From ee85a311a0b77175fd271385d88ab364ce963bb3 Mon Sep 17 00:00:00 2001
From: xiejie <745007854@qq.com>
Date: Mon, 20 Mar 2023 15:45:25 +0800
Subject: [PATCH] =?UTF-8?q?=E6=9B=B4=E6=96=B0=E9=83=A8=E5=88=86=E8=AF=BE?=
=?UTF-8?q?=E4=BB=B6?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../completeWork工作流程.md | 272 ++++++++++++
.../2-16. commit工作流程/commit 工作流程.md | 416 ++++++++++++++++++
就业篇/02. 第二章/2-17. lane模型/lane模型.md | 225 ++++++++++
就业篇/02. 第二章/2-24. Update/Update.md | 222 ++++++++++
.../性能优化策略之bailout.md | 283 ++++++++++++
.../bailout和ContextAPI.md | 151 +++++++
.../性能优化对日常开发启示.md | 167 +++++++
7 files changed, 1736 insertions(+)
create mode 100644 就业篇/02. 第二章/2-14. completeWork工作流程/completeWork工作流程.md
create mode 100644 就业篇/02. 第二章/2-16. commit工作流程/commit 工作流程.md
create mode 100644 就业篇/02. 第二章/2-17. lane模型/lane模型.md
create mode 100644 就业篇/02. 第二章/2-24. Update/Update.md
create mode 100644 就业篇/02. 第二章/2-26. 性能优化策略之bailout/性能优化策略之bailout.md
create mode 100644 就业篇/02. 第二章/2-27. bailout与ContextAPI/bailout和ContextAPI.md
create mode 100644 就业篇/02. 第二章/2-28. 性能优化对日常开发启示/性能优化对日常开发启示.md
diff --git a/就业篇/02. 第二章/2-14. completeWork工作流程/completeWork工作流程.md b/就业篇/02. 第二章/2-14. completeWork工作流程/completeWork工作流程.md
new file mode 100644
index 0000000..019361b
--- /dev/null
+++ b/就业篇/02. 第二章/2-14. completeWork工作流程/completeWork工作流程.md
@@ -0,0 +1,272 @@
+# completeWork 工作流程
+
+> 面试题:completeWork 中主要做一些什么工作?整体的流程是怎样的?
+
+前面所介绍的 beginWork,是属于“递”的阶段,该阶段的工作处理完成后,就会进入到 completeWork,这个是属于“归”的阶段。
+
+与 beginWork 类似,completeWork 也会根据 wip.tag 区分对待,流程上面主要包括两个步骤:
+
+- 创建元素或者标记元素的更新
+- flags 冒泡
+
+整体流程图如下:
+
+ +
+
+
+## mount 阶段
+
+在 mount 流程中,首先会通过 createInstance 创建 FiberNode 所对应的 DOM 元素:
+
+```js
+function createInstance(type, props, rootContainerInstance, hostContext, internalInstanceHandle){
+ //...
+ if(typeof props.children === 'string' || typeof props.chidlren === 'number'){
+ // children 为 string 或者 number 时做一些特殊处理
+ }
+
+ // 创建 DOM 元素
+ const domElement = createElement(type, props, rootContainerInstance, parentNamespace);
+
+ //...
+ return domElement;
+}
+```
+
+接下来会执行 appendAllChildren,该方法的作用是将下一层 DOM 元素插入到通过 createInstance 方法所创建的 DOM 元素中,具体的逻辑如下:
+
+- 从当前的 FiberNode 向下遍历,将遍历到的第一层 DOM 元素类型(HostComponent、HostText)通过 appendChild 方法插入到 parent 末尾
+- 对兄弟 FiberNode 执行步骤 1
+- 如果没有兄弟 FiberNode,则对父 FiberNode 的兄弟执行步骤 1
+- 当遍历流程回到最初执行步骤 1 所在层或者 parent 所在层时终止
+
+相关的代码如下:
+
+```js
+appendAllChildren = function(parent, workInProgress, ...){
+ let node = workInProgress.child;
+
+ while(node !== null){
+ // 步骤 1,向下遍历,对第一层 DOM 元素执行 appendChild
+ if(node.tag === HostComponent || node.tag === HostText){
+ // 对 HostComponent、HostText 执行 appendChild
+ appendInitialChild(parent, node.stateNode);
+ } else if(node.child !== null) {
+ // 继续向下遍历,直到找到第一层 DOM 元素类型
+ node.child.return = node;
+ node = node.child;
+ continue;
+ }
+ // 终止情况 1: 遍历到 parent 对应的 FiberNode
+ if(node === workInProgress) {
+ return;
+ }
+ // 如果没有兄弟 FiberNode,则向父 FiberNode 遍历
+ while(node.sibling === null){
+ // 终止情况 2: 回到最初执行步骤 1 所在层
+ if(node.return === null || node.return === workInProgress) {
+ return;
+ }
+ node = node.return
+ }
+ // 对兄弟 FiberNode 执行步骤 1
+ node.sibling.return = node.return;
+ node = node.sibling;
+ }
+}
+```
+
+appendAllChildren 方法实际上就是在处理下一级的 DOM 元素,而且在 appendAllChildren 里面的遍历过程会更复杂一些,会多一些判断,因为 FiberNode 最终形成的 FiberTree 的层次和最终 DOMTree 的层次可能是有区别:
+
+```jsx
+function World(){
+ return World
+}
+
+
+
+
+
+## mount 阶段
+
+在 mount 流程中,首先会通过 createInstance 创建 FiberNode 所对应的 DOM 元素:
+
+```js
+function createInstance(type, props, rootContainerInstance, hostContext, internalInstanceHandle){
+ //...
+ if(typeof props.children === 'string' || typeof props.chidlren === 'number'){
+ // children 为 string 或者 number 时做一些特殊处理
+ }
+
+ // 创建 DOM 元素
+ const domElement = createElement(type, props, rootContainerInstance, parentNamespace);
+
+ //...
+ return domElement;
+}
+```
+
+接下来会执行 appendAllChildren,该方法的作用是将下一层 DOM 元素插入到通过 createInstance 方法所创建的 DOM 元素中,具体的逻辑如下:
+
+- 从当前的 FiberNode 向下遍历,将遍历到的第一层 DOM 元素类型(HostComponent、HostText)通过 appendChild 方法插入到 parent 末尾
+- 对兄弟 FiberNode 执行步骤 1
+- 如果没有兄弟 FiberNode,则对父 FiberNode 的兄弟执行步骤 1
+- 当遍历流程回到最初执行步骤 1 所在层或者 parent 所在层时终止
+
+相关的代码如下:
+
+```js
+appendAllChildren = function(parent, workInProgress, ...){
+ let node = workInProgress.child;
+
+ while(node !== null){
+ // 步骤 1,向下遍历,对第一层 DOM 元素执行 appendChild
+ if(node.tag === HostComponent || node.tag === HostText){
+ // 对 HostComponent、HostText 执行 appendChild
+ appendInitialChild(parent, node.stateNode);
+ } else if(node.child !== null) {
+ // 继续向下遍历,直到找到第一层 DOM 元素类型
+ node.child.return = node;
+ node = node.child;
+ continue;
+ }
+ // 终止情况 1: 遍历到 parent 对应的 FiberNode
+ if(node === workInProgress) {
+ return;
+ }
+ // 如果没有兄弟 FiberNode,则向父 FiberNode 遍历
+ while(node.sibling === null){
+ // 终止情况 2: 回到最初执行步骤 1 所在层
+ if(node.return === null || node.return === workInProgress) {
+ return;
+ }
+ node = node.return
+ }
+ // 对兄弟 FiberNode 执行步骤 1
+ node.sibling.return = node.return;
+ node = node.sibling;
+ }
+}
+```
+
+appendAllChildren 方法实际上就是在处理下一级的 DOM 元素,而且在 appendAllChildren 里面的遍历过程会更复杂一些,会多一些判断,因为 FiberNode 最终形成的 FiberTree 的层次和最终 DOMTree 的层次可能是有区别:
+
+```jsx
+function World(){
+ return World
+}
+
+
+ Hello
+
+
+```
+
+在上面的代码中,如果从 FiberNode 的角度来看,Hello 和 World 是同级的,但是如果从 DOM 元素的角度来看,Hello 就和 span 是同级别的。因此从 FiberNode 中查找同级的 DOM 元素的时候,经常会涉及到跨 FiberNode 层级进行查找。
+
+
+
+接下来 completeWork 会执行 finalizeInitialChildren 方法完成属性的初始化,主要包含以下几类属性:
+
+- styles,对应的方法为 setValueForStyles 方法
+- innerHTML,对应 setInnerHTML 方法
+- 文本类型 children,对应 setTextContent 方法
+- 不会再在 DOM 中冒泡的事件,包括 cancel、close、invalid、load、scroll、toggle,对应的是 listenToNonDelegatedEvent 方法
+- 其他属性,对应 setValueForProperty 方法
+
+
+
+该方法执行完毕后,最后进行 flags 的冒泡。
+
+
+
+总结一下,completeWork 在 mount 阶段执行的工作流程如下:
+
+- 根据 wip.tag 进入不同的处理分支
+- 根据 current !== null 区分是 mount 还是 update
+- 对应 HostComponent,首先执行 createInstance 方法来创建对应的 DOM 元素
+- 执行 appendChildren 将下一级 DOM 元素挂载在上一步所创建的 DOM 元素下
+- 执行 finalizeInitialChildren 完成属性初始化
+- 执行 bubbleProperties 完成 flags 冒泡
+
+
+
+## update 阶段
+
+上面的 mount 流程,完成的是属性的初始化,那么这个 update 流程,完成的就是属性更新的标记
+
+updateHostComponent 的主要逻辑是在 diffProperties 方法里面,这个方法会包含两次遍历:
+
+- 第一次遍历,主要是标记更新前有,更新没有的属性,实际上也就是标记删除了的属性
+- 第二次遍历,主要是标记更新前后有变化的属性,实际上也就是标记更新了的属性
+
+相关代码如下:
+
+```js
+function diffProperties(domElement, tag, lastRawProps, nextRawProps, rootContainer){
+ // 保存变化属性的 key、value
+ let updatePayload = null;
+ // 更新前的属性
+ let lastProps;
+ // 更新后的属性
+ let nextProps;
+
+ //...
+ // 标记删除“更新前有,更新后没有”的属性
+ for(propKey in lastProps){
+ if(nextProps.hasOwnProperty(propKey) || !lastProps.hasOwnProperty(propKey) || lastProps[propKey] == null){
+ continue;
+ }
+
+ if(propKey === STYLE){
+ // 处理 style
+ } else {
+ //其他属性
+ (updatePayload = updatePayload || []).push(propKey, null);
+ }
+ }
+
+ // 标记更新“update流程前后发生改变”的属性
+ for(propKey in lastProps){
+ let nextProp = nextProps[propKey];
+ let lastProp = lastProps != null ? lastProps[propKey] : undefined;
+
+ if(!nextProps.hasOwnProperty(propKey) || nextProp === lastProp || nextProp == null && lastProp == null){
+ continue;
+ }
+
+ if(propKey === STYLE) {
+ // 处理 stlye
+ } else if(propKey === DANGEROUSLY_SET_INNER_HTML){
+ // 处理 innerHTML
+ } else if(propKey === CHILDREN){
+ // 处理单一文本类型的 children
+ } else if(registrationNameDependencies.hasOwnProperty(propKey)) {
+ if(nextProp != null) {
+ // 处理 onScroll 事件
+ } else {
+ // 处理其他属性
+ }
+ }
+ }
+ //...
