# JS中的数据类型
>面试题:JS 中的数据类型有哪些?基本类型和引用类型的区别是什么?
- 简单值和复杂值
- 两者之间本质区别
- 两者之间行为区别
## 简单值和复杂值
JS 中的数据类型就分为**两大类**:
- 简单值(基本类型、原始类型)
- 复杂值(引用值、引用类型)
### 1. 简单值
一共**有 7 种**:
- number:数字
- string:字符串
- boolean:布尔值
- undefined:未定义
- null:空
- symbol:符号
- bigint:大数
所谓简单值,是因为**这些类型的值,无法再继续往下拆分**。
**注意点1: symbol 和 bigint**
这两种数据类型从 ES6 开始新增的。
symbol 这种类型主要用于**创建唯一的标识符**。symbol 的值是唯一且不可变的,适用于作为对象属性的键,以及保证不会与其他属性键发生冲突,特别是在多人合作的大型项目中或者当你使用第三方库的时候。
bigint 是一种新增的基本数据类型,它于 ECMAScript 2020(ES11)中被正式添加到语言标准中。bigint 数据类型用于表示大于Number.MAX_SAFE_INTEGER(即 `2^53 - 1`)或小于 Number.MIN_SAFE_INTEGER(即`-2^53 + 1`)的整数。这个类型**提供了一种在 JS 中安全处理非常大的整数的方法**,这在之前的 JS 版本中是不可能的。这种类型非常适合于用在金融、科学计算和加密等领域。
**注意点2: null 和 undefined**
>面试题1:为什么 null 的数据类型打印出来为 object ?
```js
console.log(typeof null); // object
console.log(typeof undefined); // undefined
```
这其实是 JS 从第一个版本开始时,**设计上的一个遗留问题**。最初的 JS 语言实现是在 1995 年由 Brendan Eich 在 Netscape Navigator 中设计的。在 JS 最初的版本中,**数据类型是使用底层的位模式来标识的,每种数据类型的前几位是用来表示类型信息的**。例如,**对象的类型标记通常以 00 开头**,而由于一个历史错误,**null 被表示为全零(00000000)**,这就使得 null 的类型检查结果与对象一致。
虽然这个行为在技术上是不正确的(因为 null 既不是对象也不包含任何属性),但改变这个行为可能会破坏大量现存的 Web 页面和应用。因此,尽管这是一个众所周知的问题,但由于向后兼容性的考虑,这个设计决策一直未被修改。
不仅没有修改,这个行为目前还被 ECMAScript 标准所采纳,成为了规范的一部分,所有遵循 ECMAScript 标准的 JS 实现都默认在 typeof null 时返回 object.
>面试题2:为什么 undefined 和 null 明明是两种基础数据类型,但 undefined == null 返回的是 true ?
这个问题其实也是一个历史问题。众所周知,JS 是借鉴了在当时很多已有的语言的一个产物。其中关于“无”这个概念,JS 就是借鉴的 Java,使用 null 来表示“无”的意思,而根据 C 语言的传统,null 被设计成可以自动转为 0.
但是 Brendan Eich 觉得这么做还不够,主要是因为如下两个原因:
1. 由于前面所介绍的设计上的失误,获取 null 的数据类型会得到一个 obect,这在开发上会带来一些未知的问题。
2. JS 在设计之初就是弱类型语言,当发生数据类型不匹配的时候,往往会自动数据类型转换或者静默失败,null 自动转为 0 的话也很不容易发现错误。
基于上面的这些理由,Brendan Eich 又设计出来了 undefined. 也就是说,undefined 实际上是为了填补 null 所带来的坑。
```js
console.log(null + 1); // 1
console.log(undefined + 1); // NaN
```
目前来讲,关于 null 和 undefined 主要区别总结如下:
- null:从语义上来讲就是表示对象的 “无”
- 转为数值时会被转换为 0
- 作为原型链的终点
- undefined:从语义上来讲就是表示简单值的“无”
- 转为数值为 NaN
- 变量声明了没有赋值,那么默认值为 undefined.
- 调用函数没有提供要求的参数,那么该参数就是 undefined
- 函数没有返回值的时候,默认返回 undefined.
