Vue
' ``` 那么整个状态的迁移过程如下: 1. 状态机一开始处于 **初始状态**。 2. 在 **初始状态** 下,读取字符串的第一个字符 < ,然后状态机的状态会更新为 **标签开始状态**。 3. 接下来继续读取下一个字符 p,由于 p 是字母,所以状态机的状态会更新为 **标签名称开始状态**。 4. 接下来读取的下一个字符为 >,状态机的状态会回到 **初始状态**,并且会记录在标签状态下产生的标签名称 p。 5. 读取下一个字符 V,此时状态机会进入到 **文本状态**。 6. 读取下一个字符 u,状态机仍然是 **文本状态**。 7. 读取下一个字符 e,状态机仍然是 **文本状态**。 8. 读取下一个字符 <,此时状态机会进入到 **标签开始状态**。 9. 读取下一个字符 / ,状态机会进入到 **标签结束状态**。 10. 读取下一个字符 p,状态机进入 **标签名称结束状态**。 11. 读取下一个字符 >,状态机进重新回到 **初始状态**。 具体如下图所示: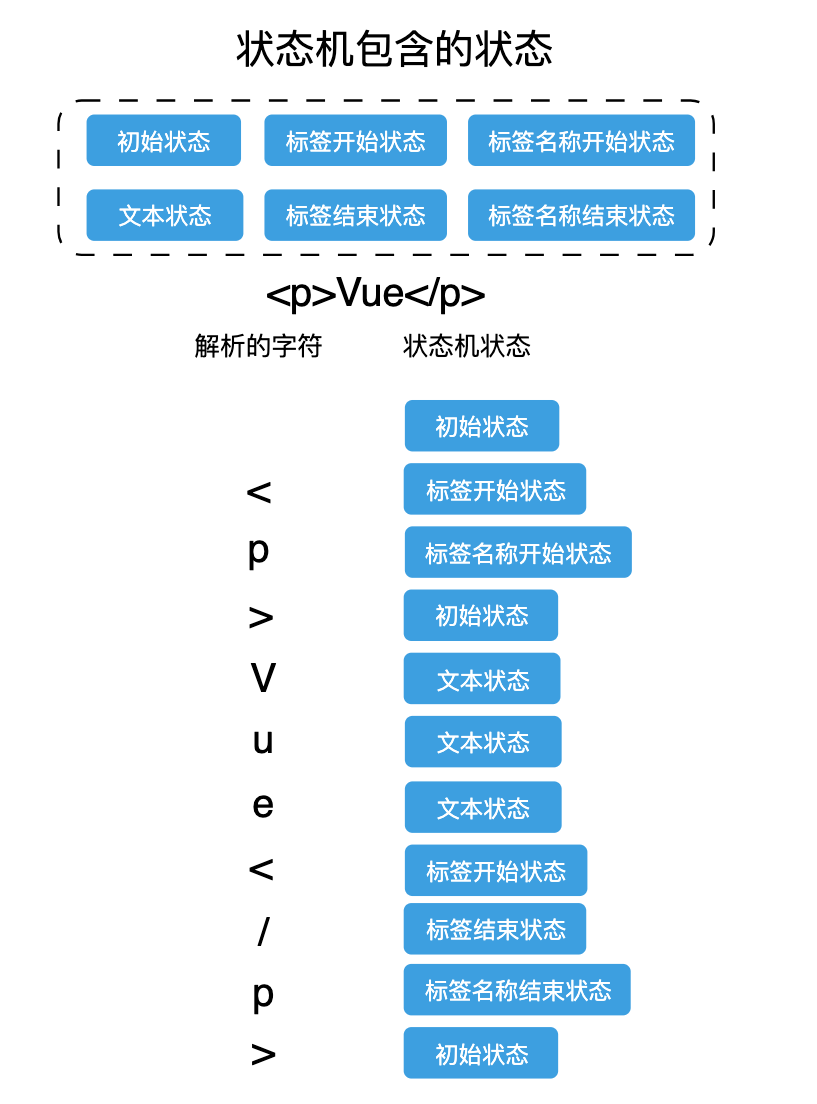 ```js
let x = 10 + 5;
```
```
token:
let(关键字) x(标识符) =(运算符) 10(数字) +(运算符) 5(数字) ;(分号)
```
对应代码:
```js
const template = '
```js
let x = 10 + 5;
```
```
token:
let(关键字) x(标识符) =(运算符) 10(数字) +(运算符) 5(数字) ;(分号)
```
对应代码:
```js
const template = 'Vue
'; // 首先定义一些状态 const State = { initial: 1, // 初始状态 tagOpen: 2, // 标签开始状态 tagName: 3, // 标签名称开始状态 text: 4, // 文本状态 tagEnd: 5, // 标签结束状态 tagEndName: 6 // 标签名称结束状态 } // 判断字符是否为字母 function isAlpha(char) { return (char >= "a" && char <= "z") || (char >= "A" && char <= "Z"); } // 将字符串解析为 token function tokenize(str){ // 初始化当前状态 let currentState = State.initial; // 用于缓存字符 const chars = []; // 存储解析出来的 token const tokens = []; while(str){ const char = str[0]; // 获取字符串里面的第一个字符 switch(currentState){ case State.initial:{ if(char === '<'){ currentState = State.tagOpen; // 消费一个字符 str = str.slice(1); } else if(isAlpha(char)){ // 判断是否为字母 currentState = State.text; chars.push(char); // 消费一个字符 str = str.slice(1); } break; } case State.tagOpen: { // 相应的状态处理 } case State.tagName: { // 相应的状态处理 } } } return tokens; } tokenize(template); ``` 最终解析出来的 token: ```js [ {type: 'tag', name: 'p'}, // 开始标签 {type: 'text', content: 'Vue'}, // 文本节点 {type: 'tagEnd', name: 'p'}, // 结束标签 ] ``` **构造模板AST** 根据 token 列表创建模板 AST 的过程,其实就是对 token 列表进行扫描的过程。从列表的第一个 token 开始,按照顺序进行扫描,直到列表中所有的 token 处理完毕。 在这个过程中,我们需**要维护一个栈**,这个栈将用于维护元素间的父子关系。每遇到一个开始标签节点,就构造一个 Element 类型的 AST 节点,并将其压入栈中。 类似的,每当遇到一个结束标签节点,我们就将当前栈顶的节点弹出。 举个例子,假设我们有如下的模板内容: ```vue 'Vue
React
 3. 接下来是 **p tag**,创建一个 Element 类型的 AST 节点,同样会压栈到 elementStack,当前的栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
3. 接下来是 **p tag**,创建一个 Element 类型的 AST 节点,同样会压栈到 elementStack,当前的栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
 4. 接下来是 **Vue text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
4. 接下来是 **Vue text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
 5. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