+ return updatePayload;
+}
+```
+
+所有更新了的属性的 key 和 value 会保存在当前 FiberNode.updateQueue 里面,数据是以 key、value 作为数组相邻的两项的形式进行保存的
+
+```jsx
+export default ()=>{
+ const [num, updateNum] = useState(0);
+ return (
+ updateNum(num + 1)}
+ style={{color : `#${num}${num}${num}`}}
+ title={num + ''}
+ >
+ );
+}
+```
+
+点击 div 元素触发更新,那么这个时候 style、title 属性会发生变化,变化的数据会以下面的形式保存在 FiberNode.updateQueue 里面:
+
+```js
+["title", "1", "style", {"color": "#111"}]
+```
+
+并且,当前的 FiberNode 会标记 Update:
+
+```js
+workInProgress.flags |= Update;
+```
+
+
+
+## flags冒泡
+
+我们知道,当整个 Reconciler 完成工作后,会得到一颗完整的 wipFiberTree,这颗 wipFiberTree 是由一颗一颗 FiberNode 组成的,这些 FiberNode 中有一些标记了 flags,有一些没有标记,现在就存在一个问题,我们如何高效的找到散落在这颗 wipFiberTree 中有 flag 标记的 FiberNode,那么此时就可以通过 flags 冒泡。
+
+我们知道,completeWork 是属于归的阶段,整体流程是自下往上,就非常适合用来收集副作用,收集的相关的代码如下:
+
+```js
+let subtreeFlags = NoFlags;
+
+// 收集子 FiberNode 的子孙 FiberNode 中标记的 flags
+subtreeFlags |= child.subtreeFlags;
+// 收集子 FiberNode 中标记的 flags
+subtreeFlags |= child.flags;
+// 将收集到的所有 flags 附加到当前 FiberNode 的 subtreeFlags 上面
+completeWork.subtreeFlags |= subtreeFlags;
+```
+
+这样的收集方式,有一个好处,在渲染阶段,通过任意一级的 FiberNode.subtreeFlags 都可以快速确定该 FiberNode 以及子树是否存在副作用从而判断是否需要执行和副作用相关的操作。
+
+早期的时候,React 中实际上并没有使用 subtreeFlags 来通过 flags 冒泡收集副作用,而是使用的 effect list(链表)来收集的副作用,使用 subtreeFlags 有一个好处,就是能确定某一个 FiberNode 它的子树的副作用。
+
+
+
+## 真题解答
+
+> 题目:completeWork 中主要做一些什么工作?整体的流程是怎样的?
+>
+> 参考答案:
+>
+> completeWork 会根据 wip.tag 区分对待,流程大体上包括如下的两个步骤:
+>
+> - 创建元素(mount)或者标记元素更新(update)
+> - flags 冒泡
+>
+> completeWork 在 mount 时的流程如下:
+>
+> - 根据 wip.tag 进入不同的处理分支
+> - 根据 current !== null 区分是 mount 还是 update
+> - 对应 HostComponent,首先执行 createInstance 方法来创建对应的 DOM 元素
+> - 执行 appendChildren 将下一级 DOM 元素挂载在上一步所创建的 DOM 元素下
+> - 执行 finalizeInitialChildren 完成属性初始化
+> - 执行 bubbleProperties 完成 flags 冒泡
+>
+> completeWork 在 update 时的主要是标记属性的更新。
+>
+> updateHostComponent 的主要逻辑是在 diffProperties 方法中,该方法包括两次遍历:
+>
+> - 第一次遍历,标记删除“更新前有,更新后没有”的属性
+> - 第二次遍历,标记更新“update流程前后发生改变”的属性
+>
+> 无论是 mount 还是 update,最终都会进行 flags 的冒泡。
+>
+> flags 冒泡的目的是为了找到散落在 WorkInProgressFiberTree 各处的被标记了的 FiberNode,对“被标记的 FiberNode 所对应的 DOM 元素”执行 flags 对应的 DOM 操作。
+>
+> FiberNode.subtreeFlags 记录了该 FiberNode 的所有子孙 FiberNode 上被标记的 flags。而每个 FiberNode 经由如下操作,便可以将子孙 FiberNode 中标记的 flags 向上冒泡一层。
+>
+> Fiber 架构的早期版本并没有使用 subtreeFlags,而是使用一种被称之为 Effect list 的链表结构来保存“被标记副作用的 FiberNode”。
+>
+> 但在 React v18 版本中使用了 subtreeFlags 替换了 Effect list,原因是因为 v18 中的 Suspense 的行为恰恰需要遍历子树。
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-16. commit工作流程/commit 工作流程.md b/就业篇/02. 第二章/2-16. commit工作流程/commit 工作流程.md
new file mode 100644
index 0000000..8207a8e
--- /dev/null
+++ b/就业篇/02. 第二章/2-16. commit工作流程/commit 工作流程.md
@@ -0,0 +1,416 @@
+# commit 工作流程
+
+> 面试题:commit 阶段的工作流程是怎样的?此阶段可以分为哪些模块?每个模块在做什么?
+
+整个 React 的工作流程可以分为两大阶段:
+
+- Render 阶段
+ - Schedule
+ - Reconcile
+- Commit 阶段
+
+注意,Render 阶段的行为是在内存中运行的,这意味着可能被打断,也可以被打断,而 commit 阶段则是一旦开始就会**同步**执行直到完成。
+
+commit 阶段整体可以分为 3 个子阶段:
+
+- BeforeMutation 阶段
+- Mutation 阶段
+- Layout 阶段
+
+整体流程图如下:
+
+ +
+每个阶段,又分为三个子阶段:
+
+- commitXXXEffects
+- commitXXXEffects_begin
+- commitXXXEffects_complete
+
+
+
+所分成的这三个子阶段,是有一些共同的事情要做的
+
+
+
+**commitXXXEffects**
+
+该函数是每个子阶段的入口函数,finishedWork 会作为 firstChild 参数传入进去,相关代码如下:
+
+```js
+function commitXXXEffects(root, firstChild){
+ nextEffect = firstChild;
+ // 省略标记全局变量
+ commitXXXEffects_begin();
+ // 省略重置全局变量
+}
+```
+
+因此在该函数中,主要的工作就是将 firstChild 赋值给全局变量 nextEffect,然后执行 commitXXXEffects_begin
+
+
+
+**commitXXXEffects_begin**
+
+向下遍历 FiberNode。遍历的时候会遍历直到第一个满足如下条件之一的 FiberNode:
+
+- 当前的 FiberNode 的子 FiberNode 不包含该子阶段对应的 flags
+- 当前的 FiberNode 不存在子 FiberNode
+
+接下来会对目标 FiberNode 执行 commitXXXEffects_complete 方法,commitXXXEffects_begin 相关代码如下:
+
+```js
+function commitXXXEffects_begin(){
+ while(nextEffect !== null) {
+ let fiber = nextEffect;
+ let child = fiber.child;
+
+ // 省略该子阶段的一些特有操作
+
+ if(fiber.subtreeFlags !== NoFlags && child !== null){
+ // 继续向下遍历
+ nextEffect = child;
+ } else {
+ commitXXXEffects_complete();
+ }
+ }
+}
+```
+
+
+
+**commitXXXEffects_complete**
+
+该方法主要就是针对 flags 做具体的操作了,主要包含以下三个步骤:
+
+- 对当前 FiberNode 执行 flags 对应的操作,也就是执行 commitXXXEffectsOnFiber
+- 如果当前 FiberNode 存在兄弟 FiberNode,则对兄弟 FiberNode 执行 commitXXXEffects_begin
+- 如果不存在兄弟 FiberNode,则对父 FiberNode 执行 commitXXXEffects_complete
+
+相关代码如下:
+
+```js
+function commitXXXEffects_complete(root){
+ while(nextEffect !== null){
+ let fiber = nextEffect;
+
+ try{
+ commitXXXEffectsOnFiber(fiber, root);
+ } catch(error){
+ // 错误处理
+ }
+
+ let sibling = fiber.sibling;
+
+ if(sibling !== null){
+ // ...
+ nextEffect = sibling;
+ return
+ }
+
+ nextEffect = fiber.return;
+ }
+}
+```
+
+
+
+总结一下,每个子阶段都会以 DFS 的原则来进行遍历,最终会在 commitXXXEffectsOnFiber 中针对不同的 flags 做出不同的处理。
+
+
+
+## BeforeMutation 阶段
+
+BeforeMutation 阶段的主要工作发生在 commitBeforeMutationEffects_complete 中的 commitBeforeMutationEffectsOnFiber 方法,相关代码如下:
+
+```js
+function commitBeforeMutationEffectsOnFiber(finishedWork){
+ const current = finishedWork.alternate;
+ const flags = finishedWork.falgs;
+
+ //...
+ // Snapshot 表示 ClassComponent 存在更新,且定义了 getSnapsshotBeforeUpdate 方法
+ if(flags & Snapshot !== NoFlags) {
+ switch(finishedWork.tag){
+ case ClassComponent: {
+ if(current !== null){
+ const prevProps = current.memoizedProps;
+ const prevState = current.memoizedState;
+ const instance = finishedWork.stateNode;
+
+ // 执行 getSnapsshotBeforeUpdate
+ const snapshot = instance.getSnapsshotBeforeUpdate(
+ finishedWork.elementType === finishedWork.type ?
+ prevProps : resolveDefaultProps(finishedWork.type, prevProps),
+ prevState
+ )
+ }
+ break;
+ }
+ case HostRoot: {
+ // 清空 HostRoot 挂载的内容,方便 Mutation 阶段渲染
+ if(supportsMutation){
+ const root = finishedWork.stateNode;
+ clearCOntainer(root.containerInfo);
+ }
+ break;
+ }
+ }
+ }
+}
+```
+
+上面代码的整个过程中,主要是处理如下两种类型的 FiberNode:
+
+- ClassComponent:执行 getSnapsshotBeforeUpdate 方法
+- HostRoot:清空 HostRoot 挂载的内容,方便 Mutation 阶段进行渲染
+
+
+
+## Mutation 阶段
+
+对于 HostComponent,Mutation 阶段的主要工作就是对 DOM 元素及进行增、删、改
+
+
+
+### 删除 DOM 元素
+
+删除 DOM 元素相关代码如下:
+
+```js
+function commitMutationEffects_begin(root){
+ while(nextEffect !== null){
+ const fiber = nextEffect;
+ // 删除 DOM 元素
+ const deletions = fiber.deletions;
+
+ if(deletions !== null){
+ for(let i=0;i
+
+
+
+每个阶段,又分为三个子阶段:
+
+- commitXXXEffects
+- commitXXXEffects_begin
+- commitXXXEffects_complete
+
+
+
+所分成的这三个子阶段,是有一些共同的事情要做的
+
+
+
+**commitXXXEffects**
+
+该函数是每个子阶段的入口函数,finishedWork 会作为 firstChild 参数传入进去,相关代码如下:
+
+```js
+function commitXXXEffects(root, firstChild){
+ nextEffect = firstChild;
+ // 省略标记全局变量
+ commitXXXEffects_begin();
+ // 省略重置全局变量
+}
+```
+
+因此在该函数中,主要的工作就是将 firstChild 赋值给全局变量 nextEffect,然后执行 commitXXXEffects_begin
+
+
+
+**commitXXXEffects_begin**
+
+向下遍历 FiberNode。遍历的时候会遍历直到第一个满足如下条件之一的 FiberNode:
+
+- 当前的 FiberNode 的子 FiberNode 不包含该子阶段对应的 flags
+- 当前的 FiberNode 不存在子 FiberNode
+
+接下来会对目标 FiberNode 执行 commitXXXEffects_complete 方法,commitXXXEffects_begin 相关代码如下:
+
+```js
+function commitXXXEffects_begin(){
+ while(nextEffect !== null) {
+ let fiber = nextEffect;
+ let child = fiber.child;
+
+ // 省略该子阶段的一些特有操作
+
+ if(fiber.subtreeFlags !== NoFlags && child !== null){
+ // 继续向下遍历
+ nextEffect = child;
+ } else {
+ commitXXXEffects_complete();
+ }
+ }
+}
+```
+
+
+
+**commitXXXEffects_complete**
+
+该方法主要就是针对 flags 做具体的操作了,主要包含以下三个步骤:
+
+- 对当前 FiberNode 执行 flags 对应的操作,也就是执行 commitXXXEffectsOnFiber
+- 如果当前 FiberNode 存在兄弟 FiberNode,则对兄弟 FiberNode 执行 commitXXXEffects_begin
+- 如果不存在兄弟 FiberNode,则对父 FiberNode 执行 commitXXXEffects_complete
+
+相关代码如下:
+
+```js
+function commitXXXEffects_complete(root){
+ while(nextEffect !== null){
+ let fiber = nextEffect;
+
+ try{
+ commitXXXEffectsOnFiber(fiber, root);
+ } catch(error){
+ // 错误处理
+ }
+
+ let sibling = fiber.sibling;
+
+ if(sibling !== null){
+ // ...