### 2. 复杂值
**复杂值就一种**:object
之所以被称之为复杂值,就是**因为这种类型的值可以继续往下拆分,分为多个简单值或者复杂值**。
```js
const obj = {
name: "张三",
age: 18,
scores: {
"htmlScore": 99,
"cssScore": 95
}
};
```
**像数组、函数、正则这些统统都是对象类型,属于复杂值**
```js
console.log(typeof []); // object
console.log(typeof function () {}); // function
console.log(typeof /abc/); // object
```
**函数的本质也是对象。**
```js
function func() {}
// 该函数我是可以正常添加属性和方法的
func.a = 1; // 添加了一个属性
func.test = function () {
console.log("this is a test function");
}; // 添加了一个方法
console.log(func.a); // 1
func.test(); // this is a test function
```
在函数内部有一个特别的内部属性 `[[Call]]`,这个是属于内部代码,开发者层面是没有办法调用的。但是**有了这个属性之后,表示这个对象是可以被调用。**
因为函数是可调用的对象,为了区分 **普通对象** 和 **函数对象**,因此当我们使用 typeof 操作符检测一个函数时,它返回的是 function。
也正因为这种设计,所以 JS 中能够实现高阶函数。高阶函数的定义:
- 接受一个或多个函数作为输入
- 输出一个函数
因为在 JS 中,函数的本质就是对象,因此可以像其他普通对象一样,作为参数或者返回值进行传递。这也是 JS 中所说的函数是一等公民这个说法的由来。
## 两者之间本质区别
介绍完了简单值和复杂值之后,接下来我们从内存存储的角度,来看一下这两种本质上的区别。
我们知道,内存的存储区域可以分为 **栈** 和 **堆** 这两大块。
- 栈内存:**栈内存因为其数据大小和生命周期的可预测性而易于管理和快速访问**。栈支持快速的数据分配和销毁过程,**但它不适合复杂的或大规模的数据结构**。
- 堆内存:**堆内存更加灵活,可以动态地分配和释放空间,适合存储生命周期长或大小不确定的数据**。使用堆内存可以有效地管理大量的数据,但相对于栈来说,其管理成本更高,访问速度也较慢。
对于**简单值而言,它们通常存储在栈内存里面**。上面说了,栈内存的特点是管理简单且访问速度快,适用于存储 **大小固定、生命周期短** 的数据。简单值的存储通常包括直接在栈内存中分配的数据空间,并且直接存储了数据的实际值。
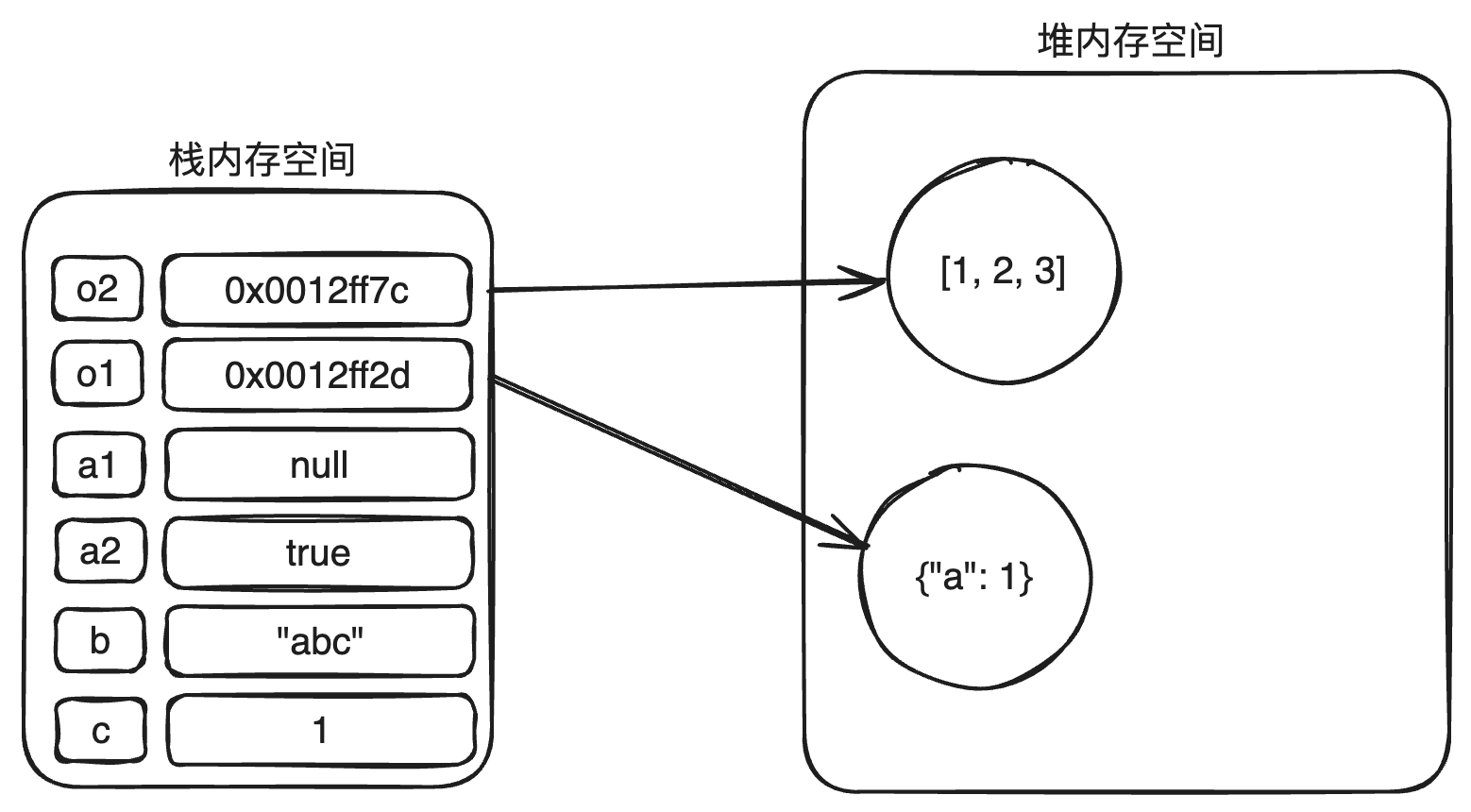
 而对于复杂值而言,具体的值是存储在 **堆内存** 里面的。因为**复杂值往往大小是不固定的,无法在栈区分配一个固定大小的内存**,因此**具体的数据放在堆里面**。那么这就没有栈区什么事儿了么?倒也不是,**栈区会存储一个内存地址**,通过该内存地址可以访问到堆区里面具体的数据。
