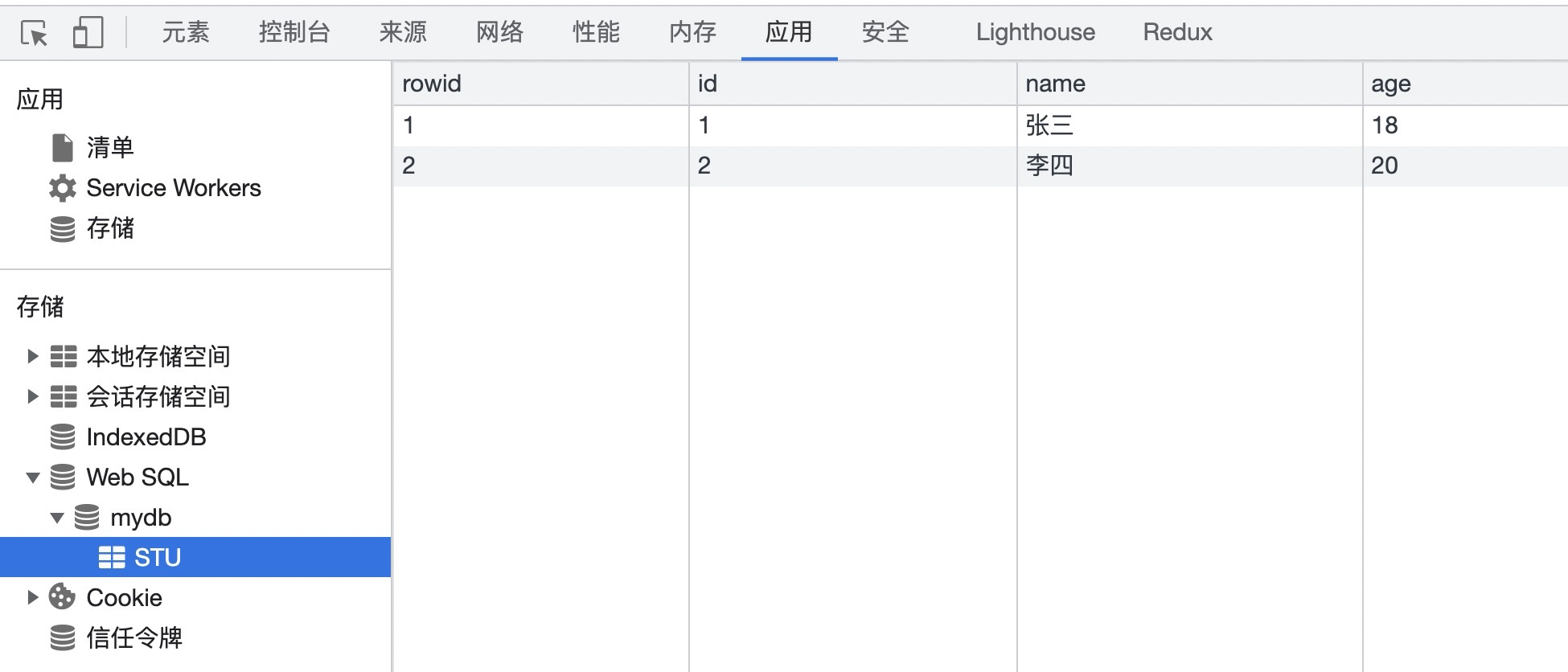 +
+
+
+我们也可以使用动态值来插入数据:
+
+```js
+var stuName = "谢杰";
+var stuAge = 18;
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS STU (id unique, name, age)');
+ // tx.executeSql('INSERT INTO STU (id, name, age) VALUES (1, "张三", 18)');
+ // tx.executeSql('INSERT INTO STU (id, name, age) VALUES (2, "李四", 20)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (3, ?, ?)', [stuName, stuAge]);
+});
+```
+
+在上面的代码中,我们使用动态值的方式插入了一条数据,实例中的 *stuName* 和 *stuAge* 是外部变量,*executeSql* 会映射数组参数中的每个条目给 "?"。
+
+>注意:由于上一次操作已经插入了 *id* 为 *1* 和 *2* 的数据,所以这一次插入内容时,要将前面两次插入语句注释调,否则插入操作不会成功。因为这里是一个事务,前面失败了会导致后面也失败。
+
+
+
+## 读取数据
+
+以下实例演示了如何读取数据库中已经存在的数据:
+
+```html
+
+```
+
+```js
+var stuName = "谢杰";
+var stuAge = 18;
+// 打开数据库
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+// 插入数据
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS STU (id unique, name, age)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (1, "张三", 18)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (2, "李四", 20)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (3, ?, ?)', [stuName, stuAge]);
+});
+
+// 读取操作
+db.transaction(function (tx) {
+ tx.executeSql('SELECT * FROM STU', [], function (tx, results) {
+ var len = results.rows.length, i;
+ msg = "
+
+
+
+我们也可以使用动态值来插入数据:
+
+```js
+var stuName = "谢杰";
+var stuAge = 18;
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS STU (id unique, name, age)');
+ // tx.executeSql('INSERT INTO STU (id, name, age) VALUES (1, "张三", 18)');
+ // tx.executeSql('INSERT INTO STU (id, name, age) VALUES (2, "李四", 20)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (3, ?, ?)', [stuName, stuAge]);
+});
+```
+
+在上面的代码中,我们使用动态值的方式插入了一条数据,实例中的 *stuName* 和 *stuAge* 是外部变量,*executeSql* 会映射数组参数中的每个条目给 "?"。
+
+>注意:由于上一次操作已经插入了 *id* 为 *1* 和 *2* 的数据,所以这一次插入内容时,要将前面两次插入语句注释调,否则插入操作不会成功。因为这里是一个事务,前面失败了会导致后面也失败。
+
+
+
+## 读取数据
+
+以下实例演示了如何读取数据库中已经存在的数据:
+
+```html
+
+```
+
+```js
+var stuName = "谢杰";
+var stuAge = 18;
+// 打开数据库
+var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
+// 插入数据
+db.transaction(function (tx) {
+ tx.executeSql('CREATE TABLE IF NOT EXISTS STU (id unique, name, age)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (1, "张三", 18)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (2, "李四", 20)');
+ tx.executeSql('INSERT INTO STU (id, name, age) VALUES (3, ?, ?)', [stuName, stuAge]);
+});
+
+// 读取操作
+db.transaction(function (tx) {
+ tx.executeSql('SELECT * FROM STU', [], function (tx, results) {
+ var len = results.rows.length, i;
+ msg = "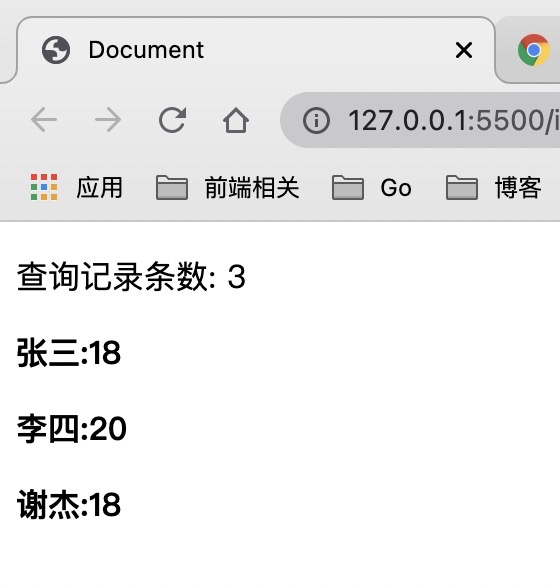 +
+## 删除数据
+
+删除数据也是使用 *SQL* 中的语法,同样也支持动态指定的方式。
+
+```js
+var stuID = 2;
+// 删除操作
+db.transaction(function (tx) {
+ tx.executeSql('DELETE FROM STU WHERE id=1');
+ tx.executeSql('DELETE FROM STU WHERE id=?', [stuID]);
+});
+```
+
+在上面的代码中,我们删除了 *id* 为 *1* 和 *2* 的两条数据,其中第二条是动态指定的。
+
+
+
+## 修改数据
+
+要修改数据也是使用 *SQL* 中的语法,同样也支持动态指定的方式。
+
+```js
+var stuID = 3;
+// 更新操作
+db.transaction(function (tx) {
+ tx.executeSql('UPDATE STU SET name=\'王羲之\' WHERE id=3');
+ tx.executeSql('UPDATE STU SET age=21 WHERE id=?', [stuID]);
+});
+```
+
+在上面的代码中,我们修改了 *id* 为 *3* 的学生,名字修改为“王羲之”,年龄修改为 *21*。
+
+
+
+## 总结
+
+目前来看,*WebSQL* 已经不再是 *W3C* 推荐规范,官方也已经不再维护了。原因说的很清楚,当前的 *SQL* 规范采用 *SQLite* 的 *SQL* 方言,而作为一个标准,这是不可接受的。
+
+另外,*WebSQL* 使用 *SQL* 语言来进行操作,更像是一个关系型数据库,而 *IndexedDB* 则更像是一个 *NoSQL* 数据库, 这也是目前 *W3C* 强推的浏览端数据库解决方案。
+
+所以本文不再对 *WebSQL* 做过多的介绍。
+
+如果有兴趣的同学,可以参阅下面的资料进行扩展阅读:
+
+- *View Web SQL data*:*https://developer.chrome.com/docs/devtools/storage/websql/?utm_source=devtools#run*(需要搭梯子)
+- *CSDN WebSQL* 最全详解:*https://blog.csdn.net/weixin_45389633/article/details/107308968*
+
+
+
+
+-------
+
+
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/浏览器离线存储概述.md b/04. 浏览器的离线存储/浏览器离线存储概述.md
new file mode 100644
index 0000000..a73d019
--- /dev/null
+++ b/04. 浏览器的离线存储/浏览器离线存储概述.md
@@ -0,0 +1,53 @@
+# 浏览器离线存储概述
+
+
+
+在前面的章节中,我们已经为大家介绍了整个浏览器的组成部分:
+
+
+
+
+
+## 删除数据
+
+删除数据也是使用 *SQL* 中的语法,同样也支持动态指定的方式。
+
+```js
+var stuID = 2;
+// 删除操作
+db.transaction(function (tx) {
+ tx.executeSql('DELETE FROM STU WHERE id=1');
+ tx.executeSql('DELETE FROM STU WHERE id=?', [stuID]);
+});
+```
+
+在上面的代码中,我们删除了 *id* 为 *1* 和 *2* 的两条数据,其中第二条是动态指定的。
+
+
+
+## 修改数据
+
+要修改数据也是使用 *SQL* 中的语法,同样也支持动态指定的方式。
+
+```js
+var stuID = 3;
+// 更新操作
+db.transaction(function (tx) {
+ tx.executeSql('UPDATE STU SET name=\'王羲之\' WHERE id=3');
+ tx.executeSql('UPDATE STU SET age=21 WHERE id=?', [stuID]);
+});
+```
+
+在上面的代码中,我们修改了 *id* 为 *3* 的学生,名字修改为“王羲之”,年龄修改为 *21*。
+
+
+
+## 总结
+
+目前来看,*WebSQL* 已经不再是 *W3C* 推荐规范,官方也已经不再维护了。原因说的很清楚,当前的 *SQL* 规范采用 *SQLite* 的 *SQL* 方言,而作为一个标准,这是不可接受的。
+
+另外,*WebSQL* 使用 *SQL* 语言来进行操作,更像是一个关系型数据库,而 *IndexedDB* 则更像是一个 *NoSQL* 数据库, 这也是目前 *W3C* 强推的浏览端数据库解决方案。
+
+所以本文不再对 *WebSQL* 做过多的介绍。
