Vue
' ``` 那么整个状态的迁移过程如下: 1. 状态机一开始处于 **初始状态**。 2. 在 **初始状态** 下,读取字符串的第一个字符 < ,然后状态机的状态会更新为 **标签开始状态**。 3. 接下来继续读取下一个字符 p,由于 p 是字母,所以状态机的状态会更新为 **标签名称开始状态**。 4. 接下来读取的下一个字符为 >,状态机的状态会回到 **初始状态**,并且会记录在标签状态下产生的标签名称 p。 5. 读取下一个字符 V,此时状态机会进入到 **文本状态**。 6. 读取下一个字符 u,状态机仍然是 **文本状态**。 7. 读取下一个字符 e,状态机仍然是 **文本状态**。 8. 读取下一个字符 <,此时状态机会进入到 **标签开始状态**。 9. 读取下一个字符 / ,状态机会进入到 **标签结束状态**。 10. 读取下一个字符 p,状态机进入 **标签名称结束状态**。 11. 读取下一个字符 >,状态机进重新回到 **初始状态**。 具体如下图所示: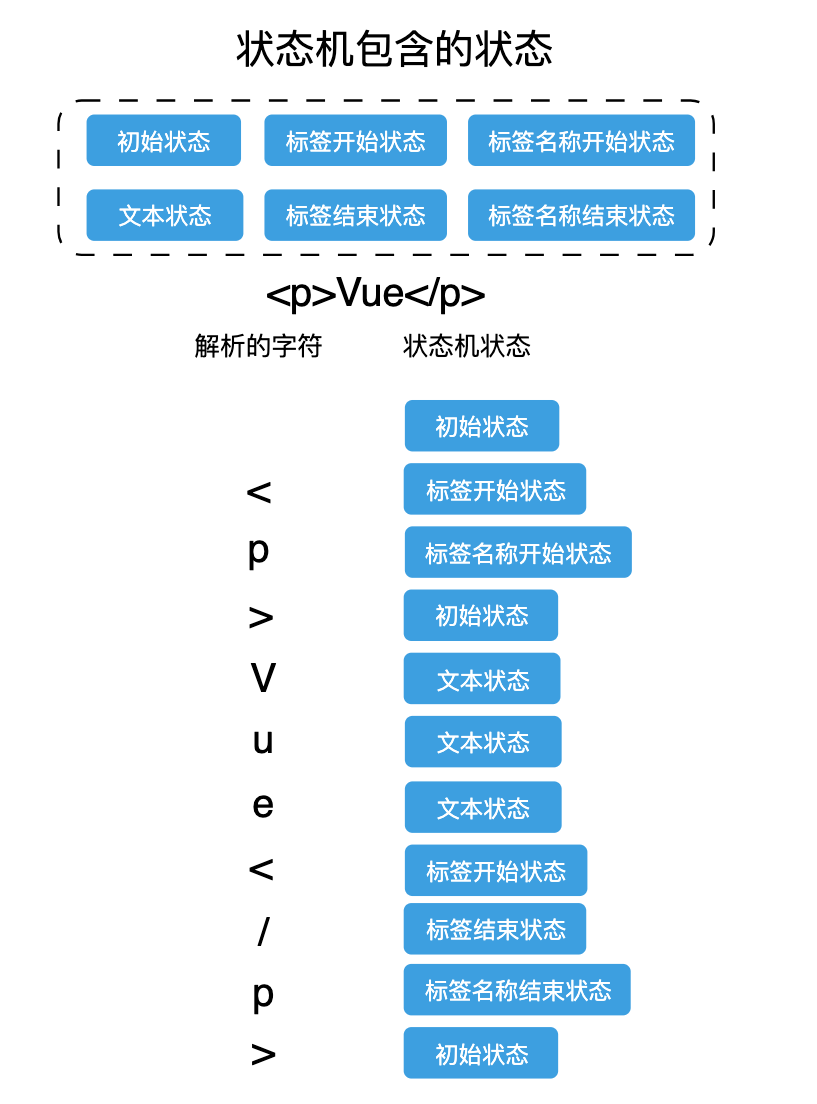 ```js
let x = 10 + 5;
```
```
token:
let(关键字) x(标识符) =(运算符) 10(数字) +(运算符) 5(数字) ;(分号)
```
对应代码:
```js
const template = '
```js
let x = 10 + 5;
```
```
token:
let(关键字) x(标识符) =(运算符) 10(数字) +(运算符) 5(数字) ;(分号)
```
对应代码:
```js
const template = 'Vue
'; // 首先定义一些状态 const State = { initial: 1, // 初始状态 tagOpen: 2, // 标签开始状态 tagName: 3, // 标签名称开始状态 text: 4, // 文本状态 tagEnd: 5, // 标签结束状态 tagEndName: 6 // 标签名称结束状态 } // 判断字符是否为字母 function isAlpha(char) { return (char >= "a" && char <= "z") || (char >= "A" && char <= "Z"); } // 将字符串解析为 token function tokenize(str){ // 初始化当前状态 let currentState = State.initial; // 用于缓存字符 const chars = []; // 存储解析出来的 token const tokens = []; while(str){ const char = str[0]; // 获取字符串里面的第一个字符 switch(currentState){ case State.initial:{ if(char === '<'){ currentState = State.tagOpen; // 消费一个字符 str = str.slice(1); } else if(isAlpha(char)){ // 判断是否为字母 currentState = State.text; chars.push(char); // 消费一个字符 str = str.slice(1); } break; } case State.tagOpen: { // 相应的状态处理 } case State.tagName: { // 相应的状态处理 } } } return tokens; } tokenize(template); ``` 最终解析出来的 token: ```js [ {type: 'tag', name: 'p'}, // 开始标签 {type: 'text', content: 'Vue'}, // 文本节点 {type: 'tagEnd', name: 'p'}, // 结束标签 ] ``` **构造模板AST** 根据 token 列表创建模板 AST 的过程,其实就是对 token 列表进行扫描的过程。从列表的第一个 token 开始,按照顺序进行扫描,直到列表中所有的 token 处理完毕。 在这个过程中,我们需**要维护一个栈**,这个栈将用于维护元素间的父子关系。每遇到一个开始标签节点,就构造一个 Element 类型的 AST 节点,并将其压入栈中。 类似的,每当遇到一个结束标签节点,我们就将当前栈顶的节点弹出。 举个例子,假设我们有如下的模板内容: ```vue 'Vue
React
 3. 接下来是 **p tag**,创建一个 Element 类型的 AST 节点,同样会压栈到 elementStack,当前的栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
3. 接下来是 **p tag**,创建一个 Element 类型的 AST 节点,同样会压栈到 elementStack,当前的栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
 4. 接下来是 **Vue text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
4. 接下来是 **Vue text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
 5. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
6. 接下来是 **p tag**,同样创建一个 Element 类型的 AST 节点,压栈后栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
5. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