6. 接下来是 **p tag**,同样创建一个 Element 类型的 AST 节点,压栈后栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
5. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
6. 接下来是 **p tag**,同样创建一个 Element 类型的 AST 节点,压栈后栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
 7. 接下来是 **React text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
7. 接下来是 **React text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
 8. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
9. 最后是 **div tagEnd**,发现是一个结束标签,将其弹出,栈区重新为 `[ Root ]`,至此整个 AST 构建完毕
落地到具体的代码,大致就是这样的:
```js
// 解析器
function parse(str){
const tokens = tokenize(str);
// 创建Root根AST节点
const root = {
type: 'Root',
children: []
}
// 创建一个栈
const elementStack = [root]
while(tokens.length){
// 获取当前栈顶点作为父节点,也就是栈数组最后一项
const parent = elementStack[elementStack.length - 1];
// 从 tokens 列表中依次取出第一个 token
const t = tokens[0];
switch(t.type){
// 根据不同的type做不同的处理
case 'tag':{
// 创建一个Element类型的AST节点
const elementNode = {
type: 'Element',
tag: t.name,
children: []
}
// 将其添加为父节点的子节点
parent.children.push(elementNode)
// 将当前节点压入栈里面
elementStack.push(elementNode)
break;
}
case 'text':
// 创建文本类型的 AST 节点
const textNode = {
type: 'Text',
content: t.content
}
// 将其添加到父级节点的 children 中
parent.children.push(textNode)
break
case 'tagEnd':
// 遇到结束标签,将当前栈顶的节点弹出
elementStack.pop()
break
}
// 将处理过的 token 弹出去
tokens.shift();
}
}
```
最终,经过上面的处理,就得到了模板的抽象语法树:
```
{
"type": "Root",
"children": [
{
"type": "Element",
"tag": "div",
"children": [
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "Vue"
}
]
},
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "React"
}
]
}
]
}
]
}
```
**转换器**
目前为止,我们已经得到了模板的 AST,回顾一下 Vue 中整个模板的编译过程,大致如下:
```js
// 编译器
function compile(template){
// 1. 解析器对模板进行解析,得到模板的AST
const ast = parse(template)
// 2. 转换器:将模板AST转换为JS AST
transform(ast)
// 3. 生成器:在 JS AST 的基础上生成 JS 代码
const code = genrate(ast)
return code;
}
```
转换器的核心作用就是负责将模板 AST 转换为 JavaScript AST。
整体来讲,转换器的编写分为两大部分:
- 模板 AST 的遍历与转换
- 生成 JavaScript AST
**模板AST的遍历与转换**
步骤一:先书写一个简单的工具方法,方便查看一个模板 AST 中的节点信息。
```js
function dump(node, indent = 0) {
// 获取当前节点的类型
const type = node.type;
// 根据节点类型构建描述信息
// 对于根节点,描述为空;对于元素节点,使用标签名;对于文本节点,使用内容
const desc =
node.type === "Root"
? ""
: node.type === "Element"
? node.tag
: node.content;
// 打印当前节点信息,包括类型和描述
// 使用重复的"-"字符来表示缩进(层级)
console.log(`${"-".repeat(indent)}${type}: ${desc}`);
// 如果当前节点有子节点,递归调用dump函数打印每个子节点
if (node.children) {
node.children.forEach((n) => dump(n, indent + 2));
}
}