+
+如果有兴趣的同学,可以参阅下面的资料进行扩展阅读:
+
+- *View Web SQL data*:*https://developer.chrome.com/docs/devtools/storage/websql/?utm_source=devtools#run*(需要搭梯子)
+- *CSDN WebSQL* 最全详解:*https://blog.csdn.net/weixin_45389633/article/details/107308968*
+
+
+
+
+-------
+
+
+
+-*EOF*-
\ No newline at end of file
diff --git a/04. 浏览器的离线存储/浏览器离线存储概述.md b/04. 浏览器的离线存储/浏览器离线存储概述.md
new file mode 100644
index 0000000..a73d019
--- /dev/null
+++ b/04. 浏览器的离线存储/浏览器离线存储概述.md
@@ -0,0 +1,53 @@
+# 浏览器离线存储概述
+
+
+
+在前面的章节中,我们已经为大家介绍了整个浏览器的组成部分:
+
+
+
+ +
+
+
+大致分为:
+
+
+
+- 用户界面(*user interface*)
+
+- 浏览器引擎(*browser engine*)
+
+- 渲染引擎(*rendering engine*)
+
+- 网络(*networking*)
+
+- *JS* 解释器(*JavaScript interpreter*)
+
+- 用户界面后端(*UI backend*)
+
+- 数据存储(*data storage*)
+
+
+
+而本章节我们就一起来看一下 *Data Persistence/storage* 这个部分,翻译成中文叫做浏览器离线存储或者本地存储。顾名思义,就是内容存储在浏览器这一边。
+
+
+
+目前常见的浏览器离线存储的方式如下:
+
+
+
+- *Cookie*
+- *Web Storage*
+- *WebSQL*
+- *IndexedDB*
+- *File System*
+
+
+
+------
+
+
+
+-*EOF*-
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存.md b/05. 浏览器的缓存/浏览器缓存.md
new file mode 100644
index 0000000..2647e00
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存.md
@@ -0,0 +1,483 @@
+# 浏览器缓存
+
+
+
+本文主要包含以下内容:
+
+- 什么是浏览器缓存
+- 按照缓存位置分类
+ - *Service Worker*
+ - *Memory Cache*
+ - *Disk Cache*
+ - *Push Cache*
+- 按照缓存类型分类
+ - 强制缓存
+ - 协商缓存
+- 缓存读取规则
+- 浏览器行为
+- 实操案例
+- 缓存的最佳实践
+
+## 什么是浏览器缓存
+
+在正式开始讲解浏览器缓存之前,我们先来回顾一下整个 *Web* 应用的流程。
+
+
+
+
+
+上图展示了一个 *Web* 应用最最简单的结构。客户端向服务器端发送 *HTTP* 请求,服务器端从数据库获取数据,然后进行计算处理,之后向客户端返回 *HTTP* 响应。
+
+那么上面整个流程中,哪些地方比较耗费时间呢?总结起来有如下两个方面:
+
+- 发送请求的时候
+
+- 涉及到大量计算的时候
+
+一般来讲,上面两个阶段比较耗费时间。
+
+首先是发送请求的时候。这里所说的请求,不仅仅是 *HTTP* 请求,也包括服务器向数据库发起查询数据的请求。
+
+其次是大量计算的时候。一般涉及到大量计算,主要是在服务器端和数据库端,服务器端要进行计算这个很好理解,数据库要根据服务器发送过来的查询命令查询到对应的数据,这也是比较耗时的一项工作。
+
+因此,单论缓存的话,我们其实在很多地方都可以做缓存。例如:
+
+- 数据库缓存
+- *CDN* 缓存
+- 代理服务器缓存
+- 浏览器缓存
+- 应用层缓存
+
+针对各个地方做出适当的缓存,都能够很大程度的优化整个 *Web* 应用的性能。但是要逐一讨论的话,是一个非常大的工程量,所以本文我们主要来看一下浏览器缓存,这也是和我们前端开发息息相关的。
+
+整个浏览器的缓存过程如下:
+
+
+
+
+
+大致分为:
+
+
+
+- 用户界面(*user interface*)
+
+- 浏览器引擎(*browser engine*)
+
+- 渲染引擎(*rendering engine*)
+
+- 网络(*networking*)
+
+- *JS* 解释器(*JavaScript interpreter*)
+
+- 用户界面后端(*UI backend*)
+
+- 数据存储(*data storage*)
+
+
+
+而本章节我们就一起来看一下 *Data Persistence/storage* 这个部分,翻译成中文叫做浏览器离线存储或者本地存储。顾名思义,就是内容存储在浏览器这一边。
+
+
+
+目前常见的浏览器离线存储的方式如下:
+
+
+
+- *Cookie*
+- *Web Storage*
+- *WebSQL*
+- *IndexedDB*
+- *File System*
+
+
+
+------
+
+
+
+-*EOF*-
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存.md b/05. 浏览器的缓存/浏览器缓存.md
new file mode 100644
index 0000000..2647e00
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存.md
@@ -0,0 +1,483 @@
+# 浏览器缓存
+
+
+
+本文主要包含以下内容:
+
+- 什么是浏览器缓存
+- 按照缓存位置分类
+ - *Service Worker*
+ - *Memory Cache*
+ - *Disk Cache*
+ - *Push Cache*
+- 按照缓存类型分类
+ - 强制缓存
+ - 协商缓存
+- 缓存读取规则
+- 浏览器行为
+- 实操案例
+- 缓存的最佳实践
+
+## 什么是浏览器缓存
+
+在正式开始讲解浏览器缓存之前,我们先来回顾一下整个 *Web* 应用的流程。
+
+
+
+
+
+上图展示了一个 *Web* 应用最最简单的结构。客户端向服务器端发送 *HTTP* 请求,服务器端从数据库获取数据,然后进行计算处理,之后向客户端返回 *HTTP* 响应。
+
+那么上面整个流程中,哪些地方比较耗费时间呢?总结起来有如下两个方面:
+
+- 发送请求的时候
+
+- 涉及到大量计算的时候
+
+一般来讲,上面两个阶段比较耗费时间。
+
+首先是发送请求的时候。这里所说的请求,不仅仅是 *HTTP* 请求,也包括服务器向数据库发起查询数据的请求。
+
+其次是大量计算的时候。一般涉及到大量计算,主要是在服务器端和数据库端,服务器端要进行计算这个很好理解,数据库要根据服务器发送过来的查询命令查询到对应的数据,这也是比较耗时的一项工作。
+
+因此,单论缓存的话,我们其实在很多地方都可以做缓存。例如:
+
+- 数据库缓存
+- *CDN* 缓存
+- 代理服务器缓存
+- 浏览器缓存
+- 应用层缓存
+
+针对各个地方做出适当的缓存,都能够很大程度的优化整个 *Web* 应用的性能。但是要逐一讨论的话,是一个非常大的工程量,所以本文我们主要来看一下浏览器缓存,这也是和我们前端开发息息相关的。
+
+整个浏览器的缓存过程如下:
+
+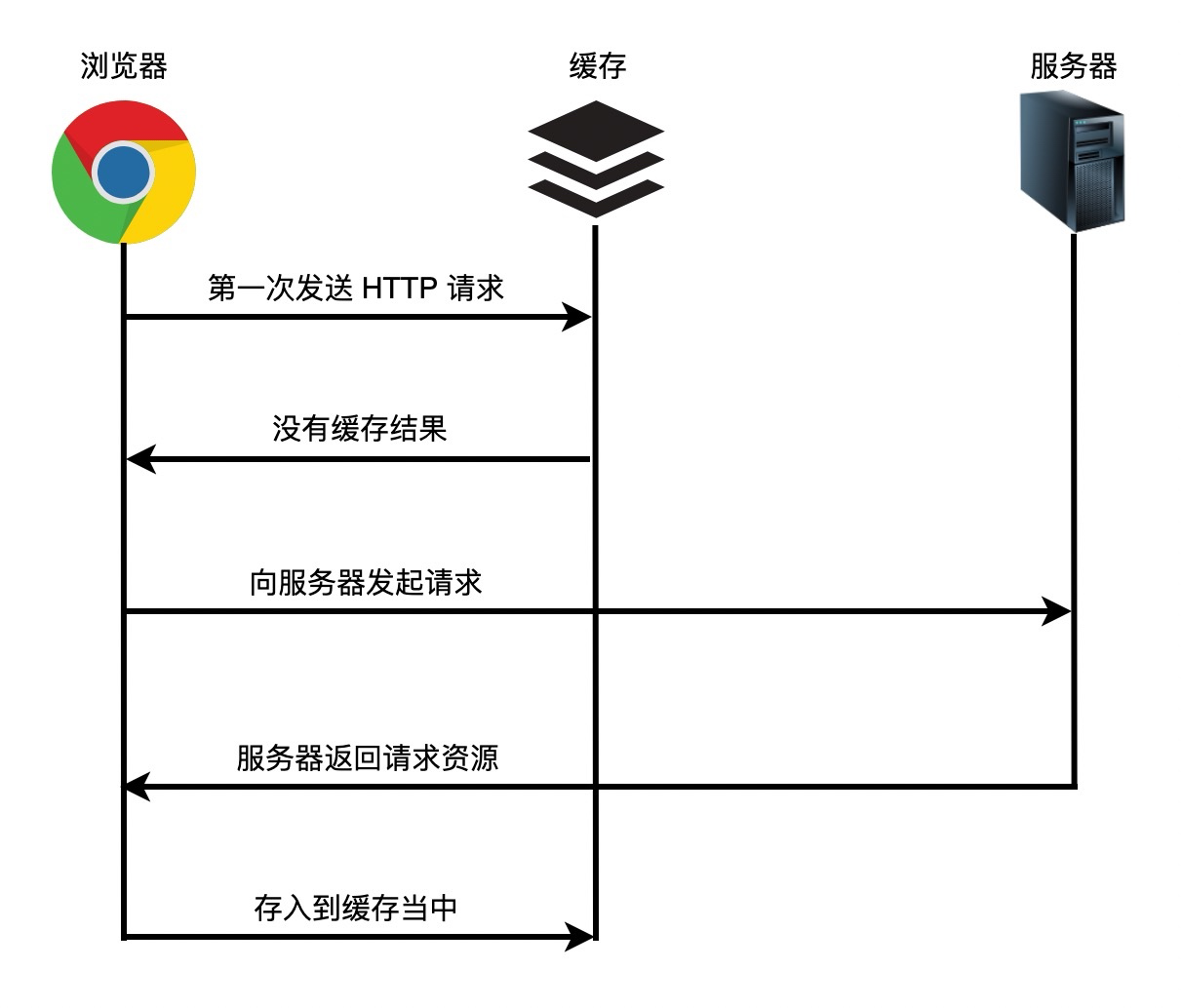 +
+
+
+从上图我们可以看到,整个浏览器端的缓存其实没有想象的那么复杂。其最基本的原理就是:
+
+- 浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识
+
+- 浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中
+
+以上两点结论就是浏览器缓存机制的关键,它确保了每个请求的缓存存入与读取,只要我们再理解浏览器缓存的使用规则,那么所有的问题就迎刃而解了。
+
+接下来,我将从两个维度来介绍浏览器缓存:
+
+- 缓存的存储位置
+
+- 缓存的类型
+
+## 按照缓存位置分类
+
+从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络。这四种依次为:
+
+- *Service Worker*
+
+- *Memory Cache*
+
+- *Disk Cache*
+
+- *Push Cache*
+
+### *Service Worker*
+
+*Service Worker* 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。
+
+使用 *Service Worker* 的话,传输协议必须为 *HTTPS*。因为 *Service Worker* 中涉及到请求拦截,所以必须使用 *HTTPS* 协议来保障安全。
+
+*Service Worker* 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
+
+*Service Worker* 实现缓存功能一般分为三个步骤:首先需要先注册 *Service Worker*,然后监听到 *install* 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。.
+
+当 *Service Worker* 没有命中缓存的时候,我们需要去调用 *fetch* 函数获取数据。也就是说,如果我们没有在 *Service Worker* 命中缓存的话,会根据缓存查找优先级去查找数据。
+
+
+
+
+
+
+
+但是不管我们是从 *Memory Cache* 中还是从网络请求中获取的数据,浏览器都会显示我们是从 *Service Worker* 中获取的内容。
+
+
+
+### *Memory Cache*
+
+*Memory Cache* 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。
+
+读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。一旦我们关闭 *Tab* 页面,内存中的缓存也就被释放了。
+
+那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢?