+ nextEffect = sibling;
+ return
+ }
+
+ nextEffect = fiber.return;
+ }
+}
+```
+
+
+
+总结一下,每个子阶段都会以 DFS 的原则来进行遍历,最终会在 commitXXXEffectsOnFiber 中针对不同的 flags 做出不同的处理。
+
+
+
+## BeforeMutation 阶段
+
+BeforeMutation 阶段的主要工作发生在 commitBeforeMutationEffects_complete 中的 commitBeforeMutationEffectsOnFiber 方法,相关代码如下:
+
+```js
+function commitBeforeMutationEffectsOnFiber(finishedWork){
+ const current = finishedWork.alternate;
+ const flags = finishedWork.falgs;
+
+ //...
+ // Snapshot 表示 ClassComponent 存在更新,且定义了 getSnapsshotBeforeUpdate 方法
+ if(flags & Snapshot !== NoFlags) {
+ switch(finishedWork.tag){
+ case ClassComponent: {
+ if(current !== null){
+ const prevProps = current.memoizedProps;
+ const prevState = current.memoizedState;
+ const instance = finishedWork.stateNode;
+
+ // 执行 getSnapsshotBeforeUpdate
+ const snapshot = instance.getSnapsshotBeforeUpdate(
+ finishedWork.elementType === finishedWork.type ?
+ prevProps : resolveDefaultProps(finishedWork.type, prevProps),
+ prevState
+ )
+ }
+ break;
+ }
+ case HostRoot: {
+ // 清空 HostRoot 挂载的内容,方便 Mutation 阶段渲染
+ if(supportsMutation){
+ const root = finishedWork.stateNode;
+ clearCOntainer(root.containerInfo);
+ }
+ break;
+ }
+ }
+ }
+}
+```
+
+上面代码的整个过程中,主要是处理如下两种类型的 FiberNode:
+
+- ClassComponent:执行 getSnapsshotBeforeUpdate 方法
+- HostRoot:清空 HostRoot 挂载的内容,方便 Mutation 阶段进行渲染
+
+
+
+## Mutation 阶段
+
+对于 HostComponent,Mutation 阶段的主要工作就是对 DOM 元素及进行增、删、改
+
+
+
+### 删除 DOM 元素
+
+删除 DOM 元素相关代码如下:
+
+```js
+function commitMutationEffects_begin(root){
+ while(nextEffect !== null){
+ const fiber = nextEffect;
+ // 删除 DOM 元素
+ const deletions = fiber.deletions;
+
+ if(deletions !== null){
+ for(let i=0;i
+
+
+
+
+
+```
+
+当你删除最外层的 div 这个 DOM 元素时,需要考虑:
+
+- 执行 SomeClassComponent 类组件对应的 componentWillUnmount 方法
+- 执行 SomeFunctionComponent 函数组件中的 useEffect、useLayoutEffect 这些 hook 中的 destory 方法
+- divRef 的卸载操作
+
+整个删除操作是以 DFS 的顺序,遍历子树的每个 FiberNode,执行对应的操作。
+
+
+
+### 插入、移动 DOM 元素
+
+上面的删除操作是在 commitMutationEffects_begin 方法里面执行的,而插入和移动 DOM 元素则是在 commitMutationEffects_complete 方法里面的 commitMutationEffectsOnFiber 方法里面执行的,相关代码如下:
+
+```js
+function commitMutationEffectsOnFiber(finishedWork, root){
+ const flags = finishedWork.flags;
+
+ // ...
+
+ const primaryFlags = flags & (Placement | Update | Hydrating);
+
+ outer: switch(primaryFlags){
+ case Placement:{
+ // 执行 Placement 对应操作
+ commitPlacement(finishedWork);
+ // 执行完 Placement 对应操作后,移除 Placement flag
+ finishedWork.falgs &= ~Placement;
+ break;
+ }
+ case PlacementAndUpdate:{
+ // 执行 Placement 对应操作
+ commitPlacement(finishedWork);
+ // 执行完 Placement 对应操作后,移除 Placement flag
+ finishedWork.falgs &= ~Placement;
+
+ // 执行 Update 对应操作
+ const current = finishedWork.alternate;
+ commitWork(current, finishedWork);
+ break;
+ }
+
+ // ...
+ }
+
+
+}
+```
+
+可以看出, Placement flag 对应的操作方法为 commitPlacement,代码如下:
+
+```js
+function commitPlacement(finishedWork){
+ // 获取 Host 类型的祖先 FiberNode
+ const parentFiber = getHostParentFiber(finishedWork);
+
+ // 省略根据 parentFiber 获取对应 DOM 元素的逻辑
+
+ let parent;
+
+ // 目标 DOM 元素会插入至 before 左边
+ const before = getHostSibling(finishedWork);
+
+ // 省略分支逻辑
+ // 执行插入或移动操作
+ insertOrAppendPlacementNode(finishedWork, before, parent);
+}
+```
+
+整个 commitPlacement 方法的执行流程可以分为三个步骤:
+
+- 从当前 FiberNode 向上遍历,获取第一个类型为 HostComponent、HostRoot、HostPortal 三者之一的祖先 FiberNode,其对应的 DOM 元素是执行 DOM 操作的目标元素的父级 DOM 元素
+- 获取用于执行 parentNode.insertBefore(child, before) 方法的 “before 对应的 DOM 元素”
+- 执行 parentNode.insertBefore 方法(存在 before)或者 parentNode.appendChild 方法(不存在 before)
+
+对于“还没有插入的DOM元素”(对应的就是 mount 场景),insertBefore 会将目标 DOM 元素插入到 before 之前,appendChild 会将目标DOM元素作为父DOM元素的最后一个子元素插入
+
+对于“UI中已经存在的 DOM 元素”(对应 update 场景),insertBefore 会将目标 DOM 元素移动到 before 之前,appendChild 会将目标 DOM 元素移动到同级最后。
+
+因此这也是为什么在 React 中,插入和移动所对应的 flag 都是 Placement flag 的原因。(可能面试的时候会被问到)
+
+
+
+### 更新 DOM 元素
+
+更新 DOM 元素,一个最主要的工作就是更新对应的属性,执行的方法为 commitWork,相关代码如下:
+
+```js
+function commitWork(current, finishedWork){
+ switch(finishedWork.tag){
+ // 省略其他类型处理逻辑
+ case HostComponent:{
+ const instance = finishedWork.stateNode;
+ if(instance != null){
+ const newProps = finishedWork.memoizedProps;
+ const oldProps = current !== null ? current.memoizedProps : newProps;
+ const type = finishedWork.type;
+
+ const updatePayload = finishedWork.updateQueue;
+ finishedWork.updateQueue = null;
+ if(updatePayload !== null){
+ // 存在变化的属性
+ commitUpdate(instance, updatePayload, type, oldProps, newProps, finishedWork);
+ }
+ }
+ return;
+ }
+ }
+}
+```
+
+之前有讲过,变化的属性会以 key、value 相邻的形式保存在 FiberNode.updateQueue ,最终在 FiberNode.updateQueue 里面所保存的要变化的属性就会在一个名为 updateDOMProperties 方法被遍历然后进行处理,这里的处理主要是处理如下的四种数据:
+
+- style 属性变化
+- innerHTML
+- 直接文本节点变化
+- 其他元素属性
+
+相关代码如下:
+
+```js
+function updateDOMProperties(domElement, updatePayload, wasCustomComponentTag, isCustomComponentTag){
+ for(let i=0;i< updatePayload.length; i+=2){
+ const propKey = updatePayload[i];
+ const propValue = updatePayload[i+1];
+ if(propKey === STYLE){
+ // 处理 style
+ setValueForStyle(domElement, propValue);
+ } else if(propKey === DANGEROUSLY_SET_INNER_HTML){
+ // 处理 innerHTML
+ setInnerHTML(domElement, propValue);
+ } else if(propsKey === CHILDREN){
+ // 处理直接的文本节点
+ setTextContent(domElement, propValue);
+ } else {
+ // 处理其他元素
+ setValueForProperty(domElement, propKey, propValue, isCustomComponentTag);
+ }
+ }
+}
+```
+
+
+
+当 Mutation 阶段的主要工作完成后,在进入 Layout 阶段之前,会执行如下的代码来完成 FiberTree 的切换:
+
+```js
+root.current = finishedWork;
+```
+
+
+
+## Layout 阶段
+
+有关 DOM 元素的操作,在 Mutation 阶段已经结束了。
+
+在 Layout 阶段,主要的工作集中在 commitLayoutEffectsOnFiber 方法中,在该方法内部,会针对不同类型的 FiberNode 执行不同的操作:
+
+- 对于 ClassComponent:该阶段会执行 componentDidMount/Update 方法
+- 对于 FunctionComponent:该阶段会执行 useLayoutEffect 的回调函数
+
+
+
+## 真题解答
+
+> 题目:commit 阶段的工作流程是怎样的?此阶段可以分为哪些模块?每个模块在做什么?