```
步骤二:接下来下一步就是遍历整棵模板 AST 树,并且能够做一些改动
```js
function tranverseNode(ast){
// 获取到当前的节点
const currentNode = ast;
// 将p修改为h1
if(currentNode.type === 'Element' && currentNode.tag === 'p'){
currentNode.tag = 'h1';
}
// 新增需求:将文本节点全部改为大写
if(currentNode.type === 'Text'){
currentNode.content = currentNode.content.toUpperCase();
}
// 获取当前节点的子节点
const children = currentNode.children;
if(children){
for(let i = 0;i< children.length; i++){
tranverseNode(children[i])
}
}
}
function transform(ast){
// 在遍历模板AST树的时候,可以针对部分节点作出一些修改
tranverseNode(ast);
console.log(dump(ast));
}
```
目前tranverseNode虽然能够正常工作,但是内部有两个职责:遍历、转换,接下来需要将这两个职责进行解耦。
步骤三:在 transform 里面维护一个上下文对象(环境:包含执行代码时用到的一些信息)
```js
// 需要将之前的转换方法全部提出来,每一种转换提取成一个单独的方法
function transformElement(node){
if(node.type === 'Element' && node.tag === 'p'){
node.tag = 'h1';
}
}
function transformText(node){
if(node.type === 'Text'){
node.content = node.content.toUpperCase();
}
}
// 该方法只负责遍历,转换的工作交给转换函数
// 转换函数是存放于上下文对象里面的
function tranverseNode(ast, context) {
// 获取到当前的节点
context.currentNode = ast;
// 从上下文对象里面拿到所有的转换方法
const transforms = context.nodeTransforms;
for (let i = 0; i < transforms.length; i++) {
transforms[i](context.currentNode);
}
// 获取当前节点的子节点
const children = context.currentNode.children;
if (children) {
for (let i = 0; i < children.length; i++) {
// 更新上下文里面的信息
context.parent = context.currentNode;
context.childIndex = i;
tranverseNode(children[i], context);
}
}
}
function transform(ast){
// 上下文对象:包含一些重要信息
const context = {
currentNode: null, // 存储当前正在转换的节点
childIndex: 0, // 子节点在父节点的 children 数组中的索引
parent: null, // 存储父节点
nodeTransforms: [transformElement, transformText], // 存储具体的转换方法
}
// 在遍历模板AST树的时候,可以针对部分节点作出一些修改
tranverseNode(ast, context);
}
```
步骤四:完善 context 上下文对象,这里主要是添加2个方法
1. 替换节点方法
2. 删除节点方法
```js
const context = {
currentNode: null, // 存储当前正在转换的节点
childIndex: 0, // 子节点在父节点的 children 数组中的索引
parent: null, // 存储父节点
// 替换节点
replaceNode(node){
context.parent.children[context.childIndex] = node;
context.currentNode = node;
},
// 删除节点
removeNode(){
if(context.parent){
context.parent.children.splice(context.childIndex, 1);
context.currentNode = null;
}
},
nodeTransforms: [transformElement, transformText], // 存储具体的转换方法
}
```
注意因为存在删除节点的操作,所以在tranverseNode方法里面执行转换函数之后,需要进行非空的判断:
```js
function tranverseNode(ast, context) {
// 获取到当前的节点
context.currentNode = ast;
// 从上下文对象里面拿到所有的转换方法
const transforms = context.nodeTransforms;
for (let i = 0; i < transforms.length; i++) {