+
+这是不可能的。计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。
+
+当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存。
+
+
+
+
+
+*Memory Cache* 机制保证了一个页面中如果有两个相同的请求。
+
+例如两个 *src* 相同的 \<*img*>,两个 *href* 相同的 \<*link*>,都实际只会被请求最多一次,避免浪费。
+
+### *Disk Cache*
+
+*Disk Cache* 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 *Memory Cache* 胜在容量和存储时效性上。
+
+在所有浏览器缓存中,*Disk Cache* 覆盖面基本是最大的。它会根据 *HTTP Herder* 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。
+
+并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 *Disk Cache*。
+
+凡是持久性存储都会面临容量增长的问题,*Disk Cache* 也不例外。
+
+在浏览器自动清理时,会有特殊的算法去把“最老的”或者“最可能过时的”资源删除,因此是一个一个删除的。不过每个浏览器识别“最老的”和“最可能过时的”资源的算法不尽相同,这也可以看作是各个浏览器差异性的体现。
+
+### *Push Cache*
+
+*Push Cache* 翻译成中文叫做“推送缓存”,是属于 *HTTP/2* 中新增的内容。
+
+当以上三种缓存都没有命中时,它才会被使用。它只在会话(*Session*)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 *Chrome* 浏览器中只有 *5* 分钟左右,同时它也并非严格执行 *HTTP/2* 头中的缓存指令。
+
+*Push Cache* 在国内能够查到的资料很少,也是因为 *HTTP2* 在国内还不够普及。
+
+这里推荐阅读 *Jake Archibald* 的 [*HTTP/2 push is tougher than I thought*](https://jakearchibald.com/2017/h2-push-tougher-than-i-thought/) 这篇文章。
+
+文章中的几个结论:
+
+- 所有的资源都能被推送,并且能够被缓存,但是 *Edge* 和 *Safari* 浏览器支持相对比较差
+
+- 可以推送 *no-cache* 和 *no-store* 的资源
+
+- 一旦连接被关闭,*Push Cache* 就被释放
+
+- 多个页面可以使用同一个 *HTTP/2* 的连接,也就可以使用同一个 *Push Cache*。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的 *tab* 标签使用同一个 *HTTP* 连接。
+
+- *Push Cache* 中的缓存只能被使用一次
+
+- 浏览器可以拒绝接受已经存在的资源推送
+
+- 你可以给其他域名推送资源
+
+
+-------
+
+如果一个请求在上述几个位置都没有找到缓存,那么浏览器会正式发送网络请求去获取内容。之后为了提升之后请求的缓存命中率,自然要把这个资源添加到缓存中去。具体来说:
+
+- 根据 *Service Worker* 中的 *handler* 决定是否存入 *Cache Storage* (额外的缓存位置)。*Service Worker* 是由开发者编写的额外的脚本,且缓存位置独立,出现也较晚,使用还不算太广泛。
+
+- *Memory Cache* 保存一份资源的引用,以备下次使用。*Memory Cache* 是浏览器为了加快读取缓存速度而进行的自身的优化行为,不受开发者控制,也不受 *HTTP* 协议头的约束,算是一个黑盒。
+
+- 根据 *HTTP* 头部的相关字段( *Cache-control、Pragma* 等 )决定是否存入 *Disk Cache*。*Disk Cache* 也是平时我们最熟悉的一种缓存机制,也叫 *HTTP Cache* (因为不像 *Memory Cache*,它遵守 *HTTP* 协议头中的字段)。平时所说的强制缓存,协商缓存,以及 *Cache-Control* 等,也都归于此类。
+
+## 按照缓存类型分类
+
+按照缓存类型来进行分类,可以分为**强制缓存**和**协商缓存**。需要注意的是,无论是强制缓存还是协商缓存,都是属于 *Disk Cache* 或者叫做 *HTTP Cache* 里面的一种。
+
+### 强制缓存
+
+强制缓存的含义是,当客户端请求后,会先访问缓存数据库看缓存是否存在。如果存在则直接返回;不存在则请求真的服务器,响应后再写入缓存数据库。
+
+强制缓存直接减少请求数,是提升最大的缓存策略。如果考虑使用缓存来优化网页性能的话,强制缓存应该是首先被考虑的。
+
+可以造成强制缓存的字段是 *Cache-control* 和 *Expires*。
+
+#### *Expires*
+
+这是 *HTTP 1.0* 的字段,表示缓存到期时间,是一个绝对的时间 (当前时间+缓存时间),如:
+
+```
+Expires: Thu, 10 Nov 2017 08:45:11 GMT
+```
+
+在响应消息头中,设置这个字段之后,就可以告诉浏览器,在未过期之前不需要再次请求。
+
+但是,这个字段设置时有两个缺点:
+
+- 由于是绝对时间,用户可能会将客户端本地的时间进行修改,而导致浏览器判断缓存失效,重新请求该资源。此外,即使不考虑自行修改的因素,时差或者误差等因素也可能造成客户端与服务端的时间不一致,致使缓存失效。
+
+- 写法太复杂了。表示时间的字符串多个空格,少个字母,都会导致变为非法属性从而设置失效。
+
+
+
+#### *Cache-control*
+
+已知 *Expires* 的缺点之后,在 *HTTP/1.1* 中,增加了一个字段 *Cache-control*,该字段表示资源缓存的最大有效时间,在该时间内,客户端不需要向服务器发送请求
+
+这两者的区别就是前者是绝对时间,而后者是相对时间。如下:
+
+```
+Cache-control: max-age=2592000
+```
+
+下面列举一些 *Cache-control* 字段常用的值:(完整的列表可以查看 [*MDN*](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control))
+
+- *max-age*:即最大有效时间,在上面的例子中我们可以看到
+
+- *must-revalidate*:如果超过了 *max-age* 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。
+
+- *no-cache*:虽然字面意思是“不要缓存”,但实际上还是要求客户端缓存内容的,只是是否使用这个内容由后续的协商缓存来决定。
+
+- *no-store*:真正意义上的“不要缓存”。所有内容都不走缓存,包括强制缓存和协商缓存。
+
+- *public*:所有的内容都可以被缓存(包括客户端和代理服务器, 如 *CDN* )
+
+- *private*:所有的内容只有客户端才可以缓存,代理服务器不能缓存。默认值。
+