+>
+> 参考答案:
+>
+> 整个 commit 可以分为三个子阶段
+>
+> - BeforeMutation 阶段
+> - Mutation 阶段
+> - Layout 阶段
+>
+> 每个子阶段又可以分为 commitXXXEffects、commitXXXEffects_beigin 和 commitXXXEffects_complete
+>
+> 其中 commitXXXEffects_beigin 主要是在做遍历节点的操作,commitXXXEffects_complete 主要是在处理副作用
+>
+> BeforeMutation 阶段整个过程主要处理如下两种类型的 FiberNode:
+>
+> - ClassComponent,执行 getSnapsshotBeforeUpdate 方法
+> - HostRoot,清空 HostRoot 挂载的内容,方便 Mutation 阶段渲染
+>
+> 对于 HostComponent,Mutation 阶段的工作主要是进行 DOM 元素的增、删、改。当 Mutation 阶段的主要工作完成后,在进入 Layout 阶段之前,会执行如下的代码完成 Fiber Tree 的切换。
+>
+> Layout 阶段会对遍历到的每个 FiberNode 执行 commitLayoutEffectOnFiber,根据 FiberNode 的不同,执行不同的操作,例如:
+>
+> - 对于 ClassComponent,该阶段执行 componentDidMount/Update 方法
+> - 对于 FunctionComponent,该阶段执行 useLayoutEffect callback 方法
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-17. lane模型/lane模型.md b/就业篇/02. 第二章/2-17. lane模型/lane模型.md
new file mode 100644
index 0000000..ddffa8f
--- /dev/null
+++ b/就业篇/02. 第二章/2-17. lane模型/lane模型.md
@@ -0,0 +1,225 @@
+# lane模型
+
+> 面试题:是否了解过 React 中的 lane 模型?为什么要从之前的 expirationTime 模型转换为 lane 模型?
+
+
+
+## React 和 Scheduler 优先级的介绍
+
+之前我们已经介绍过 Scheduler,React 团队是打算将 Scheduler 进行独立发布。
+
+在 React 内部,还会有一个粒度更细的优先级算法,这个就是 lane 模型。
+
+接下来我们来看一下两套优先级模型的一个转换。
+
+
+
+在 Scheduler 内部,拥有 5 种优先级:
+
+```js
+export const NoPriority = 0;
+export const ImmediatePriority = 1;
+export const UserBlockingPriority = 2;
+export const NormalPriority = 3;
+export const LowPriority = 4;
+export const IdlePriority = 5;
+```
+
+作为一个独立的包,需要考虑到通用性,Scheduler 和 React 的优先级并不共通,在 React 内部,有四种优先级,如下四种:
+
+```js
+export const DiscreteEventPriority: EventPriority = SyncLane;
+export const ContinuousEventPriority: EventPriority = InputContinuousLane;
+export const DefaultEventPriority: EventPriority = DefaultLane;
+export const IdleEventPriority: EventPriority = IdleLane;
+```
+
+由于 React 中不同的交互对应的事件回调中产生的 update 会有不同的优先级,因此优先级与事件有关,因此在 React 内部的优先级也被称之为 EventPriority,各种优先级的含义如下:
+
+- DiscreteEventPriority:对应离散事件优先级,例如 click、input、focus、blur、touchstart 等事件都是离散触发的
+- ContinuousEventPriority:对应连续事件的优先级,例如 drag、mousemove、scroll、touchmove 等事件都是连续触发的
+- DefaultEventPriority:对应默认的优先级,例如通过计时器周期性触发更新,这种情况下产生的 update 不属于交互产生 update,所以优先级是默认的优先级
+- IdleEventPriority:对应空闲情况的优先级
+
+在上面的代码中,我们还可以观察出一件事情,不同级别的 EventPriority 对应的是不同的 lane
+
+
+
+既然 React 与 Scheduler 优先级不互通,那么这里就会涉及到一个转换的问题,这里分为:
+
+- React 优先级转为 Scheduler 的优先级
+- Scheduler 的优先级转为 React 的优先级
+
+
+
+**React 优先级转为 Scheduler 的优先级**
+
+整体会经历两次转换:
+
+- 首先是将 lanes 转为 EventPriority,涉及到的方法如下:
+
+```js
+export function lanesToEventPriority(lanes: Lanes): EventPriority {
+ // getHighestPriorityLane 方法用于分离出优先级最高的 lane
+ const lane = getHighestPriorityLane(lanes);
+ if (!isHigherEventPriority(DiscreteEventPriority, lane)) {
+ return DiscreteEventPriority;
+ }
+ if (!isHigherEventPriority(ContinuousEventPriority, lane)) {
+ return ContinuousEventPriority;
+ }
+ if (includesNonIdleWork(lane)) {
+ return DefaultEventPriority;
+ }
+ return IdleEventPriority;
+}
+```
+
+- 将 EventPriority 转换为 Scheduler 的优先级,方法如下:
+
+```js
+// ...
+let schedulerPriorityLevel;
+switch (lanesToEventPriority(nextLanes)) {
+ case DiscreteEventPriority:
+ schedulerPriorityLevel = ImmediateSchedulerPriority;
+ break;
+ case ContinuousEventPriority:
+ schedulerPriorityLevel = UserBlockingSchedulerPriority;
+ break;
+ case DefaultEventPriority:
+ schedulerPriorityLevel = NormalSchedulerPriority;
+ break;
+ case IdleEventPriority:
+ schedulerPriorityLevel = IdleSchedulerPriority;
+ break;
+ default:
+ schedulerPriorityLevel = NormalSchedulerPriority;
+ break;
+}
+// ...
+```
+
+举一个例子,假设现在有一个点击事件,在 onClick 中对应有一个回调函数来触发更新,该更新属于 DiscreteEventPriority,经过上面的两套转换规则进行转换之后,最终得到的 Scheduler 对应的优先级就是 ImmediateSchedulerPriority
+
+
+
+**Scheduler 的优先级转为 React 的优先级**
+
+转换相关的代码如下:
+
+```js
+const schedulerPriority = getCurrentSchedulerPriorityLevel();
+switch (schedulerPriority) {
+ case ImmediateSchedulerPriority:
+ return DiscreteEventPriority;
+ case UserBlockingSchedulerPriority:
+ return ContinuousEventPriority;
+ case NormalSchedulerPriority:
+ case LowSchedulerPriority:
+ return DefaultEventPriority;
+ case IdleSchedulerPriority:
+ return IdleEventPriority;
+ default:
+ return DefaultEventPriority;
+}
+```
+
+
+
+这里会涉及到一个问题,在同一时间可能存在很多的更新,究竟先去更新哪一个?
+
+- 从众多的有优先级的 update 中选出一个优先级最高的
+- 表达批的概念
+
+React 在表达方式上面实际上经历了两次迭代:
+
+- 基于 expirationTime 的算法
+- 基于 lane 的算法
+
+
+
+## expirationTime 模型
+
+React 早期采用的就是 expirationTime 的算法,这一点和 Scheduler 里面的设计是一致的。
+
+在 Scheduler 中,设计了 5 种优先级,不同的优先级会对应不同的 timeout,最终会对应不同的 expirationTime,然后 task 根据 expirationTime 来进行任务的排序。
+
+早期的时候在 React 中延续了这种设计,update 的优先级与触发事件的当前时间以及优先级对应的延迟时间相关,这样的算法实际上是比较简单易懂的,每当进入 schedule 的时候,就会选出优先级最高的 update 进行一个调度。
+
+但是这种算法在表示“批”的概念上不够灵活。
+
+在基于 expirationTime 模型的算法中,有如下的表达:
+
+```js
+const isUpdateIncludedInBatch = priorityOfUpdate >= priorityOfBatch;
+```
+
+priorityOfUpdate 表示的是当前 update 的优先级,priorityOfBatch 代表的是批对应的优先级下限,也就是说,当前的 update 只要大于等于 priorityOfBatch,就会被划分为同一批:
+
+ +
+但是此时就会存在一个问题,如何将某一范围的某几个优先级划为同一批?
+
+
+
+但是此时就会存在一个问题,如何将某一范围的某几个优先级划为同一批?
+
+ +
+在上图中,我们想要将 u1、u2、u3 和 u4 划分为同一批,但是以前的 expirationTime 模型是无法做到的。
+
+究其原因,是因为 expirationTime 模型优先级算法耦合了“优先级”和“批”的概念,限制了模型的表达能力。优先级算法的本质是为 update 进行一个排序,但是 expirationTime 模型在完成排序的同时还默认的划定了“批”。
+
+
+
+## lane 模型
+
+因此,基于上述的原因,React 中引入了 lane 模型。
+
+不管新引入什么模型,比如要保证以下两个问题得到解决:
+
+- 以优先级为依据,对 update 进行一个排序
+- 表达批的概念
+
+
+
+针对第一个问题,lane模型中设置了很多的 lane,每一个lane实际上是一个二进制数,通过二进制来表达优先级,越低的位代表越高的优先级,例如:
+
+```js
+export const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
+export const InputContinuousLane: Lane = /* */ 0b0000000000000000000000000000100;
+export const DefaultLane: Lane = /* */ 0b0000000000000000000000000010000;
+export const IdleLane: Lane = /* */ 0b0100000000000000000000000000000;
+export const OffscreenLane: Lane = /* */ 0b1000000000000000000000000000000;
+```
+
+在上面的代码中,SyncLane 是最高优先级,OffscreenLane 是最低优先级。
+
+
+
+对于第二个问题,lane模型能够非常灵活的表达批的概念:
+
+```js
+// 要使用的批
+let batch = 0;
+// laneA 和 laneB。是不相邻的优先级
+const laneA = 0b0000000000000000000000001000000;
+const laneB = 0b0000000000000000000000000000001;
+// 将 laneA 纳入批中
+batch |= laneA;
+// 将 laneB 纳入批中
+batch |= laneB;
+```
+
+
+
+## 真题解答
+
+> 题目:是否了解过 React 中的 lane 模型?为什么要从之前的 expirationTime 模型转换为 lane 模型?
+>
+> 参考答案:
+>
+> 在 React 中有一套独立的粒度更细的优先级算法,这就是 lane 模型。
+>
+> 这是一个基于位运算的算法,每一个 lane 是一个 32 bit Integer,不同的优先级对应了不同的 lane,越低的位代表越高的优先级。
+>
+> 早期的 React 并没有使用 lane 模型,而是采用的的基于 expirationTime 模型的算法,但是这种算法耦合了“优先级”和“批”这两个概念,限制了模型的表达能力。优先级算法的本质是“为 update 排序”,但 expirationTime 模型在完成排序的同时还默认的划定了“批”。
+>
+> 使用 lane 模型就不存在这个问题,因为是基于位运算,所以在批的划分上会更加的灵活。
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-24. Update/Update.md b/就业篇/02. 第二章/2-24. Update/Update.md
new file mode 100644
index 0000000..e181f2d
--- /dev/null
+++ b/就业篇/02. 第二章/2-24. Update/Update.md
@@ -0,0 +1,222 @@
+# Update
+
+> 面试题:说一说 React 中的 updateQueue
+
+在 React 中,有许多触发状态更新的方法,比如:
+
+- ReactDOM.createRoot
+- this.setState
+- this.forceUpdate
+- useState dispatcher
+- useReducer dispatcher
+
+虽然这些方法执行的场景会有所不同,但是都可以接入同样的更新流程,原因是因为它们使用同一种数据结构来表示更新,这种数据结构就是 Update。
+
+
+
+## Update 数据结构
+
+在 React 中,更新实际上是存在优先级的,其心智模型有一些类似于“代码版本管理工具”。
+
+举个例子,假设现在我们在开发一个软件,当前软件处于正常的迭代中,拥有 A、B、C 三个正常需求,此时突然来了一个紧急的线上 Bug,整体流程如下:
+
+
+
+在上图中,我们想要将 u1、u2、u3 和 u4 划分为同一批,但是以前的 expirationTime 模型是无法做到的。
+
+究其原因,是因为 expirationTime 模型优先级算法耦合了“优先级”和“批”的概念,限制了模型的表达能力。优先级算法的本质是为 update 进行一个排序,但是 expirationTime 模型在完成排序的同时还默认的划定了“批”。
+
+
+
+## lane 模型
+
+因此,基于上述的原因,React 中引入了 lane 模型。
+
+不管新引入什么模型,比如要保证以下两个问题得到解决:
+
+- 以优先级为依据,对 update 进行一个排序
+- 表达批的概念
+
+
+
+针对第一个问题,lane模型中设置了很多的 lane,每一个lane实际上是一个二进制数,通过二进制来表达优先级,越低的位代表越高的优先级,例如:
+
+```js
+export const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
+export const InputContinuousLane: Lane = /* */ 0b0000000000000000000000000000100;
+export const DefaultLane: Lane = /* */ 0b0000000000000000000000000010000;
+export const IdleLane: Lane = /* */ 0b0100000000000000000000000000000;
+export const OffscreenLane: Lane = /* */ 0b1000000000000000000000000000000;
+```
+
+在上面的代码中,SyncLane 是最高优先级,OffscreenLane 是最低优先级。
+
+
+
+对于第二个问题,lane模型能够非常灵活的表达批的概念:
+
+```js
+// 要使用的批
+let batch = 0;
+// laneA 和 laneB。是不相邻的优先级
+const laneA = 0b0000000000000000000000001000000;
+const laneB = 0b0000000000000000000000000000001;
+// 将 laneA 纳入批中
+batch |= laneA;
+// 将 laneB 纳入批中
+batch |= laneB;
+```
+
+
+
+## 真题解答
+
+> 题目:是否了解过 React 中的 lane 模型?为什么要从之前的 expirationTime 模型转换为 lane 模型?