transforms[i](context.currentNode, context);
// 由于删除节点的时候,当前节点会被置为null,所以需要判断
// 如果当前节点为null,直接返回
if(!context.currentNode) return;
}
// 获取当前节点的子节点
const children = context.currentNode.children;
if (children) {
for (let i = 0; i < children.length; i++) {
// 更新上下文里面的信息
context.parent = context.currentNode;
context.childIndex = i;
tranverseNode(children[i], context);
}
}
}
```
步骤五:解决节点处理的次数问题
目前来讲,遍历的顺序是深度遍历,从父节点到子节点。但是我们的需求是:子节点处理完之后,重新回到父节点,对父节点进行处理。
首先需要对转换函数进行改造:返回一个函数
```js
function transformText(node, context) {
// 省略第一次处理....
return ()=>{
// 对节点再次进行处理
}
}
```
tranverseNode需要拿一个数组存储转换函数返回的函数:
```js
function tranverseNode(ast, context) {
// 获取到当前的节点
context.currentNode = ast;
// 1. 增加一个数组,用于存储转换函数返回的函数
const exitFns = []
// 从上下文对象里面拿到所有的转换方法
const transforms = context.nodeTransforms;
for (let i = 0; i < transforms.length; i++) {
// 执行转换函数的时候,接收其返回值
const onExit = transforms[i](context.currentNode, context);
if(onExit){
exitFns.push(onExit)
}
// 由于删除节点的时候,当前节点会被置为null,所以需要判断
// 如果当前节点为null,直接返回
if(!context.currentNode) return;
}
// 获取当前节点的子节点
const children = context.currentNode.children;
if (children) {
for (let i = 0; i < children.length; i++) {
// 更新上下文里面的信息
context.parent = context.currentNode;
context.childIndex = i;
tranverseNode(children[i], context);
}
}
// 在节点处理完成之后,执行exitFns里面所有的函数
// 执行的顺序是从后往前依次执行
let i = exitFns.length;
while(i--){
exitFns[i]()
}
}
```
8. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
9. 最后是 **div tagEnd**,发现是一个结束标签,将其弹出,栈区重新为 `[ Root ]`,至此整个 AST 构建完毕
落地到具体的代码,大致就是这样的:
```js
// 解析器
function parse(str){
const tokens = tokenize(str);
// 创建Root根AST节点
const root = {
type: 'Root',
children: []
}
// 创建一个栈
const elementStack = [root]
while(tokens.length){
// 获取当前栈顶点作为父节点,也就是栈数组最后一项
const parent = elementStack[elementStack.length - 1];
// 从 tokens 列表中依次取出第一个 token
const t = tokens[0];
switch(t.type){
// 根据不同的type做不同的处理
case 'tag':{
// 创建一个Element类型的AST节点
const elementNode = {
type: 'Element',
tag: t.name,
children: []
}
// 将其添加为父节点的子节点
parent.children.push(elementNode)
// 将当前节点压入栈里面
elementStack.push(elementNode)
break;
}
case 'text':
// 创建文本类型的 AST 节点
const textNode = {
type: 'Text',
content: t.content
}
// 将其添加到父级节点的 children 中
parent.children.push(textNode)
break
case 'tagEnd':
// 遇到结束标签,将当前栈顶的节点弹出
elementStack.pop()
break
}
// 将处理过的 token 弹出去
tokens.shift();
}
}
```
最终,经过上面的处理,就得到了模板的抽象语法树:
```
{
"type": "Root",
"children": [
{
"type": "Element",