+这些值可以混合使用,例如 *Cache-control:public, max-age=2592000*。在混合使用时,它们的优先级如下图:
+
+
+
+
+
+从上图我们可以看到,整个浏览器端的缓存其实没有想象的那么复杂。其最基本的原理就是:
+
+- 浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识
+
+- 浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中
+
+以上两点结论就是浏览器缓存机制的关键,它确保了每个请求的缓存存入与读取,只要我们再理解浏览器缓存的使用规则,那么所有的问题就迎刃而解了。
+
+接下来,我将从两个维度来介绍浏览器缓存:
+
+- 缓存的存储位置
+
+- 缓存的类型
+
+## 按照缓存位置分类
+
+从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络。这四种依次为:
+
+- *Service Worker*
+
+- *Memory Cache*
+
+- *Disk Cache*
+
+- *Push Cache*
+
+### *Service Worker*
+
+*Service Worker* 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。
+
+使用 *Service Worker* 的话,传输协议必须为 *HTTPS*。因为 *Service Worker* 中涉及到请求拦截,所以必须使用 *HTTPS* 协议来保障安全。
+
+*Service Worker* 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
+
+*Service Worker* 实现缓存功能一般分为三个步骤:首先需要先注册 *Service Worker*,然后监听到 *install* 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。.
+
+当 *Service Worker* 没有命中缓存的时候,我们需要去调用 *fetch* 函数获取数据。也就是说,如果我们没有在 *Service Worker* 命中缓存的话,会根据缓存查找优先级去查找数据。
+
+
+
+
+
+
+
+但是不管我们是从 *Memory Cache* 中还是从网络请求中获取的数据,浏览器都会显示我们是从 *Service Worker* 中获取的内容。
+
+
+
+### *Memory Cache*
+
+*Memory Cache* 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。
+
+读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。一旦我们关闭 *Tab* 页面,内存中的缓存也就被释放了。
+
+那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢?
+
+这是不可能的。计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。
+
+当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存。
+
+
+
+
+
+*Memory Cache* 机制保证了一个页面中如果有两个相同的请求。
+
+例如两个 *src* 相同的 \<*img*>,两个 *href* 相同的 \<*link*>,都实际只会被请求最多一次,避免浪费。
+
+### *Disk Cache*
+
+*Disk Cache* 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 *Memory Cache* 胜在容量和存储时效性上。
+
+在所有浏览器缓存中,*Disk Cache* 覆盖面基本是最大的。它会根据 *HTTP Herder* 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。
+
+并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 *Disk Cache*。
+
+凡是持久性存储都会面临容量增长的问题,*Disk Cache* 也不例外。
+
+在浏览器自动清理时,会有特殊的算法去把“最老的”或者“最可能过时的”资源删除,因此是一个一个删除的。不过每个浏览器识别“最老的”和“最可能过时的”资源的算法不尽相同,这也可以看作是各个浏览器差异性的体现。
+
+### *Push Cache*
+
+*Push Cache* 翻译成中文叫做“推送缓存”,是属于 *HTTP/2* 中新增的内容。
+
+当以上三种缓存都没有命中时,它才会被使用。它只在会话(*Session*)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 *Chrome* 浏览器中只有 *5* 分钟左右,同时它也并非严格执行 *HTTP/2* 头中的缓存指令。
+
+*Push Cache* 在国内能够查到的资料很少,也是因为 *HTTP2* 在国内还不够普及。
+
+这里推荐阅读 *Jake Archibald* 的 [*HTTP/2 push is tougher than I thought*](https://jakearchibald.com/2017/h2-push-tougher-than-i-thought/) 这篇文章。
+
+文章中的几个结论:
+
+- 所有的资源都能被推送,并且能够被缓存,但是 *Edge* 和 *Safari* 浏览器支持相对比较差
+
+- 可以推送 *no-cache* 和 *no-store* 的资源
+
+- 一旦连接被关闭,*Push Cache* 就被释放
+
+- 多个页面可以使用同一个 *HTTP/2* 的连接,也就可以使用同一个 *Push Cache*。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的 *tab* 标签使用同一个 *HTTP* 连接。
+
+- *Push Cache* 中的缓存只能被使用一次
+
+- 浏览器可以拒绝接受已经存在的资源推送
+
+- 你可以给其他域名推送资源
+
+
+-------
+
+如果一个请求在上述几个位置都没有找到缓存,那么浏览器会正式发送网络请求去获取内容。之后为了提升之后请求的缓存命中率,自然要把这个资源添加到缓存中去。具体来说:
+
+- 根据 *Service Worker* 中的 *handler* 决定是否存入 *Cache Storage* (额外的缓存位置)。*Service Worker* 是由开发者编写的额外的脚本,且缓存位置独立,出现也较晚,使用还不算太广泛。
+
+- *Memory Cache* 保存一份资源的引用,以备下次使用。*Memory Cache* 是浏览器为了加快读取缓存速度而进行的自身的优化行为,不受开发者控制,也不受 *HTTP* 协议头的约束,算是一个黑盒。
+
+- 根据 *HTTP* 头部的相关字段( *Cache-control、Pragma* 等 )决定是否存入 *Disk Cache*。*Disk Cache* 也是平时我们最熟悉的一种缓存机制,也叫 *HTTP Cache* (因为不像 *Memory Cache*,它遵守 *HTTP* 协议头中的字段)。平时所说的强制缓存,协商缓存,以及 *Cache-Control* 等,也都归于此类。