+>
+> 参考答案:
+>
+> 在 React 中有一套独立的粒度更细的优先级算法,这就是 lane 模型。
+>
+> 这是一个基于位运算的算法,每一个 lane 是一个 32 bit Integer,不同的优先级对应了不同的 lane,越低的位代表越高的优先级。
+>
+> 早期的 React 并没有使用 lane 模型,而是采用的的基于 expirationTime 模型的算法,但是这种算法耦合了“优先级”和“批”这两个概念,限制了模型的表达能力。优先级算法的本质是“为 update 排序”,但 expirationTime 模型在完成排序的同时还默认的划定了“批”。
+>
+> 使用 lane 模型就不存在这个问题,因为是基于位运算,所以在批的划分上会更加的灵活。
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-24. Update/Update.md b/就业篇/02. 第二章/2-24. Update/Update.md
new file mode 100644
index 0000000..e181f2d
--- /dev/null
+++ b/就业篇/02. 第二章/2-24. Update/Update.md
@@ -0,0 +1,222 @@
+# Update
+
+> 面试题:说一说 React 中的 updateQueue
+
+在 React 中,有许多触发状态更新的方法,比如:
+
+- ReactDOM.createRoot
+- this.setState
+- this.forceUpdate
+- useState dispatcher
+- useReducer dispatcher
+
+虽然这些方法执行的场景会有所不同,但是都可以接入同样的更新流程,原因是因为它们使用同一种数据结构来表示更新,这种数据结构就是 Update。
+
+
+
+## Update 数据结构
+
+在 React 中,更新实际上是存在优先级的,其心智模型有一些类似于“代码版本管理工具”。
+
+举个例子,假设现在我们在开发一个软件,当前软件处于正常的迭代中,拥有 A、B、C 三个正常需求,此时突然来了一个紧急的线上 Bug,整体流程如下:
+
+ +
+为了修复线上 Bug D,你需要先完成需求 A、B、C,之后才能进行 D 的修复,这样的设计实际上是不合理的。
+
+有了代码版本管理工具之后,有紧急线上 Bug 需要修复时,可以先暂存当前分支的修改,在 master 分支修复 Bug D 并紧急上线:
+
+
+
+为了修复线上 Bug D,你需要先完成需求 A、B、C,之后才能进行 D 的修复,这样的设计实际上是不合理的。
+
+有了代码版本管理工具之后,有紧急线上 Bug 需要修复时,可以先暂存当前分支的修改,在 master 分支修复 Bug D 并紧急上线:
+
+ +
+当 Bug 修复完毕后,再正常的来迭代 A、B、C 需求,之后的迭代会基于 D 这个版本:
+
+
+
+当 Bug 修复完毕后,再正常的来迭代 A、B、C 需求,之后的迭代会基于 D 这个版本:
+
+ +
+
+
+并发更新的 React 也拥有相似的能力,不同的 update 是有不同的优先级,高优先级的 update 能够中断低优先级的 update,当高优先级的 update 完成更新之后,后续的低优先级更新会在高优先级 update 更新后的 state 的基础上再来进行更新。
+
+
+
+接下来我们来看一下 Update 的一个数据结构。
+
+在前面我们说了在 React 中,有不同的触发更新的方法,不同的方法实际上对应了不同的组件:
+
+- ReactDOM.createRoot 对应 HostRoot
+- this.setState 对应 ClassComponent
+- this.forceUpdate 对应 ClassComponent
+- useState dispatcher 对应 FunctionComponent
+- useReducer dispatcher 对应 FunctionComponent
+
+不同的组件类型,所对应的 Update 的数据结构是不同的。
+
+HostRoot 和 ClassComponent 这一类组件所对应的 Update 数据结构如下:
+
+```js
+function createUpdate(eventTime, lane){
+ const update = {
+ eventTime,
+ lane,
+ // 区分触发更新的场景
+ tag: UpdateState,
+ payload: null,
+ // UI 渲染后触发的回调函数
+ callback: null,
+ next: null,
+ };
+ return update;
+}
+```
+
+在上面的 Update 数据结构中,tag 字段是用于区分触发更新的场景的,选项包括:
+
+- ReplaceState:代表在 ClassComponent 生命周期函数中直接改变 this.state
+- UpdateState:默认情况,通过 ReactDOM.createRoot 或者 this.setState 触发更新
+- CaptureUpdate:代表发生错误的情况下在 ClassComponent 或 HostRoot 中触发更新(比如通过 getDerivedStateFormError 方法)
+- ForceUpdate:代表通过 this.forceUpdate 触发更新
+
+接下来来看一下 FunctionComponent 所对应的 Update 数据结构:
+
+```js
+const update = {
+ lane,
+ action,
+ // 优化策略相关字段
+ hasEagerState: false,
+ eagerState: null,
+ next: null
+}
+```
+
+在上面的数据结构中,有 hasEagerState 和 eagerState 这两个字段,它们和后面要介绍的 React 内部的性能优化策略(eagerState 策略)相关。
+
+
+
+在 Update 数据结构中,有三个问题是需要考虑:
+
+- 更新所承载的更新内容是什么
+
+对于HostRoot以及类组件来讲,承载更新内容的字段为 payload 字段
+
+```js
+// HostRoot
+ReactDOM.createRoot(rootEle).render();
+// 对应 update
+{
+ payload : {
+ // HostRoot 对应的 jsx,也就是 对应的 jsx
+ element
+ },
+ // 省略其他字段
+}
+
+// ClassComponent 情况1
+this.setState({num : 1})
+// 对应 update
+{
+ payload : {
+ num: 1
+ },
+ // 省略其他字段
+}
+
+// ClassComponent 情况2
+this.setState({num : num => num + 1})
+// 对应 update
+{
+ payload : {
+ num: num => num + 1
+ },
+ // 省略其他字段
+}
+```
+
+对于函数组件来讲,承载更新内容的字段为 action 字段
+
+```js
+// FC 使用 useState 情况1
+updateNum(1);
+// 对应 update
+{
+ action : 1,
+ // 省略其他字段
+}
+
+// FC 使用 useState 情况2
+updateNum(num => num + 1);
+// 对应 update
+{
+ action : num => num + 1,
+ // 省略其他字段
+}
+```
+
+- 更新的紧急程度:紧急程度是由 lane 字段来表示的
+- 更新之间的顺序:通过 next 字段来指向下一个 update,从而形成一个链表。
+
+
+
+## UpdateQueue
+
+上面所介绍的 update 是计算 state 的最小单位,updateQueue 是由 update 组成的一个链表,updateQueue 的数据结构如下:
+
+```js
+const updateQueue = {
+ baseState: null,
+ firstBaseUpdate: null,
+ lastBaseUpdate: null,
+ shared: {
+ pending: null
+ }
+}
+```
+
+- baseState:参与计算的初始 state,update 基于该 state 计算新的 state,可以类比为心智模型中的 master 分支。
+- firstBaseUpdate 与 lastBaseUpdate:表示更新前该 FiberNode 中已保存的 update,以链表的形式串联起来。链表头部为 firstBaseUpdate,链表尾部为 lastBaseUpdate。
+- shared.pending:触发更新后,产生的 update 会保存在 shared.pending 中形成**单向环状链表**。计算 state 时,该环状链表会被拆分并拼接在 lastBaseUpdate 后面。
+
+
+
+举例说明,例如当前有一个 FiberNode 刚经历完 commit 阶段的渲染,该 FiberNode 上面有两个“由于优先级低,导致在上一轮 render 阶段并没有被处理的 update”,假设这两个 update 分别名为 u0 和 u1
+
+```js
+fiber.updateQueue.firstBaseUpdate = u0;
+fiber.updateQueue.lastBaseUpdate = u1;
+u0.next = u1;
+```
+
+那么假设在当前的 FiberNode 上面我们又触发了两次更新,分别产生了两个 update(u2 和 u3),新产生的 update 就会形成一个环状链表,shared.pending 就会指向这个环状链表,如下图所示:
+
+
+
+
+
+并发更新的 React 也拥有相似的能力,不同的 update 是有不同的优先级,高优先级的 update 能够中断低优先级的 update,当高优先级的 update 完成更新之后,后续的低优先级更新会在高优先级 update 更新后的 state 的基础上再来进行更新。
+
+
+
+接下来我们来看一下 Update 的一个数据结构。
+
+在前面我们说了在 React 中,有不同的触发更新的方法,不同的方法实际上对应了不同的组件:
+
+- ReactDOM.createRoot 对应 HostRoot
+- this.setState 对应 ClassComponent
+- this.forceUpdate 对应 ClassComponent
+- useState dispatcher 对应 FunctionComponent
+- useReducer dispatcher 对应 FunctionComponent
+
+不同的组件类型,所对应的 Update 的数据结构是不同的。
+
+HostRoot 和 ClassComponent 这一类组件所对应的 Update 数据结构如下:
+
+```js
+function createUpdate(eventTime, lane){
+ const update = {
+ eventTime,
+ lane,
+ // 区分触发更新的场景
+ tag: UpdateState,
+ payload: null,
+ // UI 渲染后触发的回调函数
+ callback: null,
+ next: null,
+ };
+ return update;
+}
+```
+
+在上面的 Update 数据结构中,tag 字段是用于区分触发更新的场景的,选项包括:
+
+- ReplaceState:代表在 ClassComponent 生命周期函数中直接改变 this.state
+- UpdateState:默认情况,通过 ReactDOM.createRoot 或者 this.setState 触发更新
+- CaptureUpdate:代表发生错误的情况下在 ClassComponent 或 HostRoot 中触发更新(比如通过 getDerivedStateFormError 方法)
+- ForceUpdate:代表通过 this.forceUpdate 触发更新