"tag": "div",
"children": [
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "Vue"
}
]
},
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "React"
}
]
}
]
}
]
}
```
**转换器**
目前为止,我们已经得到了模板的 AST,回顾一下 Vue 中整个模板的编译过程,大致如下:
```js
// 编译器
function compile(template){
// 1. 解析器对模板进行解析,得到模板的AST
const ast = parse(template)
// 2. 转换器:将模板AST转换为JS AST
transform(ast)
// 3. 生成器:在 JS AST 的基础上生成 JS 代码
const code = genrate(ast)
return code;
}
```
转换器的核心作用就是负责将模板 AST 转换为 JavaScript AST。
整体来讲,转换器的编写分为两大部分:
- 模板 AST 的遍历与转换
- 生成 JavaScript AST
**模板AST的遍历与转换**
步骤一:先书写一个简单的工具方法,方便查看一个模板 AST 中的节点信息。
```js
function dump(node, indent = 0) {
// 获取当前节点的类型
const type = node.type;
// 根据节点类型构建描述信息
// 对于根节点,描述为空;对于元素节点,使用标签名;对于文本节点,使用内容
const desc =
node.type === "Root"
? ""
: node.type === "Element"
? node.tag
: node.content;
// 打印当前节点信息,包括类型和描述
// 使用重复的"-"字符来表示缩进(层级)
console.log(`${"-".repeat(indent)}${type}: ${desc}`);
// 如果当前节点有子节点,递归调用dump函数打印每个子节点
if (node.children) {
node.children.forEach((n) => dump(n, indent + 2));
}
}
```
步骤二:接下来下一步就是遍历整棵模板 AST 树,并且能够做一些改动
```js
function tranverseNode(ast){
// 获取到当前的节点
const currentNode = ast;
// 将p修改为h1
if(currentNode.type === 'Element' && currentNode.tag === 'p'){
currentNode.tag = 'h1';
}
// 新增需求:将文本节点全部改为大写
if(currentNode.type === 'Text'){
currentNode.content = currentNode.content.toUpperCase();
}
// 获取当前节点的子节点
const children = currentNode.children;
if(children){
for(let i = 0;i< children.length; i++){
tranverseNode(children[i])
}
}
}
function transform(ast){
// 在遍历模板AST树的时候,可以针对部分节点作出一些修改
tranverseNode(ast);
console.log(dump(ast));
}
```
目前tranverseNode虽然能够正常工作,但是内部有两个职责:遍历、转换,接下来需要将这两个职责进行解耦。
步骤三:在 transform 里面维护一个上下文对象(环境:包含执行代码时用到的一些信息)
```js
// 需要将之前的转换方法全部提出来,每一种转换提取成一个单独的方法
function transformElement(node){
if(node.type === 'Element' && node.tag === 'p'){
node.tag = 'h1';
}
}
function transformText(node){
if(node.type === 'Text'){
node.content = node.content.toUpperCase();
}
}
// 该方法只负责遍历,转换的工作交给转换函数
// 转换函数是存放于上下文对象里面的
function tranverseNode(ast, context) {
// 获取到当前的节点
context.currentNode = ast;
// 从上下文对象里面拿到所有的转换方法
const transforms = context.nodeTransforms;
for (let i = 0; i < transforms.length; i++) {
transforms[i](context.currentNode);
}
// 获取当前节点的子节点
const children = context.currentNode.children;
if (children) {
for (let i = 0; i < children.length; i++) {
// 更新上下文里面的信息
context.parent = context.currentNode;
context.childIndex = i;
tranverseNode(children[i], context);