+
+## 按照缓存类型分类
+
+按照缓存类型来进行分类,可以分为**强制缓存**和**协商缓存**。需要注意的是,无论是强制缓存还是协商缓存,都是属于 *Disk Cache* 或者叫做 *HTTP Cache* 里面的一种。
+
+### 强制缓存
+
+强制缓存的含义是,当客户端请求后,会先访问缓存数据库看缓存是否存在。如果存在则直接返回;不存在则请求真的服务器,响应后再写入缓存数据库。
+
+强制缓存直接减少请求数,是提升最大的缓存策略。如果考虑使用缓存来优化网页性能的话,强制缓存应该是首先被考虑的。
+
+可以造成强制缓存的字段是 *Cache-control* 和 *Expires*。
+
+#### *Expires*
+
+这是 *HTTP 1.0* 的字段,表示缓存到期时间,是一个绝对的时间 (当前时间+缓存时间),如:
+
+```
+Expires: Thu, 10 Nov 2017 08:45:11 GMT
+```
+
+在响应消息头中,设置这个字段之后,就可以告诉浏览器,在未过期之前不需要再次请求。
+
+但是,这个字段设置时有两个缺点:
+
+- 由于是绝对时间,用户可能会将客户端本地的时间进行修改,而导致浏览器判断缓存失效,重新请求该资源。此外,即使不考虑自行修改的因素,时差或者误差等因素也可能造成客户端与服务端的时间不一致,致使缓存失效。
+
+- 写法太复杂了。表示时间的字符串多个空格,少个字母,都会导致变为非法属性从而设置失效。
+
+
+
+#### *Cache-control*
+
+已知 *Expires* 的缺点之后,在 *HTTP/1.1* 中,增加了一个字段 *Cache-control*,该字段表示资源缓存的最大有效时间,在该时间内,客户端不需要向服务器发送请求
+
+这两者的区别就是前者是绝对时间,而后者是相对时间。如下:
+
+```
+Cache-control: max-age=2592000
+```
+
+下面列举一些 *Cache-control* 字段常用的值:(完整的列表可以查看 [*MDN*](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control))
+
+- *max-age*:即最大有效时间,在上面的例子中我们可以看到
+
+- *must-revalidate*:如果超过了 *max-age* 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。
+
+- *no-cache*:虽然字面意思是“不要缓存”,但实际上还是要求客户端缓存内容的,只是是否使用这个内容由后续的协商缓存来决定。
+
+- *no-store*:真正意义上的“不要缓存”。所有内容都不走缓存,包括强制缓存和协商缓存。
+
+- *public*:所有的内容都可以被缓存(包括客户端和代理服务器, 如 *CDN* )
+
+- *private*:所有的内容只有客户端才可以缓存,代理服务器不能缓存。默认值。
+
+这些值可以混合使用,例如 *Cache-control:public, max-age=2592000*。在混合使用时,它们的优先级如下图:
+
+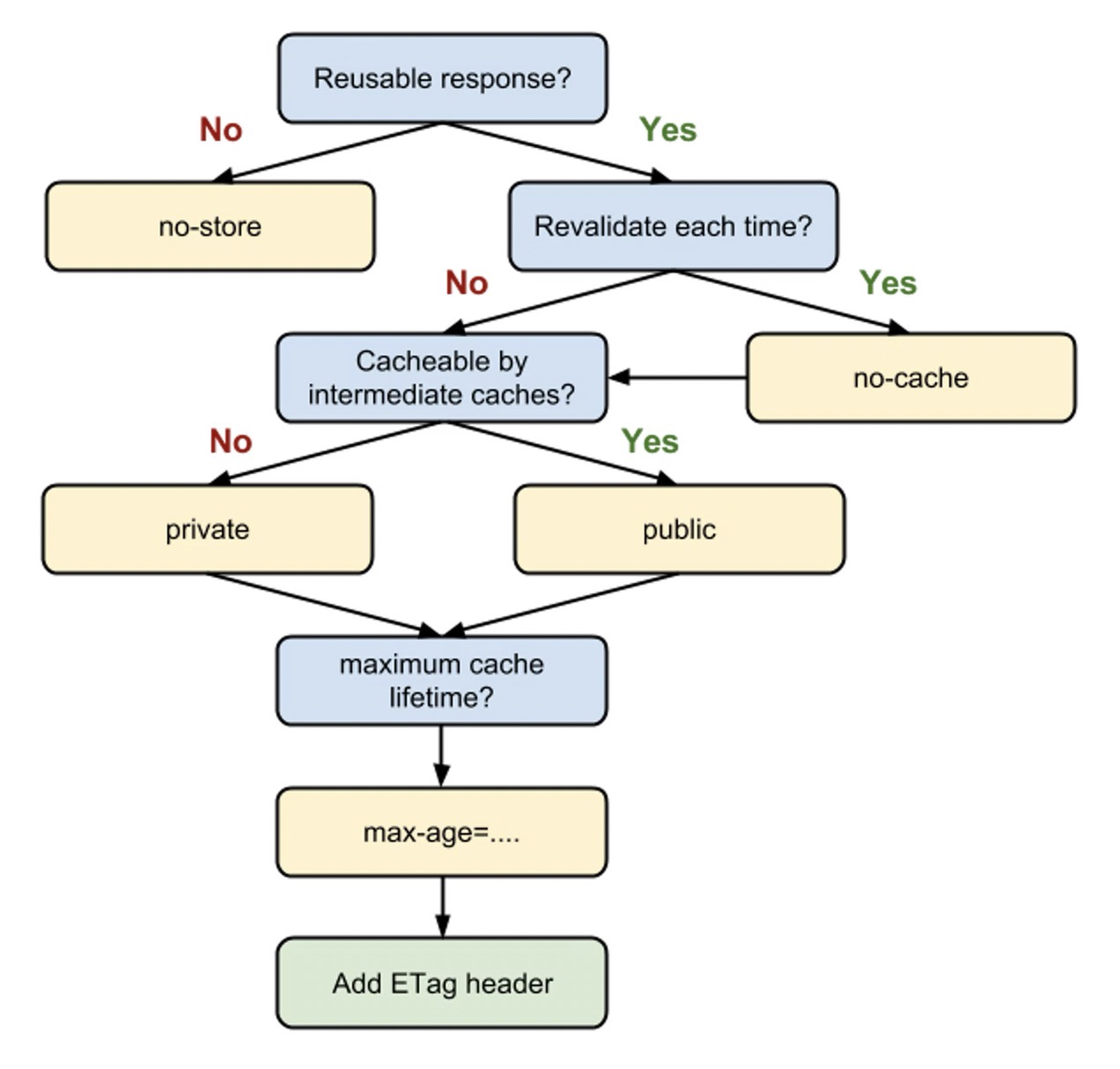 +
+
+
+>*max-age=0* 和 *no-cache* 等价吗?
+>从规范的字面意思来说,*max-age* 到期是 应该( *SHOULD* )重新验证,而 *no-cache* 是 必须( *MUST* )重新验证。但实际情况以浏览器实现为准,大部分情况他们俩的行为还是一致的。(如果是 *max-age=0, must-revalidate* 就和 *no-cache* 等价了)
+
+在 *HTTP/1.1* 之前,如果想使用 *no-cache*,通常是使用 *Pragma* 字段,如 *Pragma: no-cache*(这也是 *Pragma* 字段唯一的取值)。
+
+但是这个字段只是浏览器约定俗成的实现,并没有确切规范,因此缺乏可靠性。它应该只作为一个兼容字段出现,在当前的网络环境下其实用处已经很小。
+
+总结一下,自从 *HTTP/1.1* 开始,*Expires* 逐渐被 *Cache-control* 取代。
+
+*Cache-control* 是一个相对时间,即使客户端时间发生改变,相对时间也不会随之改变,这样可以保持服务器和客户端的时间一致性。而且 *Cache-control* 的可配置性比较强大。*Cache-control* 的优先级高于 *Expires*。
+
+为了兼容 *HTTP/1.0* 和 *HTTP/1.1*,实际项目中两个字段我们都会设置。
+
+
+
+### 协商缓存
+
+当强制缓存失效(超过规定时间)时,就需要使用协商缓存,由服务器决定缓存内容是否失效。
+
+流程上说,浏览器先请求缓存数据库,返回一个缓存标识。之后浏览器拿这个标识和服务器通讯。如果缓存未失效,则返回 *HTTP* 状态码 *304* 表示继续使用,于是客户端继续使用缓存;
+
+
+
+
+
+>*max-age=0* 和 *no-cache* 等价吗?
+>从规范的字面意思来说,*max-age* 到期是 应该( *SHOULD* )重新验证,而 *no-cache* 是 必须( *MUST* )重新验证。但实际情况以浏览器实现为准,大部分情况他们俩的行为还是一致的。(如果是 *max-age=0, must-revalidate* 就和 *no-cache* 等价了)
+
+在 *HTTP/1.1* 之前,如果想使用 *no-cache*,通常是使用 *Pragma* 字段,如 *Pragma: no-cache*(这也是 *Pragma* 字段唯一的取值)。
+
+但是这个字段只是浏览器约定俗成的实现,并没有确切规范,因此缺乏可靠性。它应该只作为一个兼容字段出现,在当前的网络环境下其实用处已经很小。
+
+总结一下,自从 *HTTP/1.1* 开始,*Expires* 逐渐被 *Cache-control* 取代。
+
+*Cache-control* 是一个相对时间,即使客户端时间发生改变,相对时间也不会随之改变,这样可以保持服务器和客户端的时间一致性。而且 *Cache-control* 的可配置性比较强大。*Cache-control* 的优先级高于 *Expires*。
+
+为了兼容 *HTTP/1.0* 和 *HTTP/1.1*,实际项目中两个字段我们都会设置。
+
+
+
+### 协商缓存
+
+当强制缓存失效(超过规定时间)时,就需要使用协商缓存,由服务器决定缓存内容是否失效。
+
+流程上说,浏览器先请求缓存数据库,返回一个缓存标识。之后浏览器拿这个标识和服务器通讯。如果缓存未失效,则返回 *HTTP* 状态码 *304* 表示继续使用,于是客户端继续使用缓存;
+
+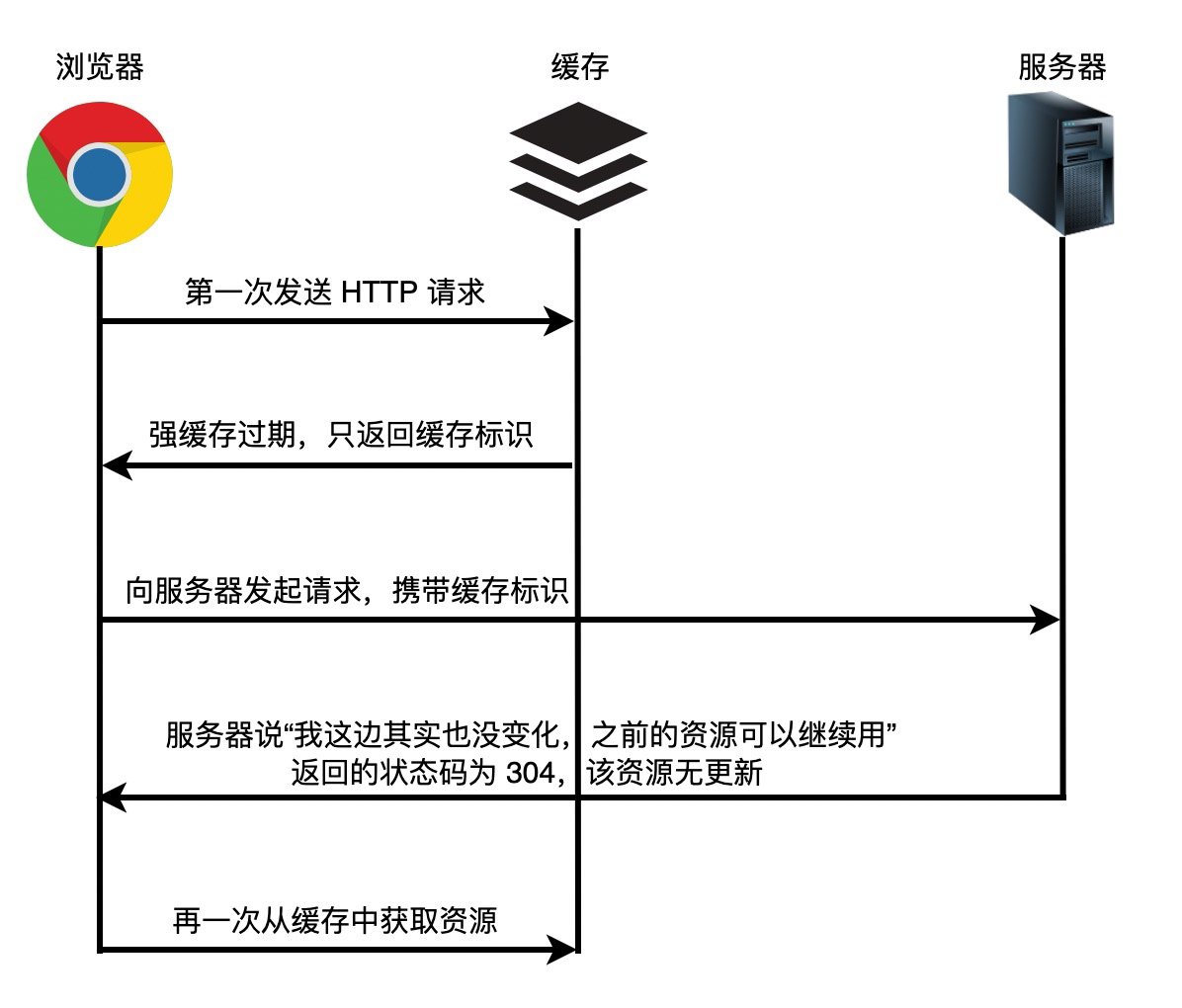 +
+
+
+如果失效,则返回新的数据和缓存规则,浏览器响应数据后,再把规则写入到缓存数据库。
+
+
+
+
+
+如果失效,则返回新的数据和缓存规则,浏览器响应数据后,再把规则写入到缓存数据库。
+
+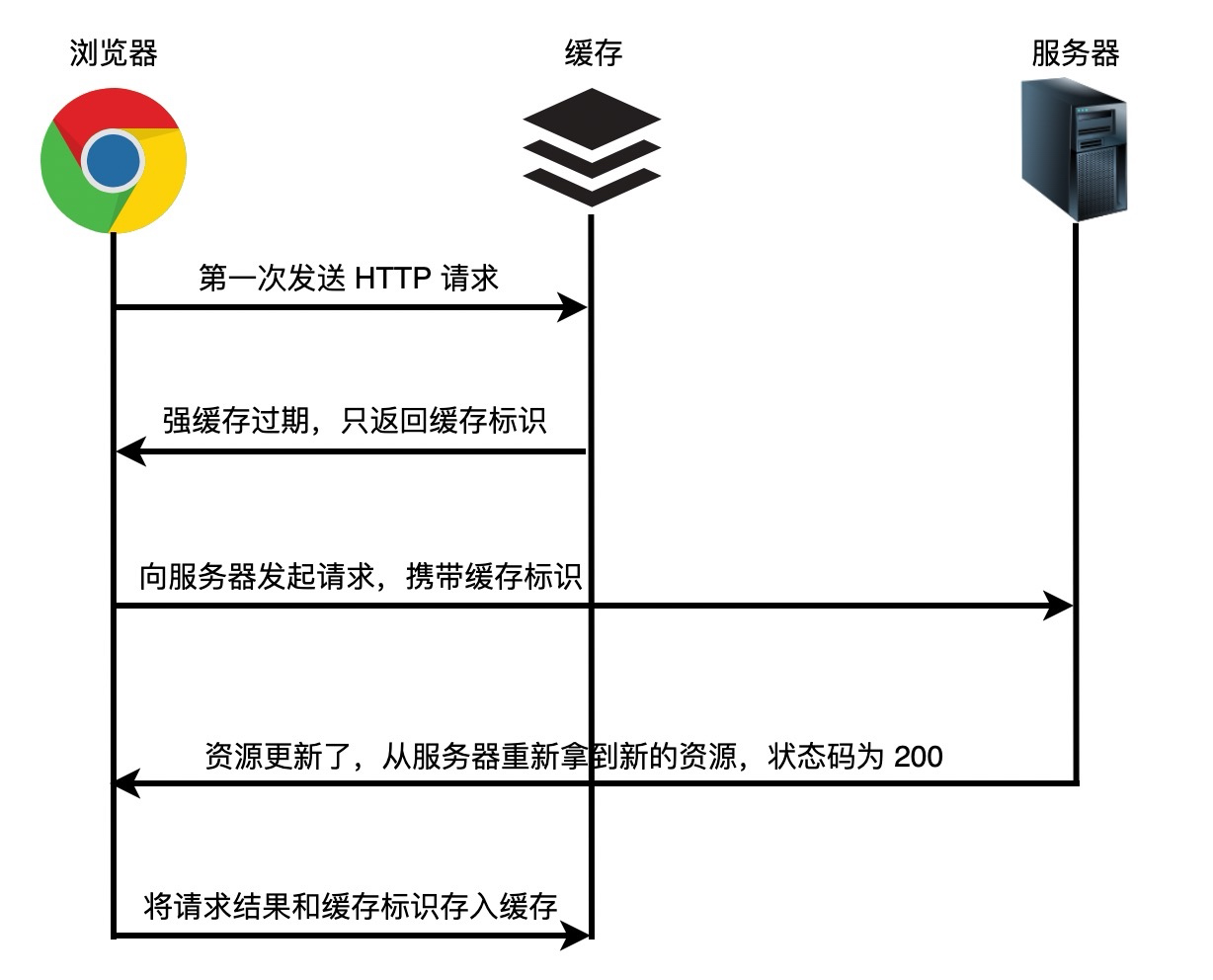 +
+
+
+协商缓存在请求数上和没有缓存是一致的,但如果是 *304* 的话,返回的仅仅是一个状态码而已,并没有实际的文件内容,因此 在响应体体积上的节省是它的优化点。
+