+
+接下来来看一下 FunctionComponent 所对应的 Update 数据结构:
+
+```js
+const update = {
+ lane,
+ action,
+ // 优化策略相关字段
+ hasEagerState: false,
+ eagerState: null,
+ next: null
+}
+```
+
+在上面的数据结构中,有 hasEagerState 和 eagerState 这两个字段,它们和后面要介绍的 React 内部的性能优化策略(eagerState 策略)相关。
+
+
+
+在 Update 数据结构中,有三个问题是需要考虑:
+
+- 更新所承载的更新内容是什么
+
+对于HostRoot以及类组件来讲,承载更新内容的字段为 payload 字段
+
+```js
+// HostRoot
+ReactDOM.createRoot(rootEle).render();
+// 对应 update
+{
+ payload : {
+ // HostRoot 对应的 jsx,也就是 对应的 jsx
+ element
+ },
+ // 省略其他字段
+}
+
+// ClassComponent 情况1
+this.setState({num : 1})
+// 对应 update
+{
+ payload : {
+ num: 1
+ },
+ // 省略其他字段
+}
+
+// ClassComponent 情况2
+this.setState({num : num => num + 1})
+// 对应 update
+{
+ payload : {
+ num: num => num + 1
+ },
+ // 省略其他字段
+}
+```
+
+对于函数组件来讲,承载更新内容的字段为 action 字段
+
+```js
+// FC 使用 useState 情况1
+updateNum(1);
+// 对应 update
+{
+ action : 1,
+ // 省略其他字段
+}
+
+// FC 使用 useState 情况2
+updateNum(num => num + 1);
+// 对应 update
+{
+ action : num => num + 1,
+ // 省略其他字段
+}
+```
+
+- 更新的紧急程度:紧急程度是由 lane 字段来表示的
+- 更新之间的顺序:通过 next 字段来指向下一个 update,从而形成一个链表。
+
+
+
+## UpdateQueue
+
+上面所介绍的 update 是计算 state 的最小单位,updateQueue 是由 update 组成的一个链表,updateQueue 的数据结构如下:
+
+```js
+const updateQueue = {
+ baseState: null,
+ firstBaseUpdate: null,
+ lastBaseUpdate: null,
+ shared: {
+ pending: null
+ }
+}
+```
+
+- baseState:参与计算的初始 state,update 基于该 state 计算新的 state,可以类比为心智模型中的 master 分支。
+- firstBaseUpdate 与 lastBaseUpdate:表示更新前该 FiberNode 中已保存的 update,以链表的形式串联起来。链表头部为 firstBaseUpdate,链表尾部为 lastBaseUpdate。
+- shared.pending:触发更新后,产生的 update 会保存在 shared.pending 中形成**单向环状链表**。计算 state 时,该环状链表会被拆分并拼接在 lastBaseUpdate 后面。
+
+
+
+举例说明,例如当前有一个 FiberNode 刚经历完 commit 阶段的渲染,该 FiberNode 上面有两个“由于优先级低,导致在上一轮 render 阶段并没有被处理的 update”,假设这两个 update 分别名为 u0 和 u1
+
+```js
+fiber.updateQueue.firstBaseUpdate = u0;
+fiber.updateQueue.lastBaseUpdate = u1;
+u0.next = u1;
+```
+
+那么假设在当前的 FiberNode 上面我们又触发了两次更新,分别产生了两个 update(u2 和 u3),新产生的 update 就会形成一个环状链表,shared.pending 就会指向这个环状链表,如下图所示:
+
+ +
+之后进入新的一轮 render,在该 FiberNode 的 beginWork 中,shared.pending 所指向的环状链表就会被拆分,拆分之后接入到 baseUpdate 链表后面:
+
+
+
+之后进入新的一轮 render,在该 FiberNode 的 beginWork 中,shared.pending 所指向的环状链表就会被拆分,拆分之后接入到 baseUpdate 链表后面:
+
+ +
+接下来就会遍历 updateQueue.baseUpdate,基于 updateQueue.baseState 来计算每个符合优先级条件的 update(这个过程有点类似于 Array.prototype.reduce),最终计算出最新的 state,该 state 被称之为 memoizedState。
+
+
+
+因此我们总结一下,整个 state 的计算流程可以分为两步:
+
+- 将 shared.pending 所指向的环状链表进行拆分并且和 baseUpdate 进行拼接,形成新的链表
+- 遍历连接后的链表,根据 wipRootRenderLanes 来选定优先级,基于符合优先级条件的 update 来计算 state
+
+
+
+## 真题解答
+
+> 题目:面试题:说一说 React 中的 updateQueue
+>
+> 参考答案:
+>
+> update 是计算 state 的最小单位,一条 updateQueue 代表由 update 所组成的链表,其中几个重要的属性列举如下:
+>
+> - baseState:参与计算的初始 state,update 基于该 state 计算新的 state,可以类比为心智模型中的 master 分支。
+> - firstBaseUpdate 与 lastBaseUpdate:表示更新前该 FiberNode 中已保存的 update,以链表的形式串联起来。链表头部为 firstBaseUpdate,链表尾部为 lastBaseUpdate。
+> - shared.pending:触发更新后,产生的 update 会保存在 shared.pending 中形成单向环状链表。计算 state 时,该环状链表会被拆分并拼接在 lastBaseUpdate 后面。
+>
+> 整个 state 的计算流程可以分为两步:
+>
+> - 将 shared.pending 所指向的环状链表进行拆分并且和 baseUpdate 进行拼接,形成新的链表
+> - 遍历连接后的链表,根据 wipRootRenderLanes 来选定优先级,基于符合优先级条件的 update 来计算 state
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-26. 性能优化策略之bailout/性能优化策略之bailout.md b/就业篇/02. 第二章/2-26. 性能优化策略之bailout/性能优化策略之bailout.md
new file mode 100644
index 0000000..a52de81
--- /dev/null
+++ b/就业篇/02. 第二章/2-26. 性能优化策略之bailout/性能优化策略之bailout.md
@@ -0,0 +1,283 @@
+# 性能优化策略之bailout
+
+> 面试题:谈一谈 React 中的 bailout 策略
+
+前面我们学习 beginWork 的时候,我们知道 beginWork 的作用主要是生成 wipFiberNode 的子 FiberNode,要达到这个目录存在两种方式:
+
+- 通过 reconcile 流程生成子 FiberNode
+- 通过命中 bailout 策略来复用子 FiberNode
+
+在前面我们讲过,所有的变化都是由“自变量”的改变造成的,在 React 中自变量:
+
+- state
+- props
+- context
+
+因此是否命中 bailout 主要也是围绕这三个变量展开的,整体的工作流程如下:
+
+
+
+接下来就会遍历 updateQueue.baseUpdate,基于 updateQueue.baseState 来计算每个符合优先级条件的 update(这个过程有点类似于 Array.prototype.reduce),最终计算出最新的 state,该 state 被称之为 memoizedState。
+
+
+
+因此我们总结一下,整个 state 的计算流程可以分为两步:
+
+- 将 shared.pending 所指向的环状链表进行拆分并且和 baseUpdate 进行拼接,形成新的链表
+- 遍历连接后的链表,根据 wipRootRenderLanes 来选定优先级,基于符合优先级条件的 update 来计算 state
+
+
+
+## 真题解答
+
+> 题目:面试题:说一说 React 中的 updateQueue
+>
+> 参考答案:
+>
+> update 是计算 state 的最小单位,一条 updateQueue 代表由 update 所组成的链表,其中几个重要的属性列举如下:
+>
+> - baseState:参与计算的初始 state,update 基于该 state 计算新的 state,可以类比为心智模型中的 master 分支。
+> - firstBaseUpdate 与 lastBaseUpdate:表示更新前该 FiberNode 中已保存的 update,以链表的形式串联起来。链表头部为 firstBaseUpdate,链表尾部为 lastBaseUpdate。
+> - shared.pending:触发更新后,产生的 update 会保存在 shared.pending 中形成单向环状链表。计算 state 时,该环状链表会被拆分并拼接在 lastBaseUpdate 后面。
+>
+> 整个 state 的计算流程可以分为两步:
+>
+> - 将 shared.pending 所指向的环状链表进行拆分并且和 baseUpdate 进行拼接,形成新的链表
+> - 遍历连接后的链表,根据 wipRootRenderLanes 来选定优先级,基于符合优先级条件的 update 来计算 state
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-26. 性能优化策略之bailout/性能优化策略之bailout.md b/就业篇/02. 第二章/2-26. 性能优化策略之bailout/性能优化策略之bailout.md
new file mode 100644
index 0000000..a52de81
--- /dev/null
+++ b/就业篇/02. 第二章/2-26. 性能优化策略之bailout/性能优化策略之bailout.md
@@ -0,0 +1,283 @@
+# 性能优化策略之bailout
+
+> 面试题:谈一谈 React 中的 bailout 策略
+
+前面我们学习 beginWork 的时候,我们知道 beginWork 的作用主要是生成 wipFiberNode 的子 FiberNode,要达到这个目录存在两种方式:
+
+- 通过 reconcile 流程生成子 FiberNode
+- 通过命中 bailout 策略来复用子 FiberNode
+
+在前面我们讲过,所有的变化都是由“自变量”的改变造成的,在 React 中自变量:
+
+- state
+- props
+- context
+
+因此是否命中 bailout 主要也是围绕这三个变量展开的,整体的工作流程如下:
+
+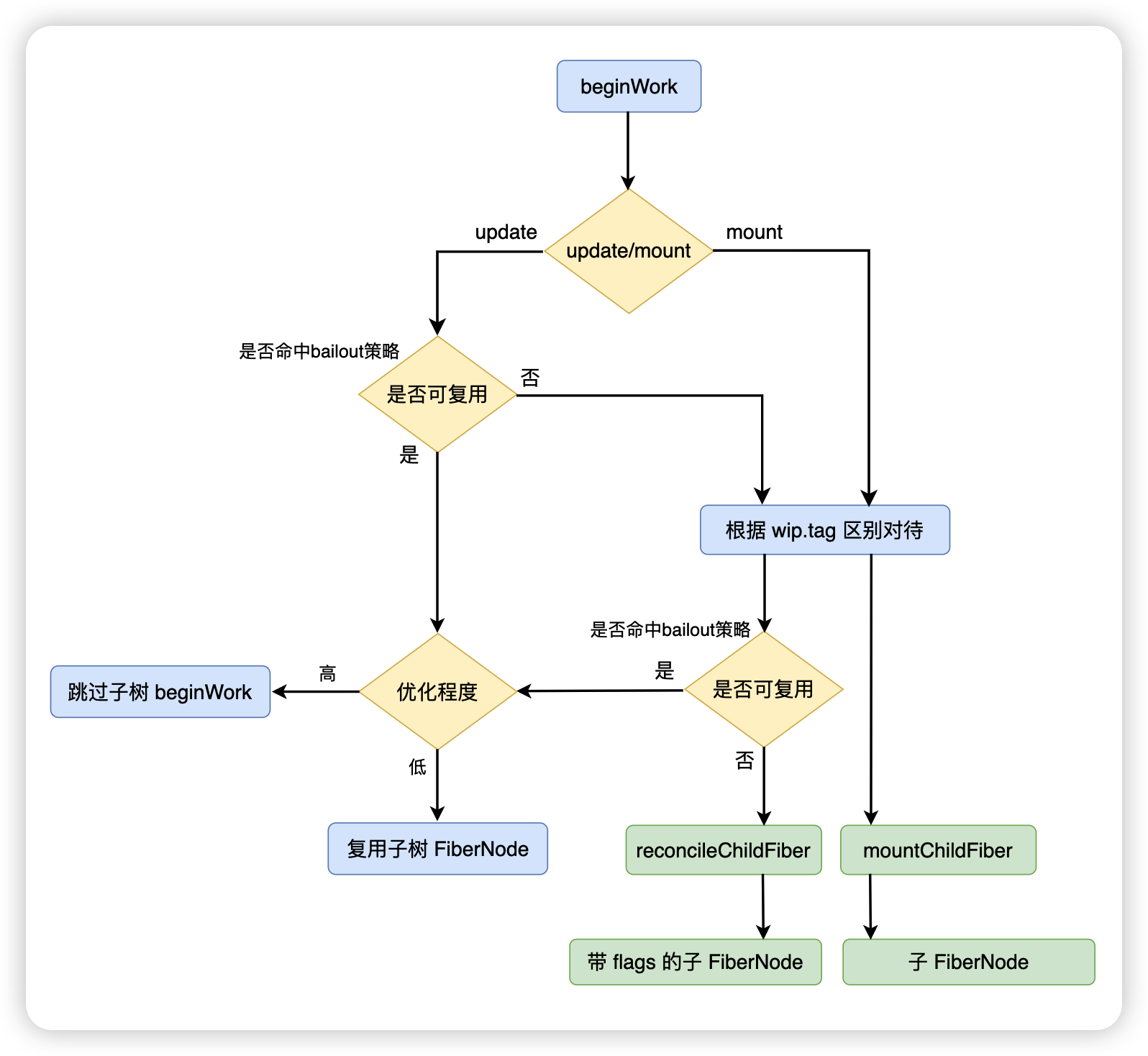 +
+从上图可以看出,bailout 是否命中发生在 update 阶段,在进入 beginWork 后,会有两次是否命中 bailout 策略的相关判断