6. 接下来是 **p tag**,同样创建一个 Element 类型的 AST 节点,压栈后栈为 `[ Root, div, p ]`,p 会作为 div 的子节点
 7. 接下来是 **React text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
7. 接下来是 **React text**,此时会创建一个 Text 类型的 AST 节点,作为 p 的子节点。
 8. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
9. 最后是 **div tagEnd**,发现是一个结束标签,将其弹出,栈区重新为 `[ Root ]`,至此整个 AST 构建完毕
落地到具体的代码,大致就是这样的:
```js
// 解析器
function parse(str){
const tokens = tokenize(str);
// 创建Root根AST节点
const root = {
type: 'Root',
children: []
}
// 创建一个栈
const elementStack = [root]
while(tokens.length){
// 获取当前栈顶点作为父节点,也就是栈数组最后一项
const parent = elementStack[elementStack.length - 1];
// 从 tokens 列表中依次取出第一个 token
const t = tokens[0];
switch(t.type){
// 根据不同的type做不同的处理
case 'tag':{
// 创建一个Element类型的AST节点
const elementNode = {
type: 'Element',
tag: t.name,
children: []
}
// 将其添加为父节点的子节点
parent.children.push(elementNode)
// 将当前节点压入栈里面
elementStack.push(elementNode)
break;
}
case 'text':
// 创建文本类型的 AST 节点
const textNode = {
type: 'Text',
content: t.content
}
// 将其添加到父级节点的 children 中
parent.children.push(textNode)
break
case 'tagEnd':
// 遇到结束标签,将当前栈顶的节点弹出
elementStack.pop()
break
}
// 将处理过的 token 弹出去
tokens.shift();
}
}
```
最终,经过上面的处理,就得到了模板的抽象语法树:
```
{
"type": "Root",
"children": [
{
"type": "Element",
"tag": "div",
"children": [
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "Vue"
}
]
},
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "React"
}
]
}
]
}
]
}
```
8. 接下来是 **p tagEnd**,发现是一个结束标签,所以会将 p 这个 AST 节点弹出栈,当前的栈为 `[ Root, div ]`
9. 最后是 **div tagEnd**,发现是一个结束标签,将其弹出,栈区重新为 `[ Root ]`,至此整个 AST 构建完毕
落地到具体的代码,大致就是这样的:
```js
// 解析器
function parse(str){
const tokens = tokenize(str);
// 创建Root根AST节点
const root = {
type: 'Root',
children: []
}
// 创建一个栈
const elementStack = [root]
while(tokens.length){
// 获取当前栈顶点作为父节点,也就是栈数组最后一项
const parent = elementStack[elementStack.length - 1];
// 从 tokens 列表中依次取出第一个 token
const t = tokens[0];
switch(t.type){
// 根据不同的type做不同的处理
case 'tag':{
// 创建一个Element类型的AST节点
const elementNode = {
type: 'Element',
tag: t.name,
children: []
}
// 将其添加为父节点的子节点
parent.children.push(elementNode)
// 将当前节点压入栈里面
elementStack.push(elementNode)
break;
}
case 'text':
// 创建文本类型的 AST 节点
const textNode = {
type: 'Text',
content: t.content
}
// 将其添加到父级节点的 children 中
parent.children.push(textNode)
break
case 'tagEnd':
// 遇到结束标签,将当前栈顶的节点弹出
elementStack.pop()
break
}
// 将处理过的 token 弹出去
tokens.shift();
}
}
```
最终,经过上面的处理,就得到了模板的抽象语法树:
```
{
"type": "Root",
"children": [
{
"type": "Element",
"tag": "div",
"children": [
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "Vue"
}
]
},
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "React"
}
]
}
]
}
]
}
```