+它的优化主要体现在“响应”上面通过减少响应体体积,来缩短网络传输时间。所以和强制缓存相比提升幅度较小,但总比没有缓存好。
+
+协商缓存是可以和强制缓存一起使用的,作为在强制缓存失效后的一种后备方案。实际项目中他们也的确经常一同出现。
+
+对比缓存有 *2* 组字段(不是两个):
+
+- *Last-Modified & If-Modified-Since*
+
+- *Etag & If-None-Match*
+
+#### *Last-Modified & If-Modified-Since*
+
+1. 服务器通过 *Last-Modified* 字段告知客户端,资源最后一次被修改的时间,例如:
+
+ ```
+ Last-Modified: Mon, 10 Nov 2018 09:10:11 GMT
+ ```
+
+2. 浏览器将这个值和内容一起记录在缓存数据库中。
+
+
+3. 下一次请求相同资源时时,浏览器从自己的缓存中找出“不确定是否过期的”缓存。因此在请求头中将上次的 *Last-Modified* 的值写入到请求头的 *If-Modified-Since* 字段
+
+
+4. 服务器会将 *If-Modified-Since* 的值与 *Last-Modified* 字段进行对比。如果相等,则表示未修改,响应 *304*;反之,则表示修改了,响应 *200* 状态码,并返回数据。
+
+但是他还是有一定缺陷的:
+
+- 如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
+
+- 如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
+
+因此在 *HTTP/1.1* 出现了 *ETag* 和 *If-None-Match*
+
+
+
+#### *Etag & If-None-Match*
+
+为了解决上述问题,出现了一组新的字段 *Etag* 和 *If-None-Match*。
+
+*Etag* 存储的是文件的特殊标识(一般都是一个 *Hash* 值),服务器存储着文件的 *Etag* 字段。
+
+之后的流程和 *Last-Modified* 一致,只是 *Last-Modified* 字段和它所表示的更新时间改变成了 *Etag* 字段和它所表示的文件 *hash*,把 *If-Modified-Since* 变成了 *If-None-Match*。
+
+浏览器在下一次加载资源向服务器发送请求时,会将上一次返回的 Etag 值放到请求头里的 *If-None-Match* 里,服务器只需要比较客户端传来的 *If-None-Match* 跟自己服务器上该资源的 *ETag* 是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
+
+如果服务器发现 *ETag* 匹配不上,那么直接以常规 *GET 200* 回包形式将新的资源(当然也包括了新的 *ETag*)发给客户端;如果 *ETag* 是一致的,则直接返回 *304* 告诉客户端直接使用本地缓存即可。
+
+
+
+
+
+协商缓存在请求数上和没有缓存是一致的,但如果是 *304* 的话,返回的仅仅是一个状态码而已,并没有实际的文件内容,因此 在响应体体积上的节省是它的优化点。
+
+它的优化主要体现在“响应”上面通过减少响应体体积,来缩短网络传输时间。所以和强制缓存相比提升幅度较小,但总比没有缓存好。
+
+协商缓存是可以和强制缓存一起使用的,作为在强制缓存失效后的一种后备方案。实际项目中他们也的确经常一同出现。
+
+对比缓存有 *2* 组字段(不是两个):
+
+- *Last-Modified & If-Modified-Since*
+
+- *Etag & If-None-Match*
+
+#### *Last-Modified & If-Modified-Since*
+
+1. 服务器通过 *Last-Modified* 字段告知客户端,资源最后一次被修改的时间,例如:
+
+ ```
+ Last-Modified: Mon, 10 Nov 2018 09:10:11 GMT
+ ```
+
+2. 浏览器将这个值和内容一起记录在缓存数据库中。
+
+
+3. 下一次请求相同资源时时,浏览器从自己的缓存中找出“不确定是否过期的”缓存。因此在请求头中将上次的 *Last-Modified* 的值写入到请求头的 *If-Modified-Since* 字段
+
+
+4. 服务器会将 *If-Modified-Since* 的值与 *Last-Modified* 字段进行对比。如果相等,则表示未修改,响应 *304*;反之,则表示修改了,响应 *200* 状态码,并返回数据。
+
+但是他还是有一定缺陷的:
+
+- 如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
+
+- 如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
+
+因此在 *HTTP/1.1* 出现了 *ETag* 和 *If-None-Match*
+
+
+
+#### *Etag & If-None-Match*
+
+为了解决上述问题,出现了一组新的字段 *Etag* 和 *If-None-Match*。
+
+*Etag* 存储的是文件的特殊标识(一般都是一个 *Hash* 值),服务器存储着文件的 *Etag* 字段。
+
+之后的流程和 *Last-Modified* 一致,只是 *Last-Modified* 字段和它所表示的更新时间改变成了 *Etag* 字段和它所表示的文件 *hash*,把 *If-Modified-Since* 变成了 *If-None-Match*。
+
+浏览器在下一次加载资源向服务器发送请求时,会将上一次返回的 Etag 值放到请求头里的 *If-None-Match* 里,服务器只需要比较客户端传来的 *If-None-Match* 跟自己服务器上该资源的 *ETag* 是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
+
+如果服务器发现 *ETag* 匹配不上,那么直接以常规 *GET 200* 回包形式将新的资源(当然也包括了新的 *ETag*)发给客户端;如果 *ETag* 是一致的,则直接返回 *304* 告诉客户端直接使用本地缓存即可。
+
+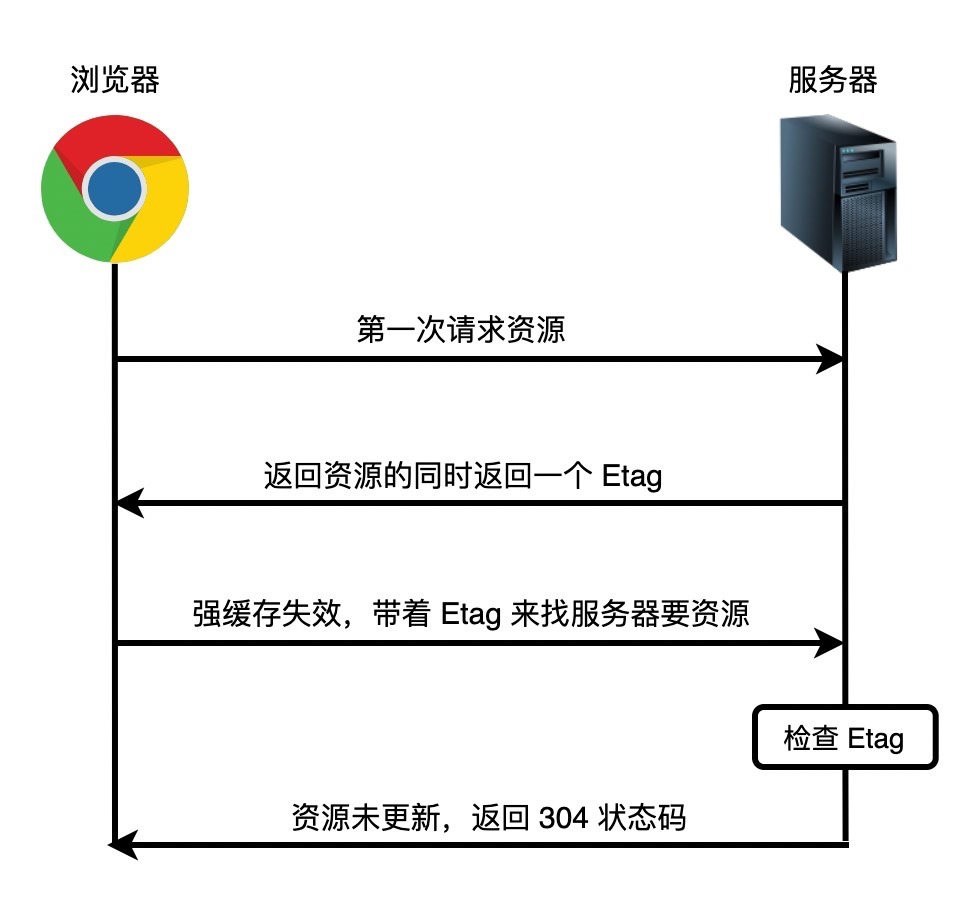 +
+
+
+两者之间的简单对比:
+
+- 首先在精确度上,*Etag* 要优于 *Last-Modified*。
+
+ *Last-Modified* 的时间单位是秒,如果某个文件在 *1* 秒内改变了多次,那么 *Last-Modified* 其实并没有体现出来修改,但是 *Etag* 是一个 *Hash* 值,每次都会改变从而确保了精度。
+
+- 第二在性能上,*Etag* 要逊于 *Last-Modified*,毕竟 *Last-Modified* 只需要记录时间,而 *Etag* 需要服务器通过算法来计算出一个 *Hash* 值。
+
+- 第三在优先级上,服务器校验优先考虑 *Etag*,也就是说 *Etag* 的优先级高于 *Last-Modified*。
+
+
+
+## 缓存读取规则
+
+接下来我们来对上面所讲的缓存做一个总结。
+
+当浏览器要请求资源时:
+
+1. 从 *Service Worker* 中获取内容( 如果设置了 *Service Worker* )