+
+
+
+## 第一次判断
+
+第一次判断发生在确定了是 update 后,立马就会进行是否能够复用的判断:
+
+- oldProps 全等于 newProps
+- Legacy Context 没有变化
+- FiberNode.type 没有变化
+- 当前 FiberNode 没有更新发生
+
+
+
+**oldProps 全等于 newProps**
+
+注意这里是做的一个全等比较。组件在 render 之后,拿到的是一个 React 元素,会针对 React 元素的 props 进行一个全等比较。但是由于每一次组件 render 的时候,会生成一个全新的对象引用,因此 oldProps 和 newProps 并不会全等,此时是没有办法命中 bailout。
+
+只有当父 FiberNode 命中 bailout 策略时,复用子 FiberNode,在子 FiberNode 的 beginWork 中,oldProps 才有可能和 newProps 全等。
+
+> 备注:视频中这里讲解有误,不是针对 props 属性每一项进行比较,而是针对 props 对象进行全等比较。上面的笔记内容已修改。
+
+
+
+**Legacy Context 没有变化**
+
+Legacy Context指的是旧的 ContextAPI,ContextAPI重构过一次,之所以重构,就是和 bailout策略相关。
+
+
+
+**FiberNode.type 没有变化**
+
+这里所指的 FiberNode.type 没有变化,指的是不能有例如从 div 变为 p 这种变化。
+
+```jsx
+function App(){
+ const Child = () =>
+
+从上图可以看出,bailout 是否命中发生在 update 阶段,在进入 beginWork 后,会有两次是否命中 bailout 策略的相关判断
+
+
+
+## 第一次判断
+
+第一次判断发生在确定了是 update 后,立马就会进行是否能够复用的判断:
+
+- oldProps 全等于 newProps
+- Legacy Context 没有变化
+- FiberNode.type 没有变化
+- 当前 FiberNode 没有更新发生
+
+
+
+**oldProps 全等于 newProps**
+
+注意这里是做的一个全等比较。组件在 render 之后,拿到的是一个 React 元素,会针对 React 元素的 props 进行一个全等比较。但是由于每一次组件 render 的时候,会生成一个全新的对象引用,因此 oldProps 和 newProps 并不会全等,此时是没有办法命中 bailout。
+
+只有当父 FiberNode 命中 bailout 策略时,复用子 FiberNode,在子 FiberNode 的 beginWork 中,oldProps 才有可能和 newProps 全等。
+
+> 备注:视频中这里讲解有误,不是针对 props 属性每一项进行比较,而是针对 props 对象进行全等比较。上面的笔记内容已修改。
+
+
+
+**Legacy Context 没有变化**
+
+Legacy Context指的是旧的 ContextAPI,ContextAPI重构过一次,之所以重构,就是和 bailout策略相关。
+
+
+
+**FiberNode.type 没有变化**
+
+这里所指的 FiberNode.type 没有变化,指的是不能有例如从 div 变为 p 这种变化。
+
+```jsx
+function App(){
+ const Child = () => child
+ return
+}
+```
+
+在上面的代码中,我们在 App 组件中定义了 Child 组件,那么 App 每次 render 之后都会创建新的 Child 的引用,因此对于 Child 来讲,FiberNode.type 始终是变化的,无法命中 bailout 策略。
+
+因此不要在组件内部再定义组件,以免无法命中优化策略。
+
+
+
+**当前 FiberNode 没有更新发生**
+
+当前 FiberNode 没有发生更新,则意味着 state 没有发生变化。
+
+例如在源码中经常会存在是否有更新的检查:
+
+```js
+function checkScheduledUpdateOrContext(current, renderLanes) {
+ // 在执行 bailout 之前,我们必须检查是否有待处理的更新或 context。
+ const updateLanes = current.lanes;
+ if (includesSomeLane(updateLanes, renderLanes)) {
+ // 存在更新
+ return true;
+ }
+
+ //...
+
+ // 不存在更新
+ return false;
+}
+```
+
+
+
+**当以上条件都满足的时候**,会命中 bailout 策略,命中该策略后,会执行 bailoutOnAlreadyFinishedWork 方法,在该方法中,会进一步的判断优化程序,根据优化程度来决定是整颗子树都命中 bailout 还是复用子树的 FiberNode
+
+```js
+function bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes) {
+
+ // ...
+
+ if (!includesSomeLane(renderLanes, workInProgress.childLanes)) {
+ // ...
+ // 整颗子树都命中 bailout 策略
+ return null;
+ }
+
+ // 该 FiberNode 没有命中 bailout,但它的子树命中了。克隆子 FiberNode 并继续
+ cloneChildFibers(current, workInProgress);
+ return workInProgress.child;
+}
+```
+
+通过 wipFiberNode.childLanes 就可以快速的排查当前的 FiberNode 的整颗子树是否存在更新,如果不存在,直接跳过整颗子树的 beginWork。
+
+这其实也解释了为什么每次 React 更新都会生成一颗完整的 FiberTree 但是性能上并不差的原因。
+
+
+
+## 第二次判断
+
+如果第一次没有命中 bailout 策略,则会根据 tag 的不同进入不同的处理逻辑,之后还会再进行第二次的判断。
+
+第二次判断的时候会有两种命中的可能:
+
+- 开发者使用了性能优化 API
+- 虽然有更新,但是 state 没有变化
+
+
+
+**开发者使用了性能优化 API**
+
+在第一次判断的时候,默认是对 props 进行全等比较,要满足这个条件实际上是比较困难的,性能优化 API 的工作原理主要就是改写这个判断条件。
+
+比如 React.memo,通过该 API 创建的 FC 对应的 FiberNode.tag 为 MemoComponent,在 beginWork 中对应的处理逻辑如下:
+
+```js
+const hasScheduledUpdateOrContext = checkScheduledUpdateOrContext(
+ current,
+ renderLanes,
+);
+if (!hasScheduledUpdateOrContext) {
+ const prevProps = currentChild.memoizedProps;
+ // 比较函数,默认进行浅比较
+ let compare = Component.compare;
+ compare = compare !== null ? compare : shallowEqual;
+ if (compare(prevProps, nextProps) && current.ref === workInProgress.ref) {
+ // 如果 props 经比较未变化,且 ref 不变,则命中 bailout 策略
+ return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
+ }
+}
+```
+
+因此是否命中 bailout 策略的条件就变成了如下三个:
+
+- 不存在更新
+- 经过比较(浅比较)后 props 没有变化
+- ref 没有发生改变
+
+如果同时满足上面这三个条件,就会命中 bailout 策略,执行 bailoutOnAlreadyFinishedWork 方法。相较于第一次判断,第二次判断 props 采用的是浅比较进行判断,因此能够更加容易命中 bailout
+
+
+
+例如再来看一个例子,比如 ClassComponent 的优化手段经常会涉及到 PureComponent 或者 shouldComponentUpdate,这两个 API 实际上背后也是在优化命中bailout 策略的方式
+
+在 ClassComponnet 的 beginWork 方法中,有如下的代码:
+
+```js
+if(!shouldUpdate && !didCaptureError){
+ // 省略代码
+ return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
+}
+```
+
+shouldUpdate 变量受 checkShouldComponentUpdate 方法的影响:
+
+```js
+function checkShouldComponentUpdate(
+ workInProgress,
+ ctor,
+ oldProps,
+ newProps,
+ oldState,
+ newState,
+ nextContext,
+) {
+ // ClassComponent 实例
+ const instance = workInProgress.stateNode;
+ if (typeof instance.shouldComponentUpdate === 'function') {
+ let shouldUpdate = instance.shouldComponentUpdate(
+ newProps,
+ newState,
+ nextContext,
+ );
+
+ // shouldComponentUpdate 执行后的返回值作为 shouldUpdate
+ return shouldUpdate;
+ }
+
+ // 如果是 PureComponent
+ if (ctor.prototype && ctor.prototype.isPureReactComponent) {
+ // 进行浅比较
+ return (
+ !shallowEqual(oldProps, newProps) || !shallowEqual(oldState, newState)
+ );
+ }
+
+ return true;
+}
+```
+
+通过上面的代码中我们可以看出,PureComponent 通过浅比较来决定shouldUpdate的值,而shouldUpdate的值又决定了是否能够命中 bailout 策略。
+
+
+
+**虽然有更新,但是 state 没有变化**
+
+在第一次进行判断的时候,其中有一个条件是当前的 FiberNode 没有更新发生,没有更新就意味着 state 没有改变。但是还有一种情况,那就是有更新,但是更新前后计算出来的 state 仍然没有变化,此时就也会命中 bailout 策略。
+
+例如在 FC 的 beginWork 中,有如下一段逻辑:
+
+```js
+function updateFunctionComponent(
+ current,
+ workInProgress,
+ Component,
+ nextProps: any,
+ renderLanes,
+) {
+ //...
+
+ if (current !== null && !didReceiveUpdate) {
+ // 命中 bailout 策略
+ bailoutHooks(current, workInProgress, renderLanes);
+ return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
+ }
+
+ // ...