}
}
}
function transform(ast){
// 上下文对象:包含一些重要信息
const context = {
currentNode: null, // 存储当前正在转换的节点
childIndex: 0, // 子节点在父节点的 children 数组中的索引
parent: null, // 存储父节点
nodeTransforms: [transformElement, transformText], // 存储具体的转换方法
}
// 在遍历模板AST树的时候,可以针对部分节点作出一些修改
tranverseNode(ast, context);
}
```
步骤四:完善 context 上下文对象,这里主要是添加2个方法
1. 替换节点方法
2. 删除节点方法
```js
const context = {
currentNode: null, // 存储当前正在转换的节点
childIndex: 0, // 子节点在父节点的 children 数组中的索引
parent: null, // 存储父节点
// 替换节点
replaceNode(node){
context.parent.children[context.childIndex] = node;
context.currentNode = node;
},
// 删除节点
removeNode(){
if(context.parent){
context.parent.children.splice(context.childIndex, 1);
context.currentNode = null;
}
},
nodeTransforms: [transformElement, transformText], // 存储具体的转换方法
}
```
注意因为存在删除节点的操作,所以在tranverseNode方法里面执行转换函数之后,需要进行非空的判断:
```js
function tranverseNode(ast, context) {
// 获取到当前的节点
context.currentNode = ast;
// 从上下文对象里面拿到所有的转换方法
const transforms = context.nodeTransforms;
for (let i = 0; i < transforms.length; i++) {
transforms[i](context.currentNode, context);
// 由于删除节点的时候,当前节点会被置为null,所以需要判断
// 如果当前节点为null,直接返回
if(!context.currentNode) return;
}
// 获取当前节点的子节点
const children = context.currentNode.children;
if (children) {
for (let i = 0; i < children.length; i++) {
// 更新上下文里面的信息
context.parent = context.currentNode;
context.childIndex = i;
tranverseNode(children[i], context);
}
}
}
```
步骤五:解决节点处理的次数问题
目前来讲,遍历的顺序是深度遍历,从父节点到子节点。但是我们的需求是:子节点处理完之后,重新回到父节点,对父节点进行处理。
首先需要对转换函数进行改造:返回一个函数
```js
function transformText(node, context) {
// 省略第一次处理....
return ()=>{
// 对节点再次进行处理
}
}
```
tranverseNode需要拿一个数组存储转换函数返回的函数:
```js
function tranverseNode(ast, context) {
// 获取到当前的节点
context.currentNode = ast;
// 1. 增加一个数组,用于存储转换函数返回的函数
const exitFns = []
// 从上下文对象里面拿到所有的转换方法
const transforms = context.nodeTransforms;
for (let i = 0; i < transforms.length; i++) {
// 执行转换函数的时候,接收其返回值
const onExit = transforms[i](context.currentNode, context);
if(onExit){
exitFns.push(onExit)
}
// 由于删除节点的时候,当前节点会被置为null,所以需要判断
// 如果当前节点为null,直接返回
if(!context.currentNode) return;
}
// 获取当前节点的子节点
const children = context.currentNode.children;
if (children) {
for (let i = 0; i < children.length; i++) {
// 更新上下文里面的信息
context.parent = context.currentNode;
context.childIndex = i;
tranverseNode(children[i], context);
}
}
// 在节点处理完成之后,执行exitFns里面所有的函数
// 执行的顺序是从后往前依次执行
let i = exitFns.length;
while(i--){
exitFns[i]()
}
}
```