而对于复杂值而言,具体的值是存储在 **堆内存** 里面的。因为**复杂值往往大小是不固定的,无法在栈区分配一个固定大小的内存**,因此**具体的数据放在堆里面**。那么这就没有栈区什么事儿了么?倒也不是,**栈区会存储一个内存地址**,通过该内存地址可以访问到堆区里面具体的数据。
 另外讲到这里,还有一个非常重要的点要提一下,那就是 **JS 中在调用函数的时候,通通都是值传递,而非引用传递**。
```js
function test(obj) {
obj.a = 1000;
}
const obj = {};
console.log(obj); // {}
test(obj);
console.log(obj); // { a: 1000 }
```
上面的代码,有一定的迷惑性。你看到上面的代码,觉得调用函数之后,obj 发生了真实的修改,所以这是一个引用传递。
但是这里**仍然是一个值传递**。只不过这个值的背后对应的是一个地址值,这个地址值和简单值一模一样,会被复制一份传递给函数,然后函数内部拿到的是地址值,就可以通过这个地址值找到同一份堆区数据。
```js
function test(obj) {
obj = {b:1}; // 这里就赋值了一个新对象,不再使用原来的对象
obj.a = 1000;
}
const obj = {};
console.log(obj); // {}
test(obj);
console.log(obj); // {}
```
如果是真正的引用传递,那么函数内部的 obj 和外部的 obj 是绑在一起的,函数内部对 obj 做任何修改,都会影响外部。但是上面的代码中,很明显在函数内部对 obj 重新赋值后,断开了内外的联系,因此**在 JS 中只有值传递**。
## 两者之间行为区别
聊完了本质区别后,接下来我们再来聊一下两者之间行为的区别,主要就下面这么几个点:
1. 访问方式
2. 比较方式
3. 动态属性
4. 变量赋值
### 1. 访问方式
简单值是 **按值访问**,也就是说,一个变量如果存储的是一个简单值,当访问这个变量的时候,得到就是对应的值。
```js
const str = "Hello";
console.log(str);
```
复杂值是虽然也是 **按值访问** ,但是由于值对应的是一个 **内存地址值**,一般不能够直接使用,还需要进一步获取地址值背后对应的值。
```js
const obj = {name: "张三"};
console.log(obj.name);
```
### 2. 比较方式
这个比较重要,**无论是简单值也好,复杂值也好,都是进行的值比较**。不过由于复杂值对应的值是一个 **内存地址值**,因此只有在这个内存地址值相同时,才会被认为是相等。
```js
const a = {}; // 内存地址不一样,假设 0x0012ff7c
const b = {}; // 内存地址不一样,假设 0x0012ff7d
console.log(a === b); // false
```
### 3. 动态属性
对于**复杂值来讲,可以动态的为其添加属性和方法,这一点简单值是做不到的**。
如果为简单值动态添加属性,不会报错,会静默失败,访问时返回的值为 undefined
但如果为简单值动态添加方法,则会报错 xxx is not a function.