+
+ // 进入 reconcile 流程
+ reconcileChildren(current, workInProgress, nextChildren, renderLanes);
+ return workInProgress.child;
+}
+```
+
+在上面的代码中,是否能够命中 bailout 策略取决于 didReceiveUpdate,接下来我们来看一下这个值是如何确定的:
+
+```js
+// updateReducer 内部在计算新的状态时
+if (!is(newState, hook.memoizedState)) {
+ markWorkInProgressReceivedUpdate();
+}
+
+function markWorkInProgressReceivedUpdate() {
+ didReceiveUpdate = true;
+}
+```
+
+
+
+## 真题解答
+
+> 题目:谈一谈 React 中的 bailout 策略
+>
+> 参考答案:
+>
+> 在 beginWork 中,会根据 wip FiberNode 生成对应的子 FiberNode,此时会有两次“是否命中 bailout策略”的相关判断。
+>
+> - 第一次判断
+>
+> - oldProps 全等于 newProps
+> - Legacy Context 没有变化
+> - FiberNode.type 没有变化
+> - 当前 FiberNode 没有更新发生
+>
+> **当以上条件都满足时**会命中 bailout 策略,之后会执行 bailoutOnAlreadyFinishedWork 方法,该方法会进一步判断能够优化到何种程度。
+>
+> 通过 wip.childLanes 可以快速排查“当前 FiberNode 的整颗子树中是否存在更新”,如果不存在,则可以跳过整个子树的 beginWork。这其实也是为什么 React 每次更新都要生成一棵完整的 Fiebr Tree 但是性能并不差的原因。
+>
+> - 第二次判断
+>
+> - 开发者使用了性能优化 API,此时要求当前的 FiberNode 要同时满足:
+> - 不存在更新
+> - 经过比较(默认浅比较)后 props 未变化
+> - ref 不变
+> - 虽然有更新,但是 state 没有变化
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-27. bailout与ContextAPI/bailout和ContextAPI.md b/就业篇/02. 第二章/2-27. bailout与ContextAPI/bailout和ContextAPI.md
new file mode 100644
index 0000000..13d9a80
--- /dev/null
+++ b/就业篇/02. 第二章/2-27. bailout与ContextAPI/bailout和ContextAPI.md
@@ -0,0 +1,151 @@
+# bailout和ContextAPI
+
+>面试题:为什么要重构 ContextAPI,旧版的 ContextAPI 有什么问题?
+
+ContextAPI 经历过一次重构,重构的原因和 bailout 策略相关。
+
+在旧版的 ContextAPI 中,数据是保存在栈里面的。
+
+在 beginWork 中,context 会不断的入栈(context栈),这意味着 context consumer 可以通过这个 context 栈来找到对应的 context 数据。在 completeWork 中,context 会不断的出栈。
+
+这种入栈出栈的模式,刚好对应了 reconcile 的流程以及一般的 bailout 策略。
+
+那么旧版的 ContextAPI 存在什么缺陷呢?
+
+但是针对“跳过整颗子树的 beginWork”这种程度的 bailout 策略,被跳过的子树就不会再经历 context 入栈出栈的过程,因此如果使用旧的 ContextAPI ,即使此时 context 里面的数据发生了变化,但是因为子树命中了 bailout 策略被整颗跳过了,所以子树中的 context consumer 就不会响应更新。
+
+例如,有如下的代码:
+
+```jsx
+import React, { useState,useContext } from "react";
+
+// 创建了一个 context 上下文
+const MyContext = React.createContext(0);
+
+const { Provider } = MyContext;
+
+function NumProvider({children}) {
+ // 在 NumProvider 中维护了一个数据
+ const [num, add] = useState(0);
+
+ return (
+ // 将 num 数据放入到了上下文中
+
+
+ {children}
+
+ );
+}
+
+class Middle extends React.Component{
+ shouldComponentUpdate(){
+ // 直接返回 false,意味着会命中 bailout 策略
+ return false;
+ }
+ render(){
+ return ;
+ }
+}
+
+function Child(){
+ // 从 context 上下文中获取数据,然后渲染
+ const num = useContext(MyContext);
+ // 也就是说,最终 Child 组件所渲染的数据不是自身组件,而是来自于上下文
+ // 其中它的父组件会命中 bailout 策略
+ return {num}
+}
+
+// 父组件
+function App() {
+ return (
+
+
+
+ );
+}
+
+export default App;
+```
+
+在上面的示例中,App 是挂载的组件,NumProvider 是 context Provider(上下文的提供者),Child 是 context Consumer(上下文的消费者)。在 App 和 Child 之间有一个 Middle,我们在 Middle 组件直接使用了性能优化 API,设置 shouldComponentUpdate 为 false,使其直接命中 bailout 策略。
+
+当点击 button 之后,num 会增加,但是如果是在旧版的 ContextAPI 中,这段代码是会存在缺陷的,在旧版 ContextAPI 中,子树的 beginWork 都会被跳过,这意味着 Child 组件的 beginWork 也会被跳过,表现出来的现象就是点击 button 后 num 不变。
+
+
+
+那么新版的 ContextAPI 是如何修复的呢?
+
+当 beginWork 进行到 context privider 的时候,会有如下的处理逻辑:
+
+```js
+if(objectIs(oldValue, newValue)){
+ // context value 未发生变化
+ if(oldProps.children === newProps.children && !hasContextChanged()) {
+ // 命中 bailout 策略
+ return bailoutOnAlreadyFinnishedWork(current, workInProgress, renderLanes);
+ }
+} else {
+ // context value 变化,向下寻找 Consumer,标记更新
+ propageteContextChange(workInProgress, context, renderLanes);
+}
+```
+
+在上面的代码中,首先会判断 context value 是否有变化,当 context value 发生变化时,beginWork 会从 Provider 立刻向下开启一次深度优先遍历,目的就是为了寻找 context consumer,如果一旦找到 context consumer,就对为对应的 FiberNode.lanes 上面附加一个 renderLanes,对应的相关逻辑如下:
+
+```js
+// Context Consumer lanes 附加上 renderLanes
+fiber.lanes = mergeLanes(fiber.lanes, renderLanes);
+const alternate = fiber.alternate;
+
+if(alternate !== null){
+ alternate.lanes = mergeLanes(alternate.lanes, renderLanes);
+}
+// 从 Context Consumer 向上遍历
+scheduleWorkOnParentPath(fiber.return, renderLanes);
+```
+
+上面的 scheduleWorkOnParentPath 方法的作用是从 context consumer 向上遍历,依次为祖先的 FiberNode.childLanes 附加 renderLanes。
+
+因此,我们来总结一下,当 context value 发生变化的时候,beginWork 从 Provider 开始向下遍历,找到 context consumer 之后为当前的 FiberNode 标记一个 renderLanes,再从 context consumer 向上遍历,为祖先的 FiberNode.childLanes 标记一个 renderLanes。
+
+注意无论是向下遍历寻找 context consumer 还是从 context consumer 向上遍历修改 childLanes,这个都发生在 Provider 的 beginWork 中。
+
+因此,上述的流程完成后,虽然 Provider 命中了 bailout 策略,但是由于流程中 childLanes 已经被修改了,因此就不会命中“跳过整颗子树的beginWork”的逻辑,相关代码如下:
+
+```js
+function bailoutOnAlreadyFinishedWork(
+ current,
+ workInProgress,
+ renderLanes
+){
+ //...
+
+ // 不会命中该逻辑
+ if(!includesSomeLane(renderLanes, workInProgress.childLanes)){
+ // 整颗子树都命中 bailout 策略
+ return null;
+ }
+
+ //...
+}
+```
+
+通过上面的代码我们可以看出,“如果子树深处存在 context consumer”,即使子树的根 FiberNode 命中了 bailout 策略,由于存在 childLanes 的标记,因此不会完全跳过子树的 beginWork 过程,所以新版的 ContextAPI 能实现更新,解决了旧版 ContextAPI 无法更新的问题。
+
+
+
+## 真题解答
+
+> 题目:为什么要重构 ContextAPI,旧版的 ContextAPI 有什么问题?
+>
+> 参考答案:
+>
+> 旧版的 ContextAPI 存在一些缺陷。
+>
+> context 中的数据是保存在栈里面的。在 beginWork 中,context 会不断的入栈,所以 context Consumer 可以通过 context 栈向上找到对应的 context value,在 completeWork 中,context 会不断出栈。
+>
+> 这种入栈出栈的模式刚好可以用来应对 reconcile 流程以及一般的 bailout 策略。
+>
+> 但是,对于“跳过整颗子树的 beginWork”这种程度的 bailout 策略,被跳过的子树就不会再经历 context 的入栈和出栈过程,因此在使用旧的ContextAPI时,即使 context里面的数据发生了变化,但只要子树命中了bailout策略被跳过了,那么子树中的 Consumer 就不会响应更新。
+>
+> 新版的 ContextAPI 当 context value 发生变化时,beginWork 会从 Provider 立刻向下开启一次深度优先遍历,目的是寻找 Context Consumer。Context Consumer 找到后,会为其对应的 FiberNode.lanes 附加 renderLanes,再从 context consumer 向上遍历,为祖先的 FiberNode.childLanes 标记一个 renderLanes。因此如果子树深处存在 Context Consumer,即使子树的根 FiberNode 命中 bailout 策略,也不会完全跳过子树的 beginWork 流程 。
\ No newline at end of file
diff --git a/就业篇/02. 第二章/2-28. 性能优化对日常开发启示/性能优化对日常开发启示.md b/就业篇/02. 第二章/2-28. 性能优化对日常开发启示/性能优化对日常开发启示.md
new file mode 100644
index 0000000..445fec5
--- /dev/null
+++ b/就业篇/02. 第二章/2-28. 性能优化对日常开发启示/性能优化对日常开发启示.md
@@ -0,0 +1,167 @@
+# 性能优化对日常开发启示
+
+在前面我们已经学习了 React 中内置的性能优化相关策略,包括:
+
+- eagerState 策略
+- bailout 策略
+
+其中 eagerState 策略需要满足的条件是比较苛刻的,开发时不必强求。但是作为 React 开发者,应该追求写出满足 bailout 策略的组件。
+
+当我们聊到性能优化的时候,常见的想法就是使用性能优化相关的 API,但是当我们深入学习 bailout 策略的原理后,我们就会知道,即使不使用性能优化 API,只要满足一定条件,也能命中 bailout 策略。
+
+我们来看一个例子:
+
+```jsx
+import React, { useState } from "react";
+
+function ExpensiveCom() {
+ const now = performance.now();
+ while (performance.now() - now < 200) {}
+ return 耗时的组件
;
+}
+
+function App() {
+ const [num, updateNum] = useState(0);
+
+ return (
+ <>
+ updateNum(e.target.value)} />
+ num is {num}
+
+
+ );
+}
+
+export default App;
+```
+
+在上面的例子中,App 是挂载的组件,由于 ExpensiveCom 在 render 时会执行耗时的操作,因此在 input 输入框中输入内容时,会发生明显的卡顿。
+
+究其原因,是因为 ExpensiveCom 组件并没有命中 bailout 策略。
+
+那么为什么该组件没有命中 bailout 策略呢?
+
+在 App 组件中,会触发 state 更新(num 变化),所以 App 是肯定不会命中 bailout 策略的,而在 ExpensiveCom 中判断是否能够命中 bailout 策略时,有一条是 oldProps === newProps,由于 App 每次都是重新 render 的,所以子组件的这个条件并不会满足。
+
+
+
+为了使 ExpensiveCom 命中 bailout 策略,咱们就需要从 App 入手,将 num 与 num 相关的视图部分进行一个分离,形成一个独立的组件,如下:
+
+```jsx
+import React, { useState } from "react";
+
+function ExpensiveCom() {
+ const now = performance.now();
+ while (performance.now() - now < 200) {}
+ return 耗时的组件
;
+}
+
+function Input() {
+ const [num, updateNum] = useState(0);
+
+ return (
+
+
updateNum(e.target.value)} />
+
num is {num}
+
耗时的组件
;
+}
+
+
+function App() {
+ const [num, updateNum] = useState(0);
+
+ return (
+
+
updateNum(e.target.value)} />
+
num is {num}
+
+
耗时的组件
;
+}
+
+function Counter({ children }) {
+ const [num, updateNum] = useState(0);
+ return (
+
+
updateNum(e.target.value)} />
+
num is {num}
+ {children}
+