+
+2. 查看 *Memory Cache*
+
+3. 查看 *Disk Cache*。这里又细分:
+
+ - 如果有强制缓存且未失效,则使用强制缓存,不请求服务器。这时的状态码全部是 *200*
+
+ - 如果有强制缓存但已失效,使用协商缓存,比较后确定 *304* 还是 *200*
+
+4. 发送网络请求,等待网络响应
+
+5. 把响应内容存入 *Disk Cache* (如果 *HTTP* 响应头信息有相应配置的话)
+
+6. 把响应内容的引用存入 *Memory Cache* (无视 *HTTP* 头信息的配置)
+
+7. 把响应内容存入 *Service Worker* 的 *Cache Storage*( 如果设置了 *Service Worker* )
+
+其中针对第 *3* 步,具体的流程图如下:
+
+
+
+
+
+两者之间的简单对比:
+
+- 首先在精确度上,*Etag* 要优于 *Last-Modified*。
+
+ *Last-Modified* 的时间单位是秒,如果某个文件在 *1* 秒内改变了多次,那么 *Last-Modified* 其实并没有体现出来修改,但是 *Etag* 是一个 *Hash* 值,每次都会改变从而确保了精度。
+
+- 第二在性能上,*Etag* 要逊于 *Last-Modified*,毕竟 *Last-Modified* 只需要记录时间,而 *Etag* 需要服务器通过算法来计算出一个 *Hash* 值。
+
+- 第三在优先级上,服务器校验优先考虑 *Etag*,也就是说 *Etag* 的优先级高于 *Last-Modified*。
+
+
+
+## 缓存读取规则
+
+接下来我们来对上面所讲的缓存做一个总结。
+
+当浏览器要请求资源时:
+
+1. 从 *Service Worker* 中获取内容( 如果设置了 *Service Worker* )
+
+2. 查看 *Memory Cache*
+
+3. 查看 *Disk Cache*。这里又细分:
+
+ - 如果有强制缓存且未失效,则使用强制缓存,不请求服务器。这时的状态码全部是 *200*
+
+ - 如果有强制缓存但已失效,使用协商缓存,比较后确定 *304* 还是 *200*
+
+4. 发送网络请求,等待网络响应
+
+5. 把响应内容存入 *Disk Cache* (如果 *HTTP* 响应头信息有相应配置的话)
+
+6. 把响应内容的引用存入 *Memory Cache* (无视 *HTTP* 头信息的配置)
+
+7. 把响应内容存入 *Service Worker* 的 *Cache Storage*( 如果设置了 *Service Worker* )
+
+其中针对第 *3* 步,具体的流程图如下:
+
+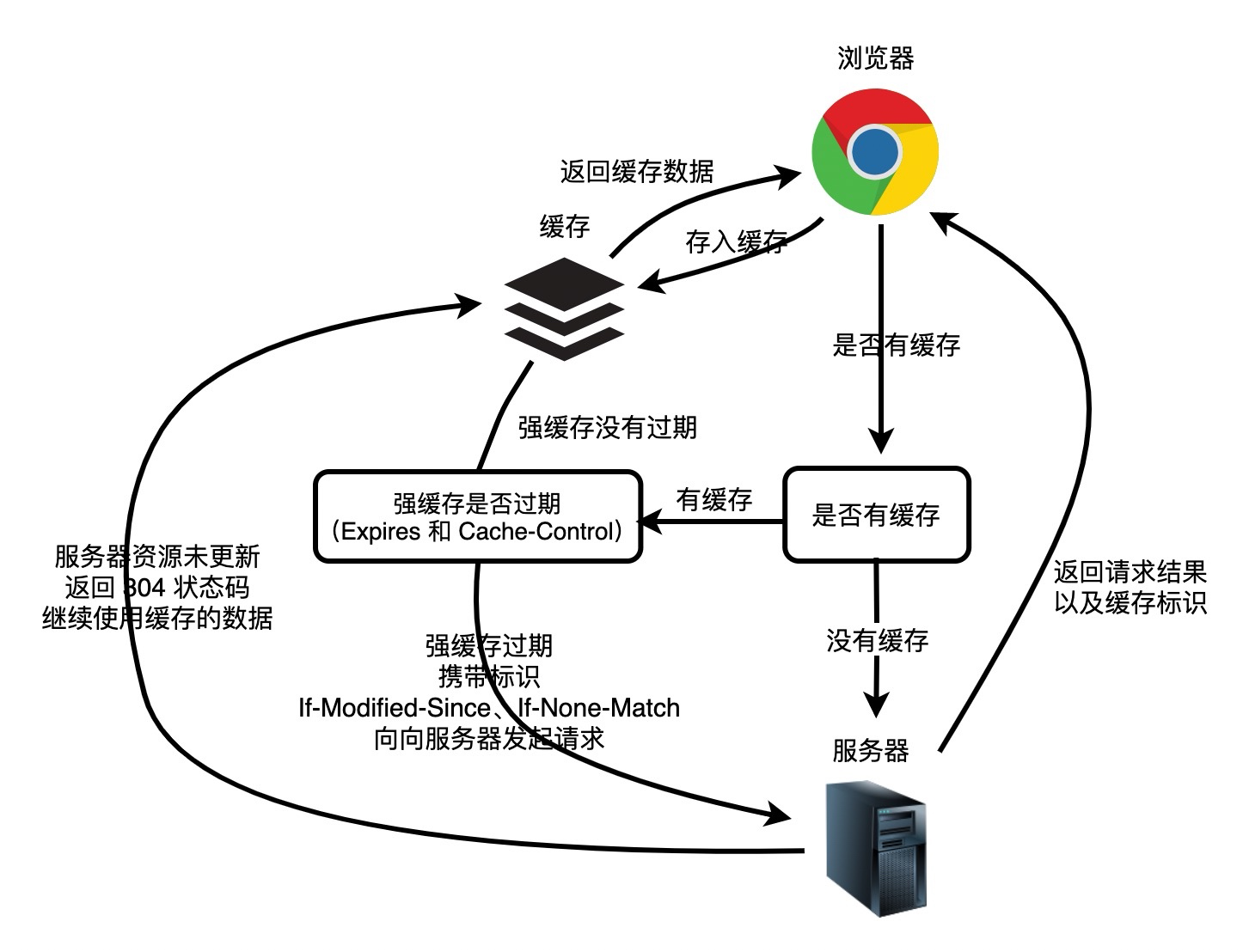 +
+
+
+## 浏览器行为
+
+在了解了整个缓存策略或者说缓存读取流程后,我们还需要了解一个东西,那就是用户对浏览器的不同操作,会触发不同的缓存读取策略。
+
+对应主要有 *3* 种不同的浏览器行为:
+
+- 打开网页,地址栏输入地址:查找 *Disk Cache* 中是否有匹配。如有则使用;如没有则发送网络请求。
+
+- 普通刷新 (F5):因为 TAB 并没有关闭,因此 *Memory Cache* 是可用的,会被优先使用(如果匹配的话)。其次才是 *Disk Cache*。
+
+- 强制刷新 ( *Ctrl + F5* ):浏览器不使用缓存,因此发送的请求头部均带有 *Cache-control: no-cache*(为了兼容,还带了 *Pragma: no-cache* )。服务器直接返回 *200* 和最新内容。
+
+
+
+## 实操案例
+
+实践才是检验真理的唯一标准。上面已经将理论部分讲解完毕了,接下来我们就来用实际代码验证一下上面所讲的验证规则。
+
+下面是使用 *Node.js* 搭建的服务器:
+
+```js
+const http = require('http');
+const path = require('path');
+const fs = require('fs');
+
+var hashStr = "A hash string.";
+var hash = require("crypto").createHash('sha1').update(hashStr).digest('base64');
+
+http.createServer(function (req, res) {
+ const url = req.url; // 获取到请求的路径
+ let fullPath; // 用于拼接完整的路径
+ if (req.headers['if-none-match'] == hash) {
+ res.writeHead(304);
+ res.end();
+ return;
+ }
+ if (url === '/') {
+ // 代表请求的是主页
+ fullPath = path.join(__dirname, 'static/html') + '/index.html';
+ } else {
+ fullPath = path.join(__dirname, "static", url);
+ res.writeHead(200, {
+ 'Cache-Control': 'max-age=5',
+ "Etag": hash
+ });
+ }
+ // 根据完整的路径 使用fs模块来进行文件内容的读取 读取内容后将内容返回
+ fs.readFile(fullPath, function (err, data) {
+ if (err) {
+ res.end(err.message);
+ } else {
+ // 读取文件成功,返回读取的内容,让浏览器进行解析
+ res.end(data);
+ }
+ });
+}).listen(3000, function () {
+ console.log("服务器已启动,监听 3000 端口...");
+})
+```
+
+在上面的代码中,我们使用 *Node.js* 创建了一个服务器,根据请求头的 *if-none-match* 字段接收从客户端传递过来的 *Etag* 值,如果和当前的 *Hash* 值相同,则返回 *304* 的状态码。
+
+在资源方面,我们除了主页没有设置缓存,其他静态资源我们设置了 *5* 秒的缓存,并且设置了 *Etag* 值。
+
+>注:上面的代码只是服务器部分代码,完整代码请参阅本章节所对应的代码。
+
+效果如下:
+
+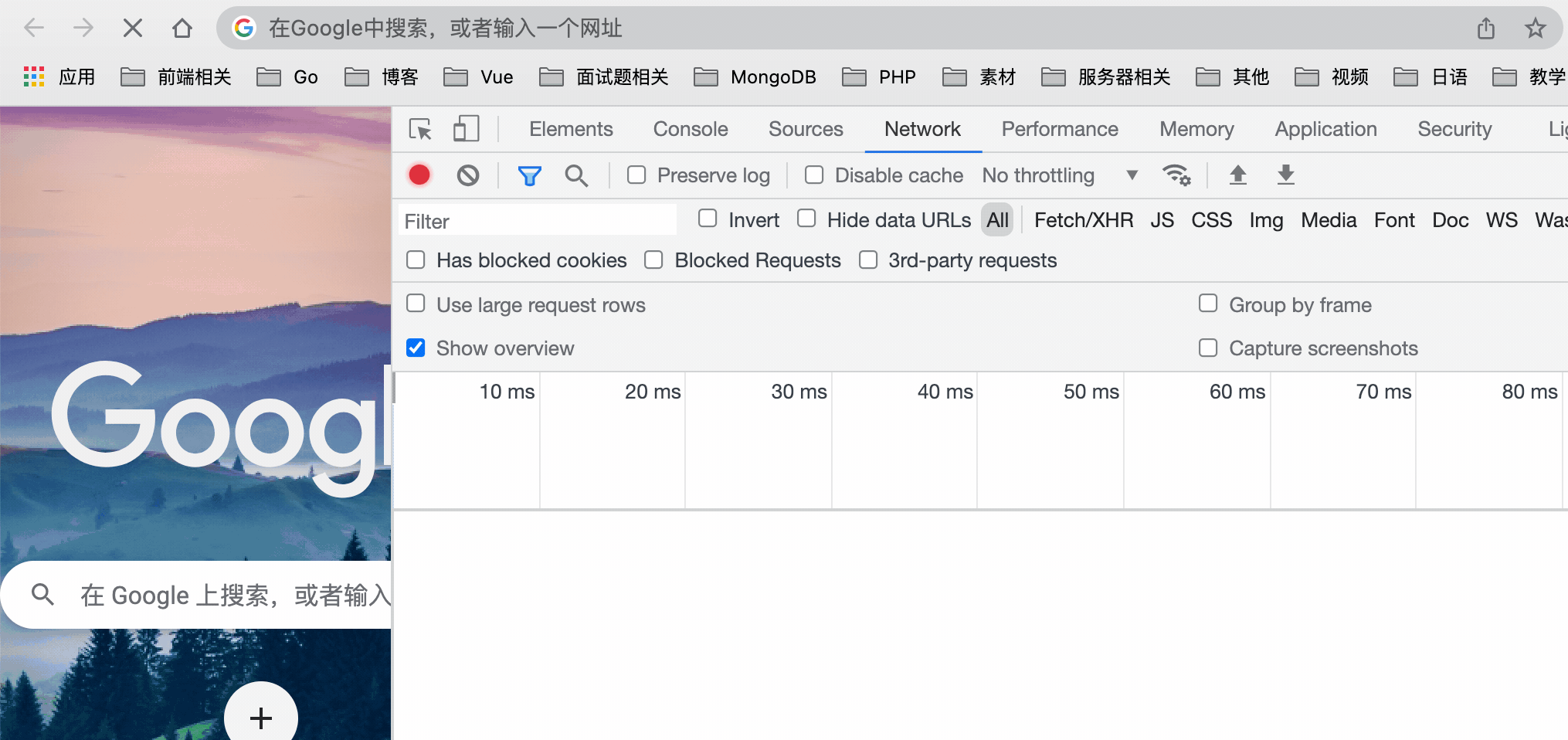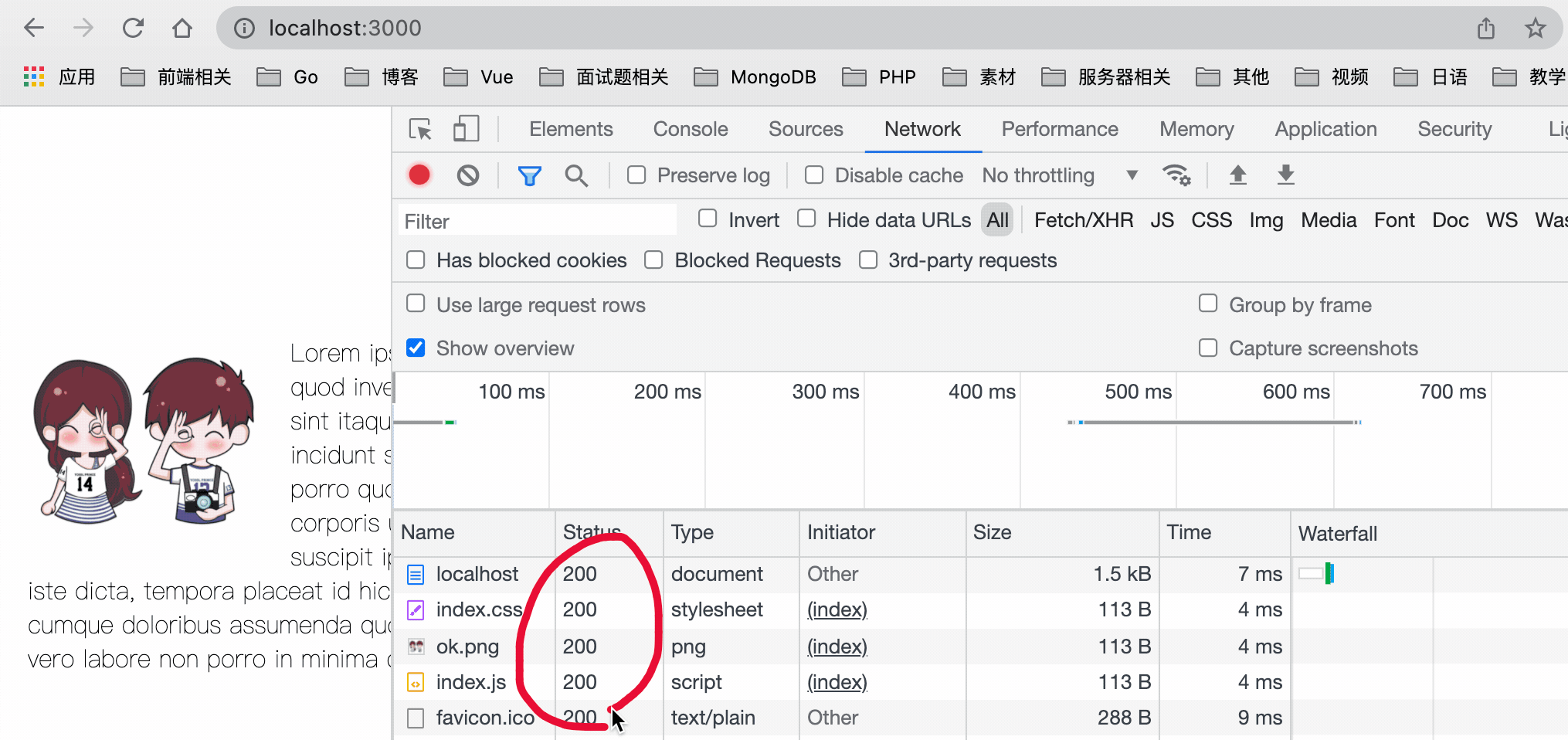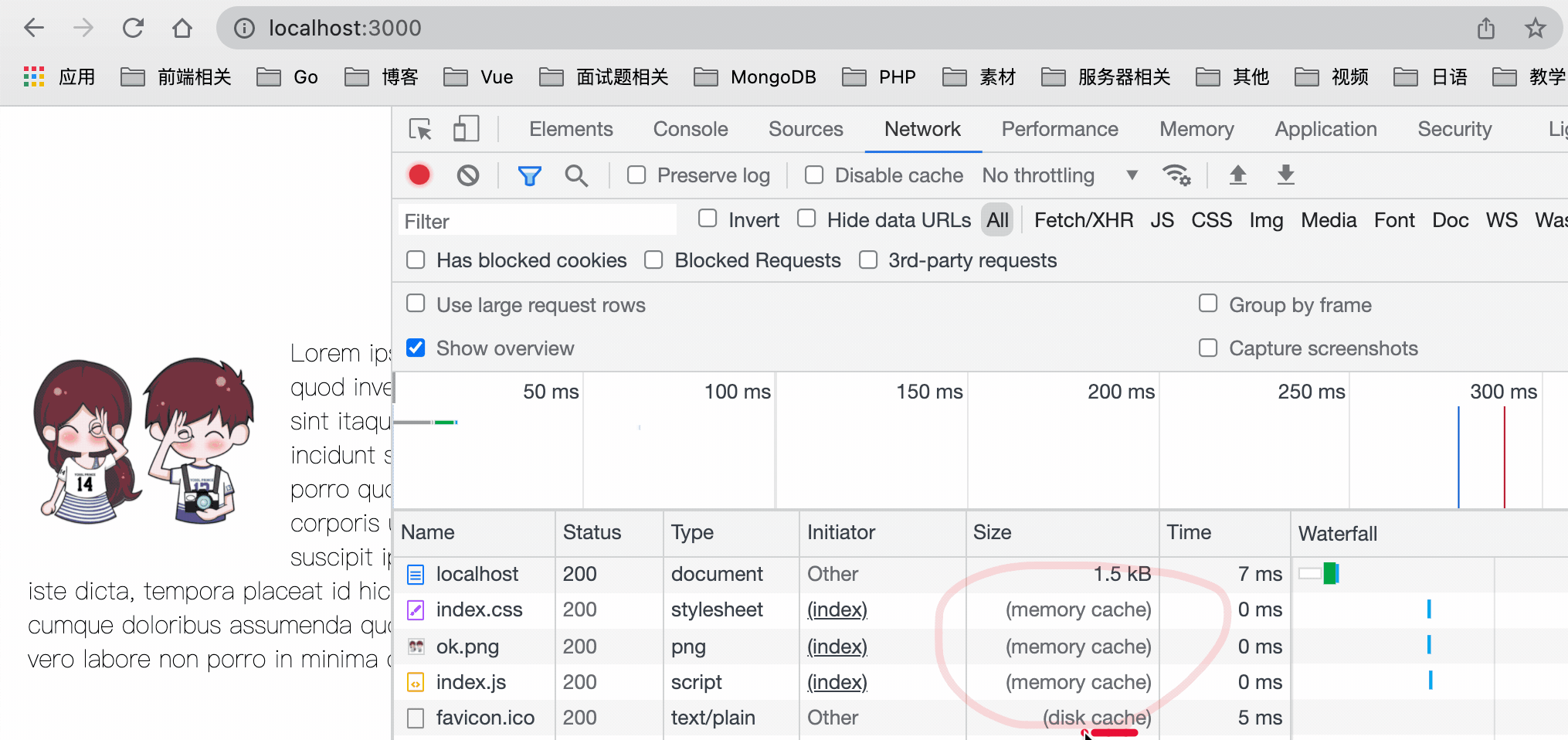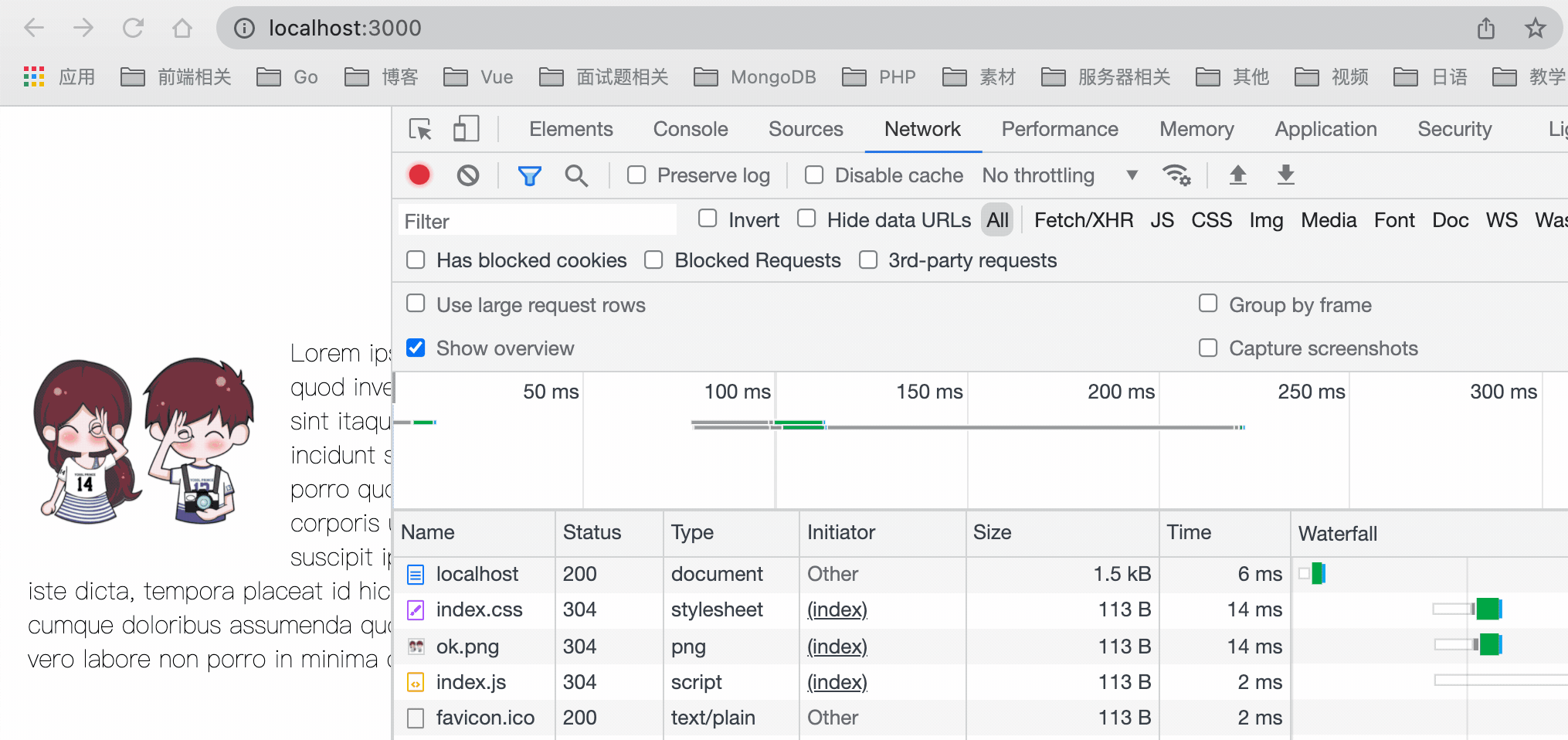
+
+
+
+可以看到,第一次请求时因为没有缓存,所以全部都是从服务器上面获取资源,之后我们刷新页面,是从 *memory cache* 中获取的资源,但是由于我们的强缓存只设置了 *5* 秒,所以之后再次刷新页面,走的就是协商缓存,返回 *304* 状态码。
+
+但是在这个示例中,如果我们修改了服务器的静态资源,客户端是没办法实时的更新的,因为静态资源是直接返回的文件,只要静态资源的文件名没变,即使该资源的内容已经发生了变化,服务器也会认为资源没有变化。
+
+那怎么解决呢?