```js
const a = 1;
a.b = 2;
console.log(a.b); // undefined
a.c = function(){}
a.c(); // error
```
### 4. 变量赋值
最后说一下关于赋值,记住,它们都是 **将值复制一份** 然后赋值给另外一个变量。
不过由于复杂值复制的是 **内存地址**,因此修改新的变量会对旧的变量有影响。
```js
let a = 5;
let b = a;
b = 10; // 不影响 a
console.log(a);
console.log(b);
let obj = {};
let obj2 = obj;
obj2.name = "张三"; // 会影响 obj
console.log(obj); // { name: '张三' }
console.log(obj2); // { name: '张三' }
obj2 = { name: '张三' };
obj2.age = 18; // 不会影响 obj
console.log(obj)
console.log(obj2)
```
---
-EOF-
另外讲到这里,还有一个非常重要的点要提一下,那就是 **JS 中在调用函数的时候,通通都是值传递,而非引用传递**。
```js
function test(obj) {
obj.a = 1000;
}
const obj = {};
console.log(obj); // {}
test(obj);
console.log(obj); // { a: 1000 }
```
上面的代码,有一定的迷惑性。你看到上面的代码,觉得调用函数之后,obj 发生了真实的修改,所以这是一个引用传递。
但是这里**仍然是一个值传递**。只不过这个值的背后对应的是一个地址值,这个地址值和简单值一模一样,会被复制一份传递给函数,然后函数内部拿到的是地址值,就可以通过这个地址值找到同一份堆区数据。
```js
function test(obj) {
obj = {b:1}; // 这里就赋值了一个新对象,不再使用原来的对象
obj.a = 1000;
}
const obj = {};
console.log(obj); // {}
test(obj);
console.log(obj); // {}
```
如果是真正的引用传递,那么函数内部的 obj 和外部的 obj 是绑在一起的,函数内部对 obj 做任何修改,都会影响外部。但是上面的代码中,很明显在函数内部对 obj 重新赋值后,断开了内外的联系,因此**在 JS 中只有值传递**。
## 两者之间行为区别
聊完了本质区别后,接下来我们再来聊一下两者之间行为的区别,主要就下面这么几个点:
1. 访问方式
2. 比较方式
3. 动态属性
4. 变量赋值
### 1. 访问方式
简单值是 **按值访问**,也就是说,一个变量如果存储的是一个简单值,当访问这个变量的时候,得到就是对应的值。
```js
const str = "Hello";
console.log(str);
```
复杂值是虽然也是 **按值访问** ,但是由于值对应的是一个 **内存地址值**,一般不能够直接使用,还需要进一步获取地址值背后对应的值。
```js
const obj = {name: "张三"};
console.log(obj.name);
```
### 2. 比较方式
这个比较重要,**无论是简单值也好,复杂值也好,都是进行的值比较**。不过由于复杂值对应的值是一个 **内存地址值**,因此只有在这个内存地址值相同时,才会被认为是相等。
```js
const a = {}; // 内存地址不一样,假设 0x0012ff7c
const b = {}; // 内存地址不一样,假设 0x0012ff7d
console.log(a === b); // false
```
### 3. 动态属性
对于**复杂值来讲,可以动态的为其添加属性和方法,这一点简单值是做不到的**。
如果为简单值动态添加属性,不会报错,会静默失败,访问时返回的值为 undefined
但如果为简单值动态添加方法,则会报错 xxx is not a function.
```js
const a = 1;
a.b = 2;
console.log(a.b); // undefined
a.c = function(){}
a.c(); // error
```
### 4. 变量赋值
最后说一下关于赋值,记住,它们都是 **将值复制一份** 然后赋值给另外一个变量。
不过由于复杂值复制的是 **内存地址**,因此修改新的变量会对旧的变量有影响。
```js
let a = 5;
let b = a;
b = 10; // 不影响 a
console.log(a);
console.log(b);
let obj = {};
let obj2 = obj;
obj2.name = "张三"; // 会影响 obj
console.log(obj); // { name: '张三' }
console.log(obj2); // { name: '张三' }
obj2 = { name: '张三' };
obj2.age = 18; // 不会影响 obj
console.log(obj)
console.log(obj2)
```
---
-EOF-