+
+解决办法也就是我们在做静态资源构建时,在打包完成的静态资源文件名上根据它内容 *Hash* 值添加上一串 *Hash* 码,这样在 *CSS* 或者 *JS* 文件内容没有变化时,生成的文件名也就没有变化,反映到页面上的话就是 *url* 没有变化。
+
+如果你的文件内容有变化,那么对应生成的文件名后面的 *Hash* 值也会发生变化,那么嵌入到页面的文件 *url* 也就会发生变化,从而可以达到一个更新缓存的目的。这也是为什么在使用 *webpack* 等一些打包工具时,打包后的文件名后面会添加上一串 *Hash* 码的原因。
+
+目前来讲,这在前端开发中比较常见的一个静态资源缓存方案。
+
+
+
+## 缓存的最佳实践
+
+
+
+### 频繁变动的资源
+
+```
+Cache-Control: no-cache
+```
+
+对于频繁变动的资源,首先需要使用 *Cache-Control: no-cache* 使浏览器每次都请求服务器,然后配合 *ETag* 或者 *Last-Modified* 来验证资源是否有效。
+
+这样的做法虽然不能节省请求数量,但是能显著减少响应数据大小。
+
+### 不常变化的资源
+
+```
+Cache-Control: max-age=31536000
+```
+
+通常在处理这类资源时,给它们的 *Cache-Control* 配置一个很大的 *max-age=31536000* (一年),这样浏览器之后请求相同的 *URL* 会命中强制缓存。
+
+而为了解决更新的问题,就需要在文件名(或者路径)中添加 *Hash*, 版本号等动态字符,之后更改动态字符,从而达到更改引用 *URL* 的目的,让之前的强制缓存失效 (其实并未立即失效,只是不再使用了而已)。
+
+在线提供的类库(如 *jquery-3.3.1.min.js、lodash.min.js* 等)均采用这个模式。
+
+
+
+
+-------
+
+
+
+-*EOF*-
+
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/.vscode/settings.json b/05. 浏览器的缓存/浏览器缓存Demo/.vscode/settings.json
new file mode 100644
index 0000000..5165b7c
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/.vscode/settings.json
@@ -0,0 +1,3 @@
+{
+ "eggHelper.serverPort": 35684
+}
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/server.js b/05. 浏览器的缓存/浏览器缓存Demo/server.js
new file mode 100644
index 0000000..98ace68
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/server.js
@@ -0,0 +1,37 @@
+const http = require('http');
+const path = require('path');
+const fs = require('fs');
+
+var hashStr = "A hash string.";
+var hash = require("crypto").createHash('sha1').update(hashStr).digest('base64');
+
+http.createServer(function (req, res) {
+ const url = req.url; // 获取到请求的路径
+ let fullPath; // 用于拼接完整的路径
+ if (req.headers['if-none-match'] == hash) {
+ res.writeHead(304);
+ res.end();
+ return;
+ }
+ if (url === '/') {
+ // 代表请求的是主页
+ fullPath = path.join(__dirname, 'static/html') + '/index.html';
+ } else {
+ fullPath = path.join(__dirname, "static", url);
+ res.writeHead(200, {
+ 'Cache-Control': 'max-age=10',
+ "Etag": hash
+ });
+ }
+ // 根据完整的路径 使用fs模块来进行文件内容的读取 读取内容后将内容返回
+ fs.readFile(fullPath, function (err, data) {
+ if (err) {
+ res.end(err.message);
+ } else {
+ // 读取文件成功,返回读取的内容,让浏览器进行解析
+ res.end(data);
+ }
+ });
+}).listen(3000, function () {
+ console.log("服务器已启动,监听 3000 端口...");
+})
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/static/css/index.css b/05. 浏览器的缓存/浏览器缓存Demo/static/css/index.css
new file mode 100644
index 0000000..08daea3
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/static/css/index.css
@@ -0,0 +1,25 @@
+.container{
+ width: 800px;
+ margin: 50px auto;
+ padding: 10px;
+ font-weight: 100;
+}
+
+h1{
+ text-align: center;
+ font-weight: 100;
+ color : red;
+}
+
+img{
+ width: 150px;
+}
+
+img:first-of-type{
+ float: left;
+ margin-right: 20px;
+}
+
+img:last-of-type{
+ float: right;
+}
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/static/html/index.html b/05. 浏览器的缓存/浏览器缓存Demo/static/html/index.html
new file mode 100644
index 0000000..6a81aa2
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/static/html/index.html
@@ -0,0 +1,29 @@
+
+
+
+
+
+
+
+
+
+
+
+## 浏览器行为
+
+在了解了整个缓存策略或者说缓存读取流程后,我们还需要了解一个东西,那就是用户对浏览器的不同操作,会触发不同的缓存读取策略。
+
+对应主要有 *3* 种不同的浏览器行为:
+
+- 打开网页,地址栏输入地址:查找 *Disk Cache* 中是否有匹配。如有则使用;如没有则发送网络请求。
+
+- 普通刷新 (F5):因为 TAB 并没有关闭,因此 *Memory Cache* 是可用的,会被优先使用(如果匹配的话)。其次才是 *Disk Cache*。
+
+- 强制刷新 ( *Ctrl + F5* ):浏览器不使用缓存,因此发送的请求头部均带有 *Cache-control: no-cache*(为了兼容,还带了 *Pragma: no-cache* )。服务器直接返回 *200* 和最新内容。
+
+
+
+## 实操案例
+
+实践才是检验真理的唯一标准。上面已经将理论部分讲解完毕了,接下来我们就来用实际代码验证一下上面所讲的验证规则。
+
+下面是使用 *Node.js* 搭建的服务器:
+
+```js
+const http = require('http');
+const path = require('path');
+const fs = require('fs');
+
+var hashStr = "A hash string.";
+var hash = require("crypto").createHash('sha1').update(hashStr).digest('base64');
+
+http.createServer(function (req, res) {
+ const url = req.url; // 获取到请求的路径
+ let fullPath; // 用于拼接完整的路径
+ if (req.headers['if-none-match'] == hash) {
+ res.writeHead(304);
+ res.end();
+ return;
+ }
+ if (url === '/') {
+ // 代表请求的是主页
+ fullPath = path.join(__dirname, 'static/html') + '/index.html';
+ } else {
+ fullPath = path.join(__dirname, "static", url);
+ res.writeHead(200, {
+ 'Cache-Control': 'max-age=5',
+ "Etag": hash
+ });
+ }
+ // 根据完整的路径 使用fs模块来进行文件内容的读取 读取内容后将内容返回
+ fs.readFile(fullPath, function (err, data) {
+ if (err) {
+ res.end(err.message);
+ } else {
+ // 读取文件成功,返回读取的内容,让浏览器进行解析
+ res.end(data);
+ }
+ });
+}).listen(3000, function () {
+ console.log("服务器已启动,监听 3000 端口...");
+})
+```
+
+在上面的代码中,我们使用 *Node.js* 创建了一个服务器,根据请求头的 *if-none-match* 字段接收从客户端传递过来的 *Etag* 值,如果和当前的 *Hash* 值相同,则返回 *304* 的状态码。
+
+在资源方面,我们除了主页没有设置缓存,其他静态资源我们设置了 *5* 秒的缓存,并且设置了 *Etag* 值。
+
+>注:上面的代码只是服务器部分代码,完整代码请参阅本章节所对应的代码。
+
+效果如下:
+
+
+
+
+
+可以看到,第一次请求时因为没有缓存,所以全部都是从服务器上面获取资源,之后我们刷新页面,是从 *memory cache* 中获取的资源,但是由于我们的强缓存只设置了 *5* 秒,所以之后再次刷新页面,走的就是协商缓存,返回 *304* 状态码。
+
+但是在这个示例中,如果我们修改了服务器的静态资源,客户端是没办法实时的更新的,因为静态资源是直接返回的文件,只要静态资源的文件名没变,即使该资源的内容已经发生了变化,服务器也会认为资源没有变化。
+
+那怎么解决呢?
+
+解决办法也就是我们在做静态资源构建时,在打包完成的静态资源文件名上根据它内容 *Hash* 值添加上一串 *Hash* 码,这样在 *CSS* 或者 *JS* 文件内容没有变化时,生成的文件名也就没有变化,反映到页面上的话就是 *url* 没有变化。
+
+如果你的文件内容有变化,那么对应生成的文件名后面的 *Hash* 值也会发生变化,那么嵌入到页面的文件 *url* 也就会发生变化,从而可以达到一个更新缓存的目的。这也是为什么在使用 *webpack* 等一些打包工具时,打包后的文件名后面会添加上一串 *Hash* 码的原因。
+
+目前来讲,这在前端开发中比较常见的一个静态资源缓存方案。
+
+
+
+## 缓存的最佳实践
+
+
+
+### 频繁变动的资源
+
+```
+Cache-Control: no-cache
+```
+
+对于频繁变动的资源,首先需要使用 *Cache-Control: no-cache* 使浏览器每次都请求服务器,然后配合 *ETag* 或者 *Last-Modified* 来验证资源是否有效。
+
+这样的做法虽然不能节省请求数量,但是能显著减少响应数据大小。
+
+### 不常变化的资源
+
+```
+Cache-Control: max-age=31536000
+```
+
+通常在处理这类资源时,给它们的 *Cache-Control* 配置一个很大的 *max-age=31536000* (一年),这样浏览器之后请求相同的 *URL* 会命中强制缓存。
+
+而为了解决更新的问题,就需要在文件名(或者路径)中添加 *Hash*, 版本号等动态字符,之后更改动态字符,从而达到更改引用 *URL* 的目的,让之前的强制缓存失效 (其实并未立即失效,只是不再使用了而已)。
+
+在线提供的类库(如 *jquery-3.3.1.min.js、lodash.min.js* 等)均采用这个模式。
+
+
+
+
+-------
+
+
+
+-*EOF*-
+
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/.vscode/settings.json b/05. 浏览器的缓存/浏览器缓存Demo/.vscode/settings.json
new file mode 100644
index 0000000..5165b7c
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/.vscode/settings.json
@@ -0,0 +1,3 @@
+{
+ "eggHelper.serverPort": 35684
+}
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/server.js b/05. 浏览器的缓存/浏览器缓存Demo/server.js
new file mode 100644
index 0000000..98ace68
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/server.js
@@ -0,0 +1,37 @@
+const http = require('http');
+const path = require('path');
+const fs = require('fs');
+
+var hashStr = "A hash string.";
+var hash = require("crypto").createHash('sha1').update(hashStr).digest('base64');
+
+http.createServer(function (req, res) {
+ const url = req.url; // 获取到请求的路径
+ let fullPath; // 用于拼接完整的路径
+ if (req.headers['if-none-match'] == hash) {
+ res.writeHead(304);
+ res.end();
+ return;
+ }
+ if (url === '/') {
+ // 代表请求的是主页
+ fullPath = path.join(__dirname, 'static/html') + '/index.html';
+ } else {
+ fullPath = path.join(__dirname, "static", url);
+ res.writeHead(200, {
+ 'Cache-Control': 'max-age=10',
+ "Etag": hash
+ });
+ }
+ // 根据完整的路径 使用fs模块来进行文件内容的读取 读取内容后将内容返回
+ fs.readFile(fullPath, function (err, data) {
+ if (err) {
+ res.end(err.message);
+ } else {
+ // 读取文件成功,返回读取的内容,让浏览器进行解析
+ res.end(data);
+ }
+ });
+}).listen(3000, function () {
+ console.log("服务器已启动,监听 3000 端口...");
+})
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/static/css/index.css b/05. 浏览器的缓存/浏览器缓存Demo/static/css/index.css
new file mode 100644
index 0000000..08daea3
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/static/css/index.css
@@ -0,0 +1,25 @@
+.container{
+ width: 800px;
+ margin: 50px auto;
+ padding: 10px;
+ font-weight: 100;
+}
+
+h1{
+ text-align: center;
+ font-weight: 100;
+ color : red;
+}
+
+img{
+ width: 150px;
+}
+
+img:first-of-type{
+ float: left;
+ margin-right: 20px;
+}
+
+img:last-of-type{
+ float: right;
+}
\ No newline at end of file
diff --git a/05. 浏览器的缓存/浏览器缓存Demo/static/html/index.html b/05. 浏览器的缓存/浏览器缓存Demo/static/html/index.html
new file mode 100644
index 0000000..6a81aa2
--- /dev/null
+++ b/05. 浏览器的缓存/浏览器缓存Demo/static/html/index.html
@@ -0,0 +1,29 @@
+
+
+
+
+
+
+
+ 这是一个测试页面
+ +
+
+
+ Lorem ipsum dolor, sit amet consectetur adipisicing elit. Tempore quod inventore recusandae? Reiciendis, + vitae dolorem voluptatem sint itaque deleniti. Asperiores laudantium dignissimos commodi et incidunt + suscipit qui nemo? Dolorum consectetur pariatur non porro quod, delectus saepe ullam quis ea labore dolorem, + totam corporis unde! Laborum quia quibusdam sapiente ex, voluptatem suscipit ipsam voluptas beatae quos + optio culpa nulla assumenda iste dicta, tempora placeat id hic? Temporibus ducimus qui quaerat accusantium + nisi rem vel eligendi eaque cumque doloribus assumenda quod quisquam quos ipsam suscipit, labore + perspiciatis neque quis! Quam quos vero labore non porro in minima deleniti architecto sint, recusandae + assumenda?
+